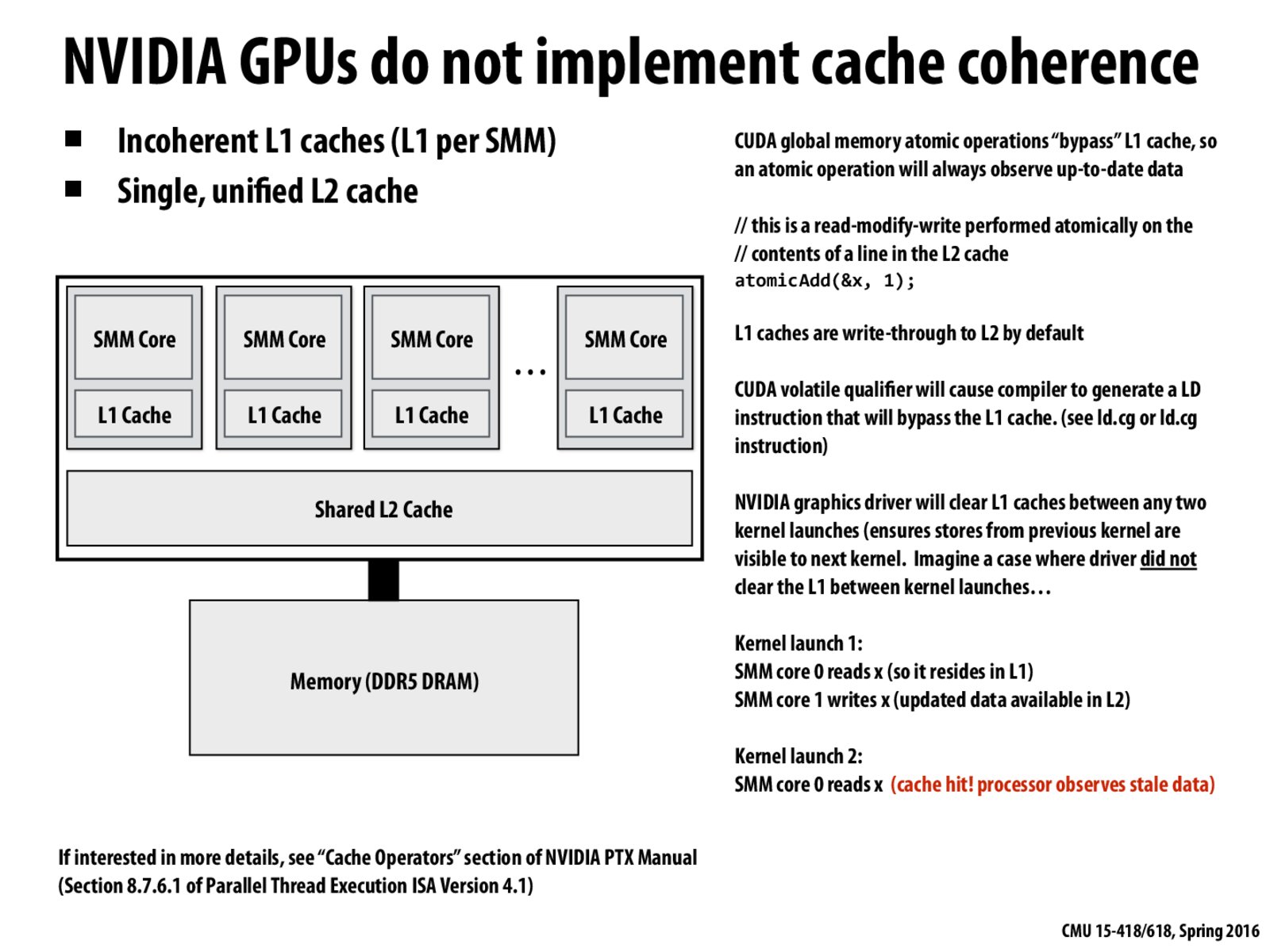
How do you ensure correctness of kernel code if a GPU does not implement cache coherence?
temmie
@BensonQiu From the slide, it seems CUDA ensures correctness by declining to use the L1 caches on each core (for which cache coherence would be an issue, since they could each keep their own copy of the same value without communicating) and instead only using the shared L2 cache (for which coherence shouldn't be an issue--or at least, doesn't need to be specifically implemented--since all cores are using the same cache and thus can't keep different values for the same variable).
Kernel code in general must just be designed so that it doesn't rely on cache coherence, perhaps using the above approach or ensuring that different cores never try to change the same variable in ways that would conflict.
[EDIT: following is probably incorrect; see following comments]
I think there's also an error on the slide: "ensures stores from previous kernel are not visible to next kernel"
The slide itself points out how it would pose problems for kernel correctness if previously cached values were visible by the next kernel.
haboric
@temmie I understand your point on the "typo". But I believe the slide is saying ensuring stores in L2 cache from previous kernel are visible to next kernel, not blind to the value in L2 cache due to presence of stale value in L1.
temmie
@haboric Ohhh, yeah, that seems right--so "stores" refers to the written data, not the data that was read, cached in L1, then invalidated.
kayvonf
Unless I'm misunderstanding @temmie, @haboric, the slide is correct. By flushing L1 caches after the end of a kernel launch, the GPU ensures that the results of stores will be propagated to the L2, and therefore the results of stores will observed by future loads on any other core.
How do you ensure correctness of kernel code if a GPU does not implement cache coherence?
@BensonQiu From the slide, it seems CUDA ensures correctness by declining to use the L1 caches on each core (for which cache coherence would be an issue, since they could each keep their own copy of the same value without communicating) and instead only using the shared L2 cache (for which coherence shouldn't be an issue--or at least, doesn't need to be specifically implemented--since all cores are using the same cache and thus can't keep different values for the same variable).
Kernel code in general must just be designed so that it doesn't rely on cache coherence, perhaps using the above approach or ensuring that different cores never try to change the same variable in ways that would conflict.
[EDIT: following is probably incorrect; see following comments]
I think there's also an error on the slide: "ensures stores from previous kernel are not visible to next kernel"
The slide itself points out how it would pose problems for kernel correctness if previously cached values were visible by the next kernel.
@temmie I understand your point on the "typo". But I believe the slide is saying ensuring stores in L2 cache from previous kernel are visible to next kernel, not blind to the value in L2 cache due to presence of stale value in L1.
@haboric Ohhh, yeah, that seems right--so "stores" refers to the written data, not the data that was read, cached in L1, then invalidated.
Unless I'm misunderstanding @temmie, @haboric, the slide is correct. By flushing L1 caches after the end of a kernel launch, the GPU ensures that the results of stores will be propagated to the L2, and therefore the results of stores will observed by future loads on any other core.