This simple method might lead to too many cache misses among all processors. Maybe we can broadcast the new cache value instead of just "invalidation message" to all processors' local cache and update them. This way won't trigger cache miss on other processors.
msfernan
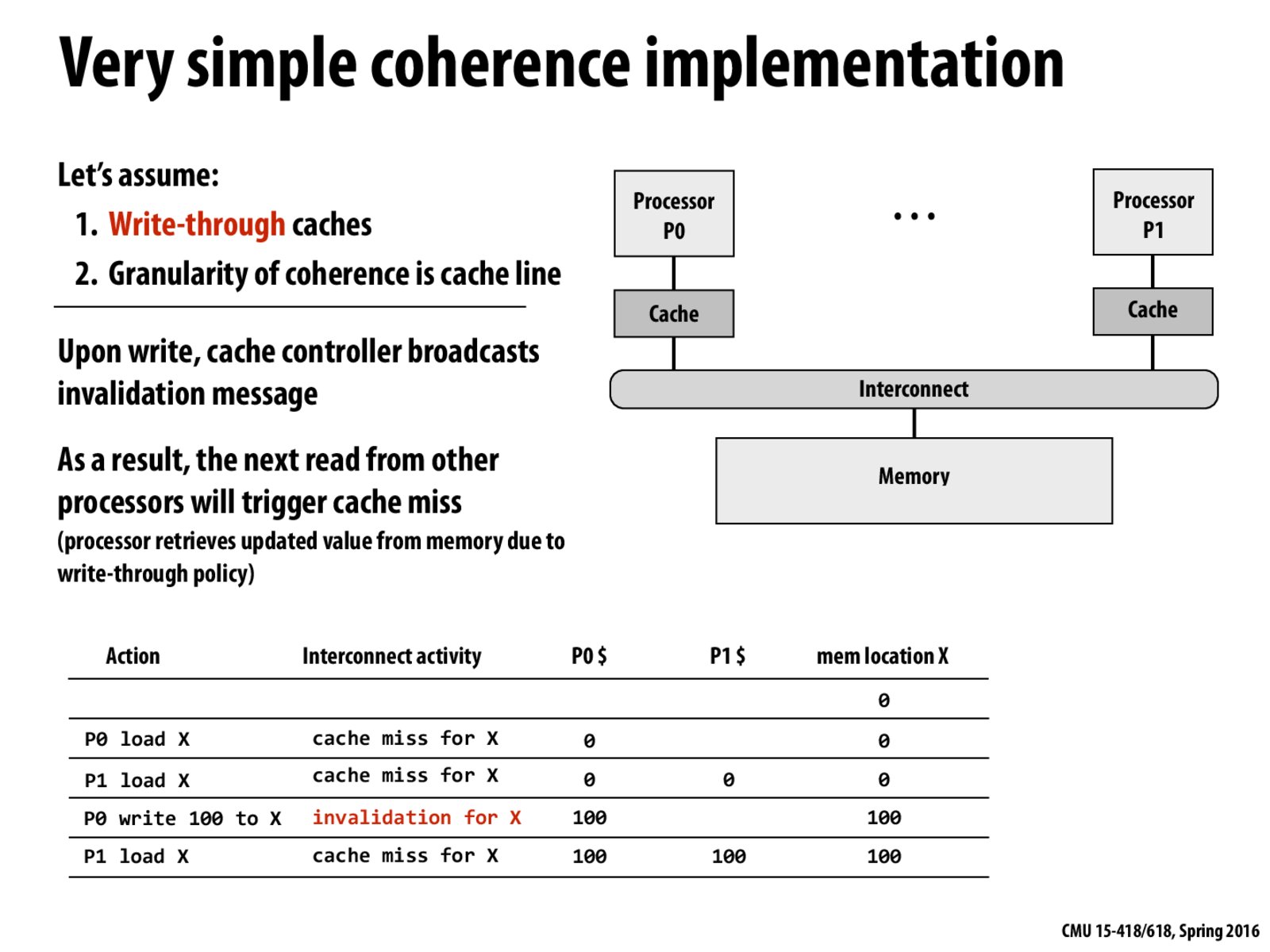
P0 loads X : cache miss so X is loaded from memory.
P1 loads X : cache miss so X is loaded from memory.
P1 writes 100: P1's copy of X is invalidated. X is updated in memory instantaneously as this is a write through cache. If it were a write back cache, memory would not have been updated. Hence we use a write through policy.
P1 loads X: X is loaded from memory.
msfernan
Granularity of coherence depends on size of cache line. The smaller the cache line, the smaller the amount of memory that needs to be updated/invalidated. Hence the granularity of coherence depends on the cache line. In this case the granularity of coherence is the number of bytes of X.
This simple method might lead to too many cache misses among all processors. Maybe we can broadcast the new cache value instead of just "invalidation message" to all processors' local cache and update them. This way won't trigger cache miss on other processors.
P0 loads X : cache miss so X is loaded from memory.
P1 loads X : cache miss so X is loaded from memory.
P1 writes 100: P1's copy of X is invalidated. X is updated in memory instantaneously as this is a write through cache. If it were a write back cache, memory would not have been updated. Hence we use a write through policy.
P1 loads X: X is loaded from memory.
Granularity of coherence depends on size of cache line. The smaller the cache line, the smaller the amount of memory that needs to be updated/invalidated. Hence the granularity of coherence depends on the cache line. In this case the granularity of coherence is the number of bytes of X.