Note we can run into a bad situation if two processors are competing to write to the same cache line.
For example, say processor A and B both want to write to line L. Processor A issues a BusRx. It now has L in the exclusive state in its cache. Now BEFORE processor A gets to actually write to line L, it snoops a BusRdx form processor B. According to the rules of the protocol, Cache of processor A must invalidate L. Now processor B's cache has line L in the exclusive state. But yet again, BEFORE processor B gets to actually write to line L, it snoops a BusRdx from A because A is still trying to write to L! And this goes on and on and neither processor can progress in their instruction streams.
Question: How can we ensure that forward progress is being made in such situations?
CC
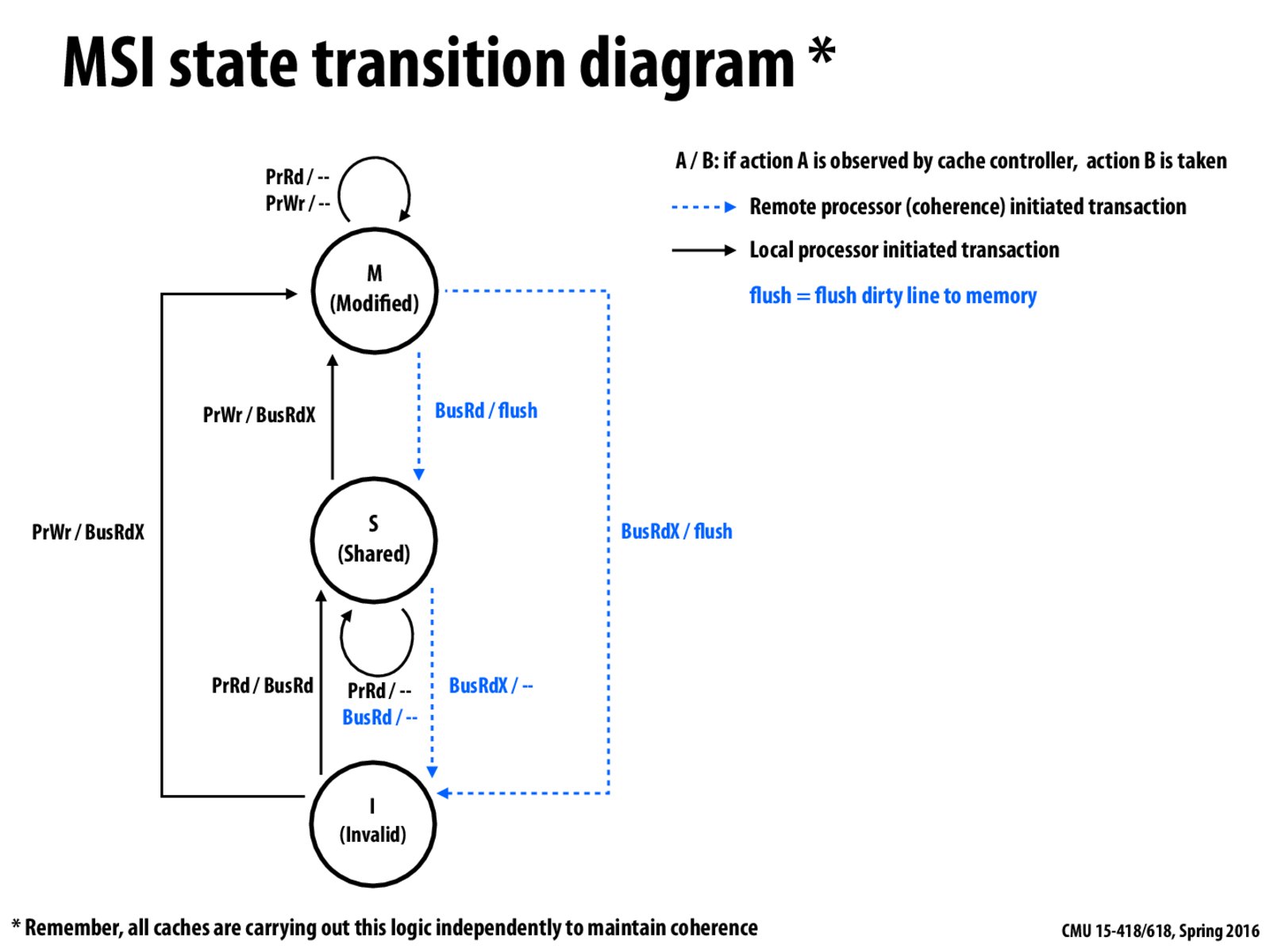
In the state diagram, when a cache in M state receives BusRd, it flushes its data and drops to state S. Why is it necessary to drop to S? Can the cache stays in M and just flushes data upon BusRd, and only drop to another state when hearing BusRdX?
Fantasy
@CC
I don't think so. At least it cannot work without changing other links in the state machine.
Suppose a cache in state M stays in M and just flushes data upon BusRd. The cache that issued BusRd will move to state I. According to the state machine, write in state M will not broadcast and read in state S will not broadcast. The cache in M can change its value arbitrarily and the read in state S will not be notified and thus get stale value.
CC
@Fantasy I see. I was ignoring the requirement that while one cache is in M others have to be in I. I was thinking there can be other caches in S while one is in M. That would be more like the E state in MESI I suppose.
Khryl
@karima, should we use a lock to avoid competing writes? It seems reasonable to do so because one write will erase the content of the other write, so there must be some sequential dependency to make these two operations meaningful.
zvonryan
@Khryl but we do not write write locks on cache since cache is a microarchitecture detail which we cannot actually control through code, right? The snooping operation here should not preempt the ongoing instructions or the situations described by karima might happen.
karima
@Khryl and @zvonryan, yes I'm looking for a hardware solution here.
The solution is actually pretty simple. Also note that having the line in the exclusive state is essentially like having a lock on the cache line - as long as processor A has it in the exclusive state in its cache, no other processor can write to that line.
@zvonryan I think you've got the right idea with "The snooping operation here should not preempt the ongoing instructions" but could you clarify your answer to make it super explicit for other readers? What exactly does processor A's cache do when it 1) has L in the exclusive state, has not written yet to line L and 2) snoops a BUSRDX from processor B's cache?
zvonryan
@karima Since having the line in the exclusive state is like having a lock on the cache line, processor A would continue to write to L if its cache 1) has L in the exclusive state, has not written yet to line L and 2) snoops a BUSRDX from processor B's cache. The BUSRDX from processor B will be received but put on hold until the write in A's cache to L is done. Processor B might continue to broadcast BUSRDX until the corresponding actions are taken. This might be implemented by something like a toggle flip-flop in here.
mrrobot
@karima Can we use some sort of exponential back-off scheme where if a processor got denied exclusive state it doesn't immediately retry again but after some duration which increases with each collision?
karima
@zvonryan nice! That's the solution I had in mind.
@mrrobot, talking about exponential back-off makes more sense in the context of determining who gets access to the bus, not what happens once a processor has obtained access to the bus.
At the point in time when processor B has sent its BUSRDX and processor A snoops it, processor B has already won access to the bus and sent its message (the BUSRDX) across. It's now just waiting for a response from processor A, which it could obtain as @zvonryan suggested, after processor A is done writing to line L in its own cache.
However, since we're on the topic of exponential back-off, let's talk about how sending all these messages, BUSRD, BUSRDX, etc actually gets implemented in hardware! All the caches are snooping requests from other caches as they zoom by on a bus that connects them all while also sending their own requests onto the bus.
Only one cache can be sending a request on the bus at a single moment in time, by definition of a bus. So we can obviously run into the situation where multiple processors want access to the bus at the same time. In this case, using exponential back-off is a potential solution. Round-robin is also another option. Assigning a priority to different caches is also possible, for example, if the system knows that one particular cache is servicing a processor that's running a real-time application, it might give that cache a higher priority such that it wins the bus most/all of the time it asks for it.
sasthana
@karima My understanding about BusRdX is that it is a way for a processor to tell that it wants to write (write-back) but before doing that it needs to allocate the cache line in its local cache. Once the cache line is allocated it can proceed to write the data. Therefore it is essentially an atomic operation. It should not matter if it snoops B's BusRdX in between it allocating the cache line and writing the data.
karima
@sasthana that's not quite right.
One thing we didn't talk about yet in class is how the memory controller fits into all of this.
The memory controller is also sitting by the bus and snooping these requests as they come along. When a cache issues a BUSRDX for line L, it does not have the line L in its cache. The memory controller sees this request, and goes to fetch it from memory.
It takes hundreds of cycles to get data back from main memory so if you make the sequence of operations of 1) BUSRDX and 2) write to the line loaded into cache as a result of the BUSRDX atomic, you're severely limiting the parallelism of your system. This is because as the cache is waiting for the data to arrive from memory, we would like it to be able to keep snooping and respond appropriately to the requests of other caches.
For example, if it has another line M in the shared state and it snoops a BUSRDX from another cache B, cache A should be able to invalidate line M while waiting for line L so that cache B's processor can continue to do whatever it needs to do.
We only want cache A to make sure it doesn't respond to memory requests from other caches specifically regarding line L while its in limbo between having sent out the BUSRDX and actually getting the line from memory and writing to it.
xingdaz
@karima, Say P1 is in Invalid, P2 is in Modified. P1 cache controller was told to read, i.e. PrRd, then it announces BusRd. P2 cache controller hears the BusRd, flushes the line. Then P1 actually makes the state transition and then reads it. However, this is the well behaving scenario. What is stopping P1 from making the transition and reading stale data before P2 finishes flushing? How is the order of actions from observation -> announcement/action -> state transition ensured?
karima
@xingdaz, good question!
In a later lecture you will learn how to implement a cache coherent memory system. This lecture was to teach you the abstraction. At a high level, the memory controller is also snooping all memory requests as they go by. Connecting all the caches and the memory controller and main memory is a data bus, request bus, and also a "shared" line, a "dirty" line, and a "snoop-valid" line see this slide.
When a cache gets access to the request bus and sends its request, all other caches will snoop the request, and indicate whether or not they have the line requested in the shared or dirty state by sending a bit along the shared/dirty lines. Once the cache has responded it sends a bit along the "snoop-valid" line to indicate that it has responded.
The memory controller waits until it knows that all caches have had a chance to respond by checking the "snoop-valid" line. At this point, it will know whether or not any cache has this line in the modified state or if they all have it in either the shared or invalid state. Based on this, it knows what following action to take. It must either 1) wait for the cache with the line in the modified state to flush the data out to main memory BEFORE fetching that line from main memory and sending it to the requesting cache or 2) go ahead and fetch that line from main memory and send it over the the requesting cache.
If you want to get more into the nitty gritty details here :), the memory controller actually maintains a request table where it stores outstanding requests so that it can service other requests while it waits for the appropriate data transfers to occur (flushes from caches and/or data from main memory) from pending requests. It is here in this request table where the memory controller can store state such as "This particular BUSRD for line L depends on a write back from one of the caches to occur first before I can service it by going ahead and requesting line L from main memory.
Note we can run into a bad situation if two processors are competing to write to the same cache line.
For example, say processor A and B both want to write to line L. Processor A issues a BusRx. It now has L in the exclusive state in its cache. Now BEFORE processor A gets to actually write to line L, it snoops a BusRdx form processor B. According to the rules of the protocol, Cache of processor A must invalidate L. Now processor B's cache has line L in the exclusive state. But yet again, BEFORE processor B gets to actually write to line L, it snoops a BusRdx from A because A is still trying to write to L! And this goes on and on and neither processor can progress in their instruction streams.
Question: How can we ensure that forward progress is being made in such situations?
In the state diagram, when a cache in M state receives BusRd, it flushes its data and drops to state S. Why is it necessary to drop to S? Can the cache stays in M and just flushes data upon BusRd, and only drop to another state when hearing BusRdX?
@CC I don't think so. At least it cannot work without changing other links in the state machine.
Suppose a cache in state M stays in M and just flushes data upon BusRd. The cache that issued BusRd will move to state I. According to the state machine, write in state M will not broadcast and read in state S will not broadcast. The cache in M can change its value arbitrarily and the read in state S will not be notified and thus get stale value.
@Fantasy I see. I was ignoring the requirement that while one cache is in M others have to be in I. I was thinking there can be other caches in S while one is in M. That would be more like the E state in MESI I suppose.
@karima, should we use a lock to avoid competing writes? It seems reasonable to do so because one write will erase the content of the other write, so there must be some sequential dependency to make these two operations meaningful.
@Khryl but we do not write write locks on cache since cache is a microarchitecture detail which we cannot actually control through code, right? The snooping operation here should not preempt the ongoing instructions or the situations described by karima might happen.
@Khryl and @zvonryan, yes I'm looking for a hardware solution here.
The solution is actually pretty simple. Also note that having the line in the exclusive state is essentially like having a lock on the cache line - as long as processor A has it in the exclusive state in its cache, no other processor can write to that line.
@zvonryan I think you've got the right idea with "The snooping operation here should not preempt the ongoing instructions" but could you clarify your answer to make it super explicit for other readers? What exactly does processor A's cache do when it 1) has L in the exclusive state, has not written yet to line L and 2) snoops a BUSRDX from processor B's cache?
@karima Since having the line in the exclusive state is like having a lock on the cache line, processor A would continue to write to L if its cache 1) has L in the exclusive state, has not written yet to line L and 2) snoops a BUSRDX from processor B's cache. The BUSRDX from processor B will be received but put on hold until the write in A's cache to L is done. Processor B might continue to broadcast BUSRDX until the corresponding actions are taken. This might be implemented by something like a toggle flip-flop in here.
@karima Can we use some sort of exponential back-off scheme where if a processor got denied exclusive state it doesn't immediately retry again but after some duration which increases with each collision?
@zvonryan nice! That's the solution I had in mind.
@mrrobot, talking about exponential back-off makes more sense in the context of determining who gets access to the bus, not what happens once a processor has obtained access to the bus.
At the point in time when processor B has sent its BUSRDX and processor A snoops it, processor B has already won access to the bus and sent its message (the BUSRDX) across. It's now just waiting for a response from processor A, which it could obtain as @zvonryan suggested, after processor A is done writing to line L in its own cache.
However, since we're on the topic of exponential back-off, let's talk about how sending all these messages, BUSRD, BUSRDX, etc actually gets implemented in hardware! All the caches are snooping requests from other caches as they zoom by on a bus that connects them all while also sending their own requests onto the bus.
Only one cache can be sending a request on the bus at a single moment in time, by definition of a bus. So we can obviously run into the situation where multiple processors want access to the bus at the same time. In this case, using exponential back-off is a potential solution. Round-robin is also another option. Assigning a priority to different caches is also possible, for example, if the system knows that one particular cache is servicing a processor that's running a real-time application, it might give that cache a higher priority such that it wins the bus most/all of the time it asks for it.
@karima My understanding about BusRdX is that it is a way for a processor to tell that it wants to write (write-back) but before doing that it needs to allocate the cache line in its local cache. Once the cache line is allocated it can proceed to write the data. Therefore it is essentially an atomic operation. It should not matter if it snoops B's BusRdX in between it allocating the cache line and writing the data.
@sasthana that's not quite right.
One thing we didn't talk about yet in class is how the memory controller fits into all of this.
The memory controller is also sitting by the bus and snooping these requests as they come along. When a cache issues a BUSRDX for line L, it does not have the line L in its cache. The memory controller sees this request, and goes to fetch it from memory.
It takes hundreds of cycles to get data back from main memory so if you make the sequence of operations of 1) BUSRDX and 2) write to the line loaded into cache as a result of the BUSRDX atomic, you're severely limiting the parallelism of your system. This is because as the cache is waiting for the data to arrive from memory, we would like it to be able to keep snooping and respond appropriately to the requests of other caches.
For example, if it has another line M in the shared state and it snoops a BUSRDX from another cache B, cache A should be able to invalidate line M while waiting for line L so that cache B's processor can continue to do whatever it needs to do.
We only want cache A to make sure it doesn't respond to memory requests from other caches specifically regarding line L while its in limbo between having sent out the BUSRDX and actually getting the line from memory and writing to it.
@karima, Say P1 is in Invalid, P2 is in Modified. P1 cache controller was told to read, i.e. PrRd, then it announces BusRd. P2 cache controller hears the BusRd, flushes the line. Then P1 actually makes the state transition and then reads it. However, this is the well behaving scenario. What is stopping P1 from making the transition and reading stale data before P2 finishes flushing? How is the order of actions from observation -> announcement/action -> state transition ensured?
@xingdaz, good question!
In a later lecture you will learn how to implement a cache coherent memory system. This lecture was to teach you the abstraction. At a high level, the memory controller is also snooping all memory requests as they go by. Connecting all the caches and the memory controller and main memory is a data bus, request bus, and also a "shared" line, a "dirty" line, and a "snoop-valid" line see this slide.
When a cache gets access to the request bus and sends its request, all other caches will snoop the request, and indicate whether or not they have the line requested in the shared or dirty state by sending a bit along the shared/dirty lines. Once the cache has responded it sends a bit along the "snoop-valid" line to indicate that it has responded.
The memory controller waits until it knows that all caches have had a chance to respond by checking the "snoop-valid" line. At this point, it will know whether or not any cache has this line in the modified state or if they all have it in either the shared or invalid state. Based on this, it knows what following action to take. It must either 1) wait for the cache with the line in the modified state to flush the data out to main memory BEFORE fetching that line from main memory and sending it to the requesting cache or 2) go ahead and fetch that line from main memory and send it over the the requesting cache.
If you want to get more into the nitty gritty details here :), the memory controller actually maintains a request table where it stores outstanding requests so that it can service other requests while it waits for the appropriate data transfers to occur (flushes from caches and/or data from main memory) from pending requests. It is here in this request table where the memory controller can store state such as "This particular BUSRD for line L depends on a write back from one of the caches to occur first before I can service it by going ahead and requesting line L from main memory.