As is shown in previous slide, each node is assigned a key to do the reduction and it achieves parallelism across keys.
However, what if the number of keys is significantly smaller than number of nodes? (As in this slide, suppose there are only 4 keys but 1000 nodes). Do we still use only 4 nodes to reduce or does MapReduce have other strategies to improve performance? (This is a general purpose MapReduce framework so we do not know other properties of reduce function.)
thomasts
I guess no. It was said in lecture that the reduces need to be run serially on a particular key. There is no assumption that the reduction function is associative, so there's not much that can be done to increase performance on a single key.
zvonryan
The relationship between the (expected) number of keys and reducers is an important thing to tune. For example if the number of keys are very small to the number reducers might result in a crazy amount of disk I/O in certain reducers if the number of values are a lot. @Fantasy you may wanna look at this thread and this answer in quora.
efficiens
@zvonryan thanks for the link to the quora post! Really cleared up the concept.
jrgallag
In the case where there are few keys, but a lot of data, might it make sense to distribute the keys so we have many nodes per key? That way, rather than aggregating all data for one key in a single node, we can just pass along the intermediate result given by reduce, minimizing communication cost. We will still need to run the reduce sequentially though.
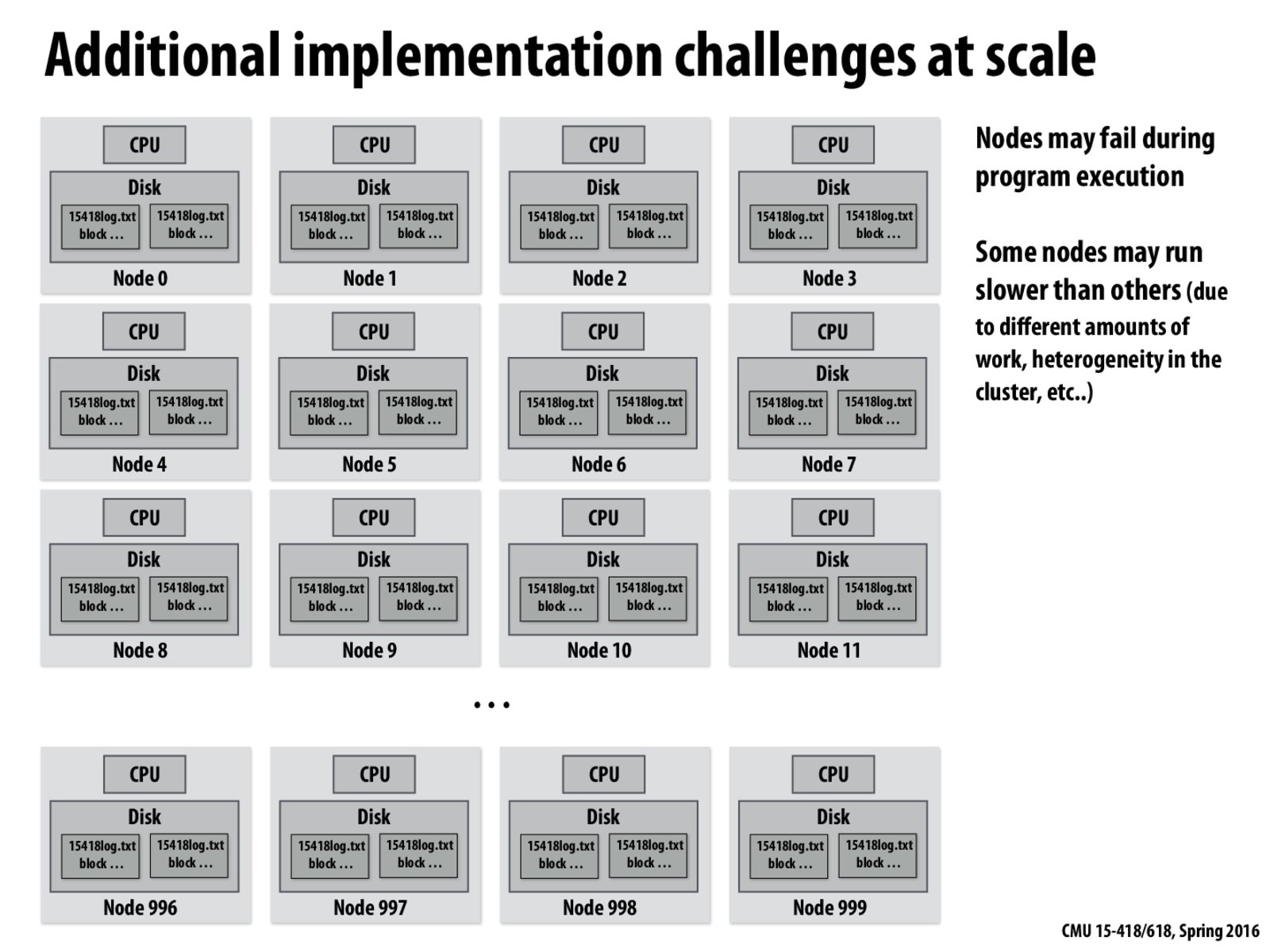
As is shown in previous slide, each node is assigned a key to do the reduction and it achieves parallelism across keys. However, what if the number of keys is significantly smaller than number of nodes? (As in this slide, suppose there are only 4 keys but 1000 nodes). Do we still use only 4 nodes to reduce or does MapReduce have other strategies to improve performance? (This is a general purpose MapReduce framework so we do not know other properties of reduce function.)
I guess no. It was said in lecture that the reduces need to be run serially on a particular key. There is no assumption that the reduction function is associative, so there's not much that can be done to increase performance on a single key.
The relationship between the (expected) number of keys and reducers is an important thing to tune. For example if the number of keys are very small to the number reducers might result in a crazy amount of disk I/O in certain reducers if the number of values are a lot. @Fantasy you may wanna look at this thread and this answer in quora.
@zvonryan thanks for the link to the quora post! Really cleared up the concept.
In the case where there are few keys, but a lot of data, might it make sense to distribute the keys so we have many nodes per key? That way, rather than aggregating all data for one key in a single node, we can just pass along the intermediate result given by reduce, minimizing communication cost. We will still need to run the reduce sequentially though.