The relevant slides from two lectures ago are here.
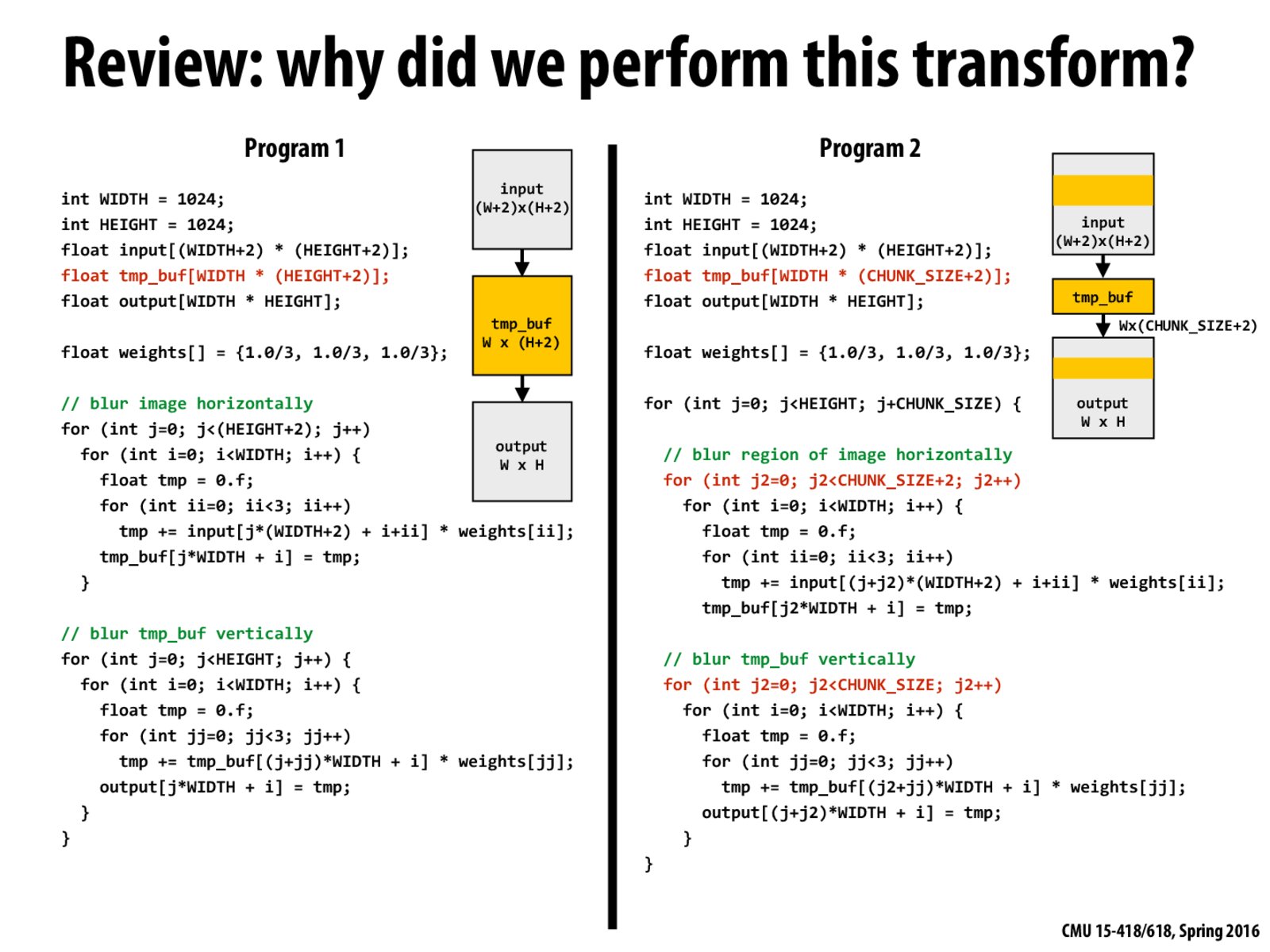
We make the buffer on program 2 in order to allow the buffer to fit into cache. We load some data from the input and do as much work as possible with it before moving on.
Khryl
The CHUNK_SIZE needs to be carefully selected here. Because each chunk has a computation overhead of two rows. So If the CHUNK_SIZE is too small, the computation overhead offsets the benefits from cache locality. At the same time, the CHUNK_SIZE need to be small enough to fit in cache.
stl
In program 1, because the buffer is large, it doesn't fit in cache, and so tmp_buf accesses are loads from memory. To fix that, program 2 is written so the input is processed in chunks such that tmp_buf is able to stay in cache which allows the program to incur less memory traffic. This transformation along with the one on the previous slide uses the idea of having the intermediate result consumed almost immediately. This transformation was made to exploit L1 cache locality whereas in the program on the previous slide, that transformation was to exploit register locality.
rds
In both examples (from the previous slide and this one), the programs were changed to consume intermediate results, either from registers or from the cache, immediately. In both cases, this optimization helps improve performance because the program is bandwidth-bound.
makingthingsfast
Professor Kayvon also mentioned the idea of over computing which could occur in the code to the right. This is because while we do utilize locality and save memory space by processing a line entirely, we miss out on some of the intermediate results which may be computed multiple times for each different output (as oppose to just once).
efficiens
Is CHUNK_SIZE always equal to exactly the size of the cache or a little smaller than that?
captainFlint
I think CHUNK_SIZE only needs to be small enough to fit in the cache, not necessarily as exactly equal to size of the cache. However, if its too small, the benefits of locality might be overcome by the increase in computation overhead.
The relevant slides from two lectures ago are here.
We make the buffer on program 2 in order to allow the buffer to fit into cache. We load some data from the input and do as much work as possible with it before moving on.
The CHUNK_SIZE needs to be carefully selected here. Because each chunk has a computation overhead of two rows. So If the CHUNK_SIZE is too small, the computation overhead offsets the benefits from cache locality. At the same time, the CHUNK_SIZE need to be small enough to fit in cache.
In program 1, because the buffer is large, it doesn't fit in cache, and so tmp_buf accesses are loads from memory. To fix that, program 2 is written so the input is processed in chunks such that tmp_buf is able to stay in cache which allows the program to incur less memory traffic. This transformation along with the one on the previous slide uses the idea of having the intermediate result consumed almost immediately. This transformation was made to exploit L1 cache locality whereas in the program on the previous slide, that transformation was to exploit register locality.
In both examples (from the previous slide and this one), the programs were changed to consume intermediate results, either from registers or from the cache, immediately. In both cases, this optimization helps improve performance because the program is bandwidth-bound.
Professor Kayvon also mentioned the idea of over computing which could occur in the code to the right. This is because while we do utilize locality and save memory space by processing a line entirely, we miss out on some of the intermediate results which may be computed multiple times for each different output (as oppose to just once).
Is CHUNK_SIZE always equal to exactly the size of the cache or a little smaller than that?
I think CHUNK_SIZE only needs to be small enough to fit in the cache, not necessarily as exactly equal to size of the cache. However, if its too small, the benefits of locality might be overcome by the increase in computation overhead.