Why is Spark so much better in later iterations for Logistic Regression than K-Means? Does this have anything to do with the algorithms and how much memory is needed to store the intermediate results?
ArbitorOfTheFountain
My best guess is that Spark utilizes memory much better, meaning that after the first iteration (when data must be read from disk into memory), nearly all operations occur in memory. I would like to hear somebody else's take as well, because I'm still not 100% clear on this.
RX
@bojianh For hadoop, it has to write output of the previous iteration to disk, then read them from disk again for next iteration, so every iteration is actually two big disk scan. While in spark, the intermediate iterations can directly operate on in memory RDD, greatly reduce I/O cost
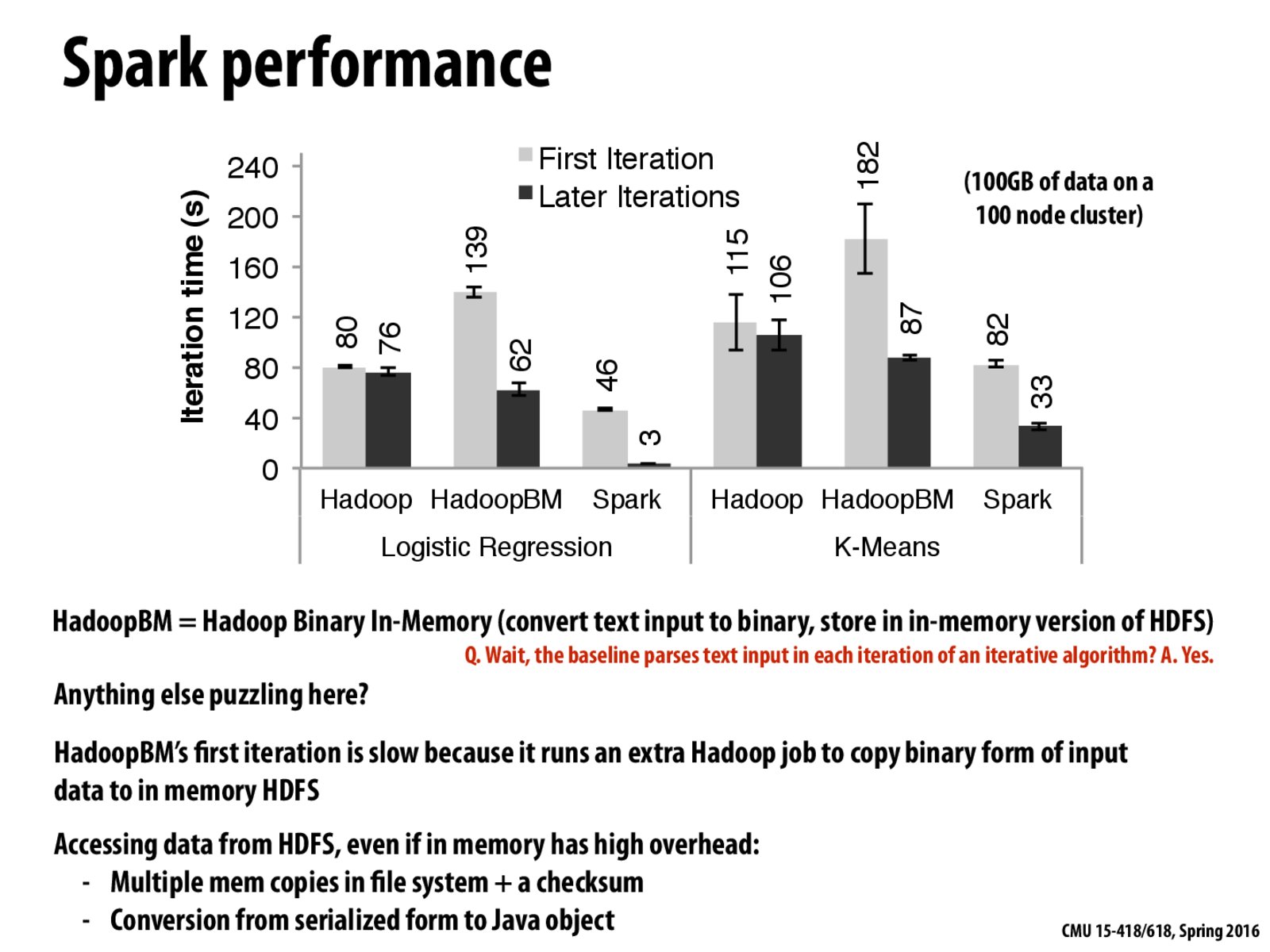
Why is Spark so much better in later iterations for Logistic Regression than K-Means? Does this have anything to do with the algorithms and how much memory is needed to store the intermediate results?
My best guess is that Spark utilizes memory much better, meaning that after the first iteration (when data must be read from disk into memory), nearly all operations occur in memory. I would like to hear somebody else's take as well, because I'm still not 100% clear on this.
@bojianh For hadoop, it has to write output of the previous iteration to disk, then read them from disk again for next iteration, so every iteration is actually two big disk scan. While in spark, the intermediate iterations can directly operate on in memory RDD, greatly reduce I/O cost