I think that this is a good example of how coarse grained locking essentially serializes your program. In the coarse locks line, there is no speedup with more processors, because all accesses to the data structure are serialized. Fine-grained locking enables parallel access to the structure, so your program will scale with more processors, up to the number of locks in the structure.
MaxFlowMinCut
@a Yup, and on the other side of the coin these graphs also illustrate the overhead of taking a lock on every node of a data structure in a fine-locking mechanism. With low thread counts the overhead of locking on every node kills the runtime, but as we increase the number of threads, the exposed parallelism that we get from fine-grained locking starts to pay off and easily swamp the overhead of locking on every node.
mrrobot
Is this graph for an update only workload? Couldn't there be workloads like write-only where transactional memory could give worse performance than others because of constantly having to abort and retry transactions again and again?
ZhuansunXt
For Hashmap, the performance of TCC and fine-grained lock are almost the same in terms of speed up. The reason I guess is the granularity of locking in HashMap is even smaller than linked list and balanced tree: there's no need for hand-by-hand locking. So the contention may be even lower. Correct me if my guessing is misguided.
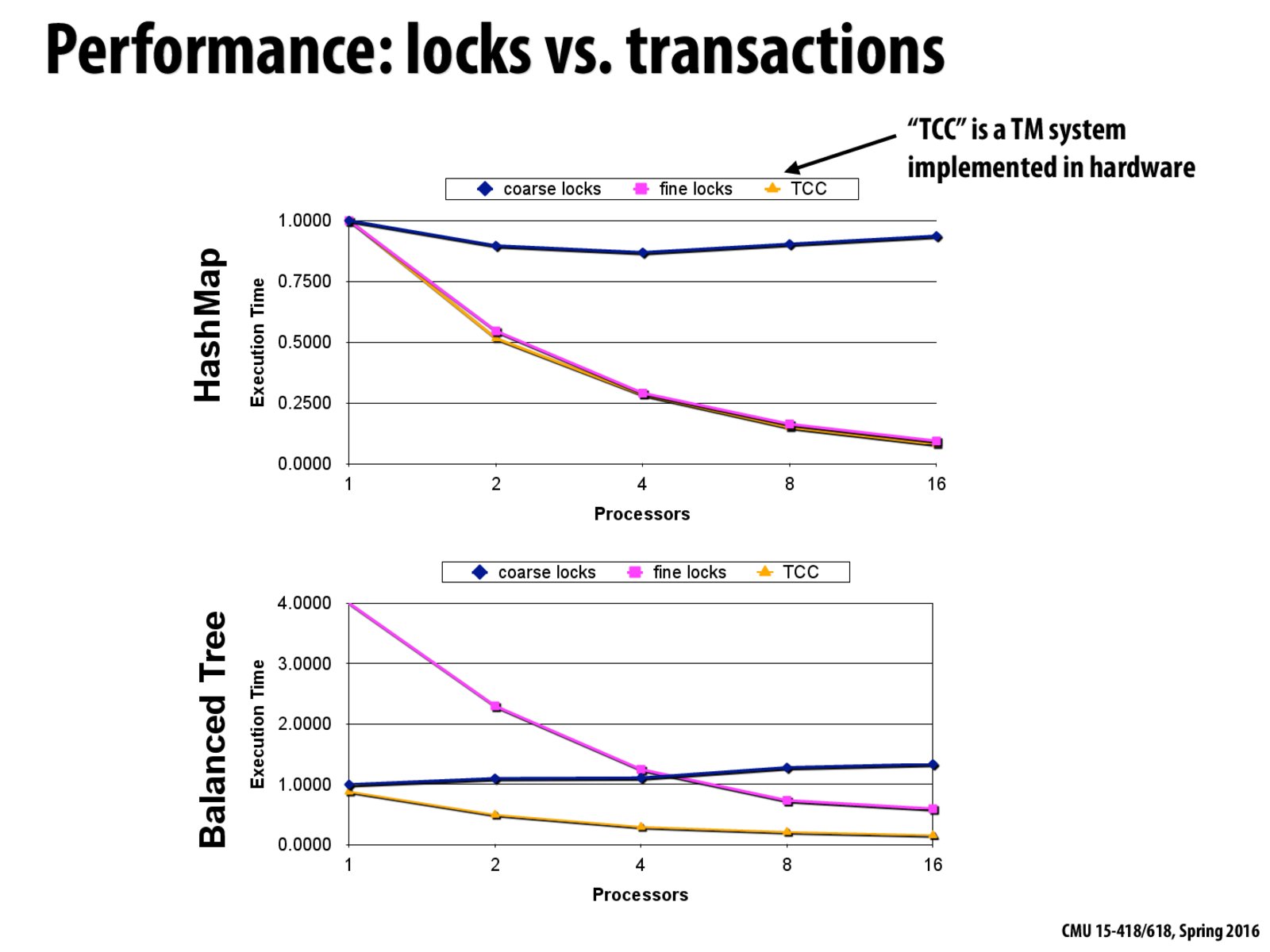
I think that this is a good example of how coarse grained locking essentially serializes your program. In the coarse locks line, there is no speedup with more processors, because all accesses to the data structure are serialized. Fine-grained locking enables parallel access to the structure, so your program will scale with more processors, up to the number of locks in the structure.
@a Yup, and on the other side of the coin these graphs also illustrate the overhead of taking a lock on every node of a data structure in a fine-locking mechanism. With low thread counts the overhead of locking on every node kills the runtime, but as we increase the number of threads, the exposed parallelism that we get from fine-grained locking starts to pay off and easily swamp the overhead of locking on every node.
Is this graph for an update only workload? Couldn't there be workloads like write-only where transactional memory could give worse performance than others because of constantly having to abort and retry transactions again and again?
For Hashmap, the performance of TCC and fine-grained lock are almost the same in terms of speed up. The reason I guess is the granularity of locking in HashMap is even smaller than linked list and balanced tree: there's no need for hand-by-hand locking. So the contention may be even lower. Correct me if my guessing is misguided.