RDD is not like array. Arrays are solid chunks of memory for data. However, for RDD we don't allocate memory for each of them; a lot of intermediate memory can be saved in a lineage. For example, here lines is immediately consumed by lower and no longer used, so in RDD we don't allocate memory for both of them. Rather, we only need to record the dependency, and allocate when necessary.
kayvonf
Question: Describe the abstraction presented by an RDD. Also, how are RDD's implemented by the Spark runtime?
Another question: What does it mean for an RDD to be materialized?)
monkeyking
As misaka-10032 said, we don't allocate memory for an RDD. So I think an RDD to be materialized means we allocate memory for it. That is, we store it into memory (.persist()) or even store it into durable storage (.persist(RELIABLE)).
xiaoguaz
@monkeyking I think persist() is not a method to materialize RDD, instead, it means spark will store its answer once it is calculated (just like cache()). As for materializing a RDD, I think it means to do the action on RDDs, such as count, collect, reduce and so on. Spark is lazy so it will do nothing until it meets these actions to materializing RDDs.
418_touhenying
Does materialized mean something like unpacked so that the data is ready for use?
althalus
From what I read, RDD is a fault-tolerant collection of elements that can be operated on in parallel. They are created by calling the parallelize() function on a dataset which copies the elements in the dataset to form a distributed dataset that can be operated on in parallel.
Also, I think that an RDD can materialized in memory by caching it since the cache remembers the RDD's lineage.
PandaX
RDD is like the 'formula' for generating data. We combine several RDDs to produce the result. The intermediate memory is saved.
Lotusword
RDDs do not need to be materialized at all times, as an RDD has enough information about how it was derived from other datasets(its lineage) to compute its partitions from data in stable storage.
Araina
I think persist() is a method to materialize RDD. However, since Spark is lazy, we need to do some action to this RDD after we use persist() on it.
eg. var materialized = rdd.persist(); materialized.count();
After these two steps, this rdd is materialized.
momoda
When the RDD is persist(), if RDD fits into memory, then it will be stored in memory only, otherwise, stores in memory and disk.
yangwu
operations like cache(), persist() only mark RDD but not materialize them; on the other hand, operations like count() materialize RDD;
and I think "materialize" RDD means execute RDD dependencies and do the actual calculations
rajul
Sparks runtime does lazy evaluation so until an action is taken the RDD is not materialized.
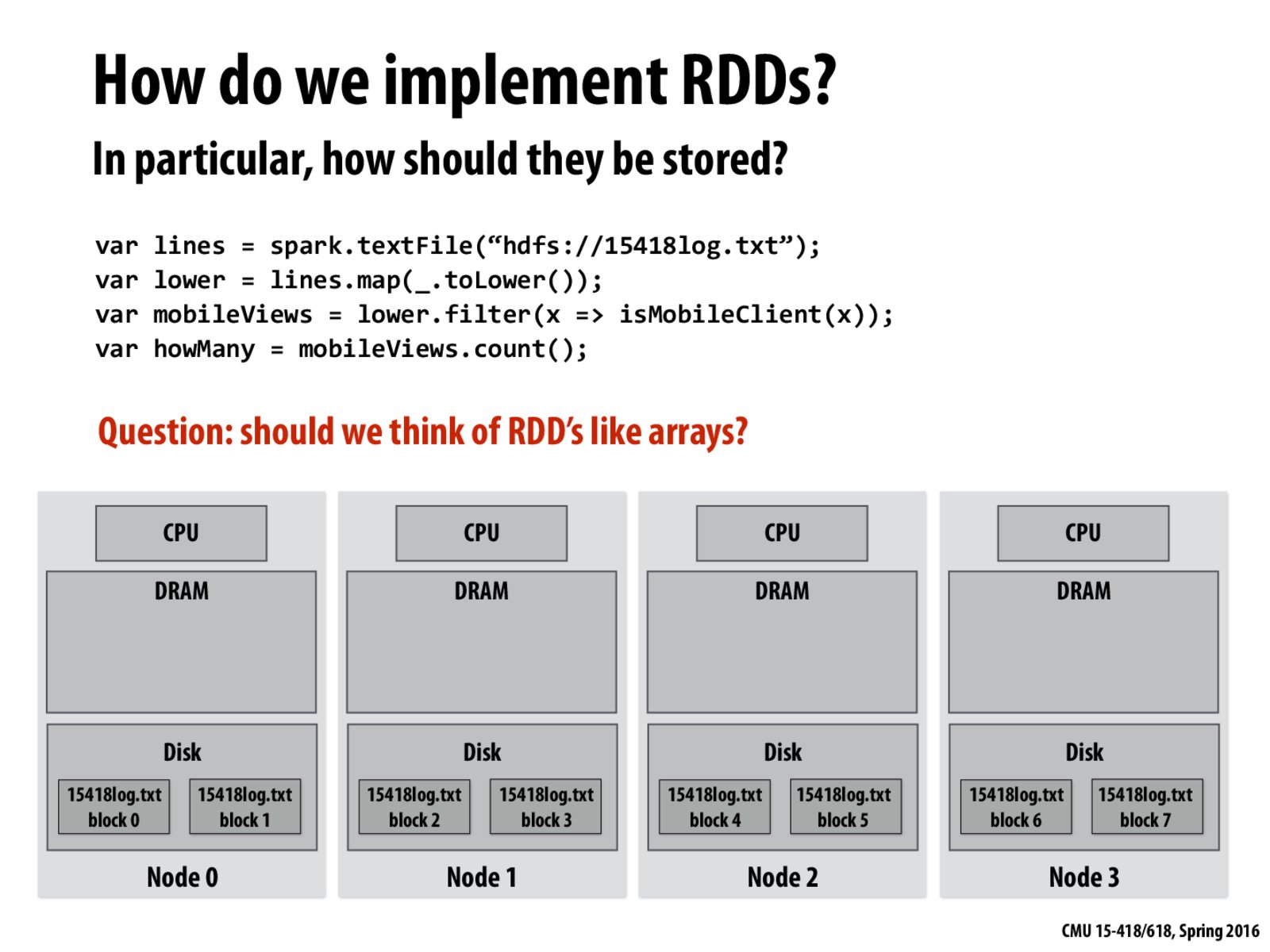
RDD is not like array. Arrays are solid chunks of memory for data. However, for RDD we don't allocate memory for each of them; a lot of intermediate memory can be saved in a lineage. For example, here
linesis immediately consumed bylowerand no longer used, so in RDD we don't allocate memory for both of them. Rather, we only need to record the dependency, and allocate when necessary.Question: Describe the abstraction presented by an RDD. Also, how are RDD's implemented by the Spark runtime?
Another question: What does it mean for an RDD to be materialized?)
As misaka-10032 said, we don't allocate memory for an RDD. So I think an RDD to be materialized means we allocate memory for it. That is, we store it into memory (.persist()) or even store it into durable storage (.persist(RELIABLE)).
@monkeyking I think
persist()is not a method to materialize RDD, instead, it means spark will store its answer once it is calculated (just likecache()). As for materializing a RDD, I think it means to do the action on RDDs, such ascount,collect,reduceand so on. Spark is lazy so it will do nothing until it meets these actions to materializing RDDs.Does materialized mean something like unpacked so that the data is ready for use?
From what I read, RDD is a fault-tolerant collection of elements that can be operated on in parallel. They are created by calling the parallelize() function on a dataset which copies the elements in the dataset to form a distributed dataset that can be operated on in parallel.
Also, I think that an RDD can materialized in memory by caching it since the cache remembers the RDD's lineage.
RDD is like the 'formula' for generating data. We combine several RDDs to produce the result. The intermediate memory is saved.
RDDs do not need to be materialized at all times, as an RDD has enough information about how it was derived from other datasets(its lineage) to compute its partitions from data in stable storage.
I think persist() is a method to materialize RDD. However, since Spark is lazy, we need to do some action to this RDD after we use persist() on it. eg. var materialized = rdd.persist(); materialized.count(); After these two steps, this rdd is materialized.
When the RDD is persist(), if RDD fits into memory, then it will be stored in memory only, otherwise, stores in memory and disk.
operations like cache(), persist() only mark RDD but not materialize them; on the other hand, operations like count() materialize RDD;
and I think "materialize" RDD means execute RDD dependencies and do the actual calculations
Sparks runtime does lazy evaluation so until an action is taken the RDD is not materialized.