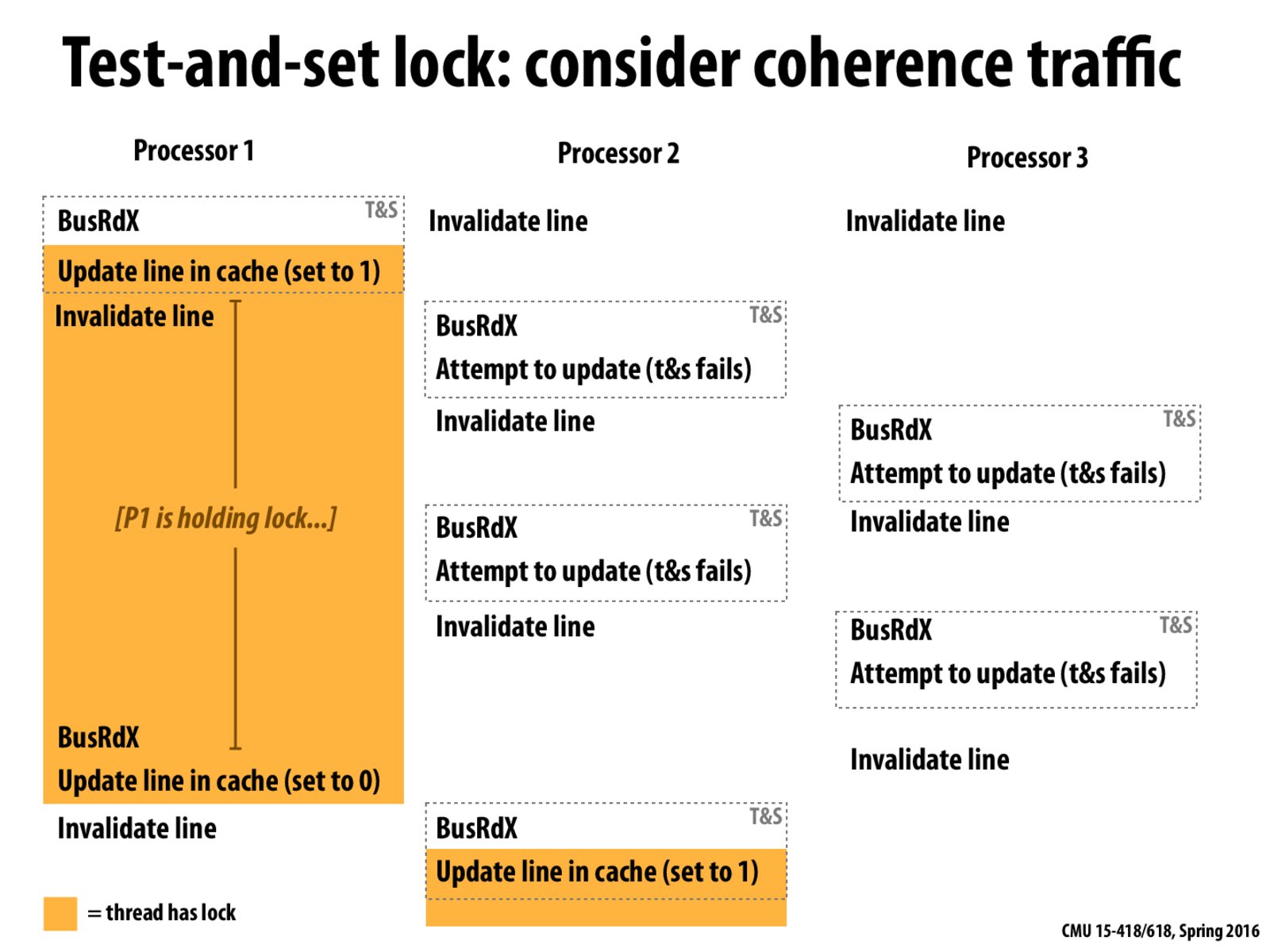
So the message of this experiment was to clarify that "holding the lock" refers to the state of the lock variable being 1, and not processor 1 having the lock variable in a "modified/exclusive" cache coherence state.
TomoA
@sidwad Rather, the message of this experiment was to show that this naive implementation of a lock actually causes a lot of coherence traffic, since all other processors are constantly invalidating the same cache line in an attempt to get the lock. This will significantly slow down the program if there are any reads and writes done in processor 1.
thomasts
To clarify, we are assuming that test-and-set is always treated as a cache write regardless of whether the lock was actually obtained, and that's why the cache line is constantly being invalidated by the other processors trying to get the lock.
eknight7
@sidwad: Thats a good statement, I would just add that processor1 may not have the cache line with the lock variable at all (and not just in "modified/exclusive state", not even in "shared" state because of the invalidation).
cmusam
From the perspective of a coherence protocol, assume the test-and-set interaction as a write. We have to get the line into the exclusive state because we are attempting to write.
bysreg
From this slide, does this mean that P2 and P3 are doing busy-waiting to grab the lock?
So the message of this experiment was to clarify that "holding the lock" refers to the state of the lock variable being 1, and not processor 1 having the lock variable in a "modified/exclusive" cache coherence state.
@sidwad Rather, the message of this experiment was to show that this naive implementation of a lock actually causes a lot of coherence traffic, since all other processors are constantly invalidating the same cache line in an attempt to get the lock. This will significantly slow down the program if there are any reads and writes done in processor 1.
To clarify, we are assuming that test-and-set is always treated as a cache write regardless of whether the lock was actually obtained, and that's why the cache line is constantly being invalidated by the other processors trying to get the lock.
@sidwad: Thats a good statement, I would just add that processor1 may not have the cache line with the lock variable at all (and not just in "modified/exclusive state", not even in "shared" state because of the invalidation).
From the perspective of a coherence protocol, assume the test-and-set interaction as a write. We have to get the line into the exclusive state because we are attempting to write.
From this slide, does this mean that P2 and P3 are doing busy-waiting to grab the lock?
@bysreg: Yeap.