Can someone explain why all BusRdx's sent from a processor committing a transaction have to be sent atomically?
Furthermore, after sending all the necessary BusRdx requests, is there anything else that could go wrong (if we don't implement our cache coherence protocol correctly) while this processor is waiting for the responses from the other caches?
365sleeping
Regarding the above questions,
One processor may BusRdx A and then B, and another processor may BusRdx B and then A. if all requests are not sent atomically, a typical deadlock may occur.
Don't quite understand the assumption. I guess there may be more than one pending BusRdx's to the same memory location?
althalus
Could someone clarify how exactly the HTM transaction execution is different from the MESI protocol we learnt in a couple of lectures back?
karima
@althalus
The MESI protocol is method of implementing cache coherence; it is a finite state machine that dictates how the caches of a multicore machine should behave to maintain cache coherence. Under MESI, caches send out messages and store bits indicating which state each line is in.
Hardware Transactional Memory is a particular implementation of transactional memory that leverages the infrastructure already in place on hardware that supports MESI.
But note that HTM requires additional bits for each cache line i.e. the read-set and write-set bits that are not necessary in MESI. Furthermore, the protocol for lazy-optimistic HTM dictates different cache behavior when doing a transaction than that of the MESI protocol.
When a store is done inside a transaction block before it commits, it is treated as a read from the perspective of MESI. A BusRd is sent out to the other caches instead of a BusRdX. It is only when the transaction commits that lazy-optimistic HTM will attempt to write-commit all of the lines it has in its write set for this transaction by sending out BusRdx for each of them.
althalus
@karima, thank you for the clarification. Does this mean before the commit, if another cache attempts to store(write), than there might be a possible deadlock since neither would end up committing?
EDIT: I got my answer in the next slide.
PandaX
@365sleepin In the case where two cores are committing their write to A and B at the same time. Core1 BusRdx A then BusRdx B. Core2 BusRdx B then BusRdx A. If they do it in an interleaved fashion, they both only commits a part of their modified data. This breaks the atomicity requirement of transaction. There is no deadlock situation.
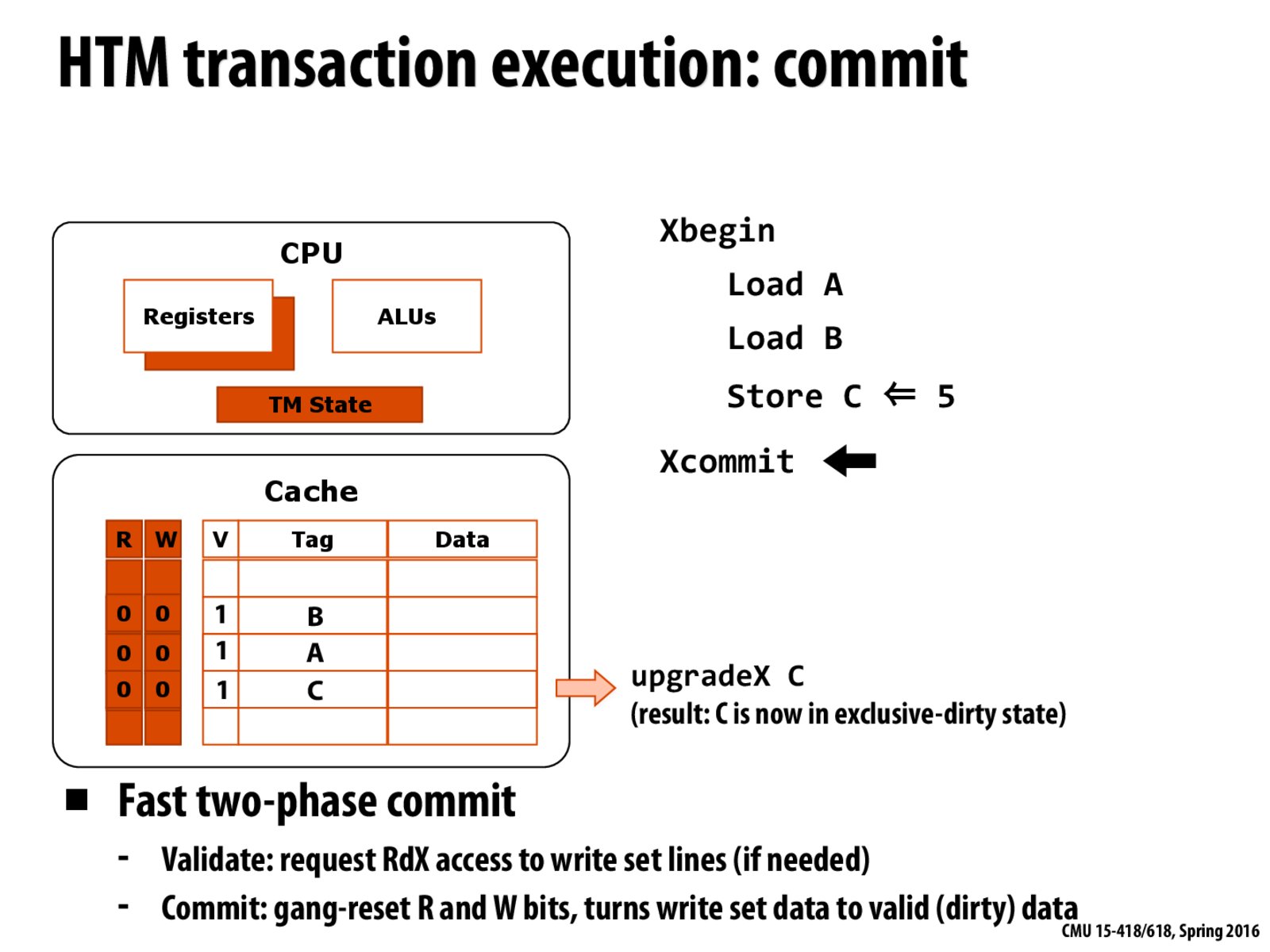
Question to check your understanding:
Can someone explain why all BusRdx's sent from a processor committing a transaction have to be sent atomically?
Furthermore, after sending all the necessary BusRdx requests, is there anything else that could go wrong (if we don't implement our cache coherence protocol correctly) while this processor is waiting for the responses from the other caches?
Regarding the above questions,
One processor may BusRdx A and then B, and another processor may BusRdx B and then A. if all requests are not sent atomically, a typical deadlock may occur.
Don't quite understand the assumption. I guess there may be more than one pending BusRdx's to the same memory location?
Could someone clarify how exactly the HTM transaction execution is different from the MESI protocol we learnt in a couple of lectures back?
@althalus
The MESI protocol is method of implementing cache coherence; it is a finite state machine that dictates how the caches of a multicore machine should behave to maintain cache coherence. Under MESI, caches send out messages and store bits indicating which state each line is in.
Hardware Transactional Memory is a particular implementation of transactional memory that leverages the infrastructure already in place on hardware that supports MESI.
But note that HTM requires additional bits for each cache line i.e. the read-set and write-set bits that are not necessary in MESI. Furthermore, the protocol for lazy-optimistic HTM dictates different cache behavior when doing a transaction than that of the MESI protocol.
When a store is done inside a transaction block before it commits, it is treated as a read from the perspective of MESI. A BusRd is sent out to the other caches instead of a BusRdX. It is only when the transaction commits that lazy-optimistic HTM will attempt to write-commit all of the lines it has in its write set for this transaction by sending out BusRdx for each of them.
@karima, thank you for the clarification. Does this mean before the commit, if another cache attempts to store(write), than there might be a possible deadlock since neither would end up committing?
EDIT: I got my answer in the next slide.
@365sleepin In the case where two cores are committing their write to A and B at the same time. Core1 BusRdx A then BusRdx B. Core2 BusRdx B then BusRdx A. If they do it in an interleaved fashion, they both only commits a part of their modified data. This breaks the atomicity requirement of transaction. There is no deadlock situation.