FYI, prior to Apache 1.3, after the initial spawning of StartServers children, only one child per second would be created to satisfy the MinSpareServers setting. The one-per-second rule was implemented in an effort to avoid swamping the machine with the startup of new children.
As of Apache 1.3, the code will relax the one-per-second rule. It will spawn one, wait a second, then spawn two, wait a second, then spawn four, and it will continue exponentially until it is spawning 32 children per second. It will stop whenever it satisfies the MinSpareServers setting.
cyl
For a single process that spawn multiple threads, different threads will share the same
code
data
kernel context
(e.q., VM structure, Descriptor table, brk pointer.)
If we want to isolate the requests, we'd better use multiple process instead of the multiple thread, though the cost are consuming more system resources and higher latency.
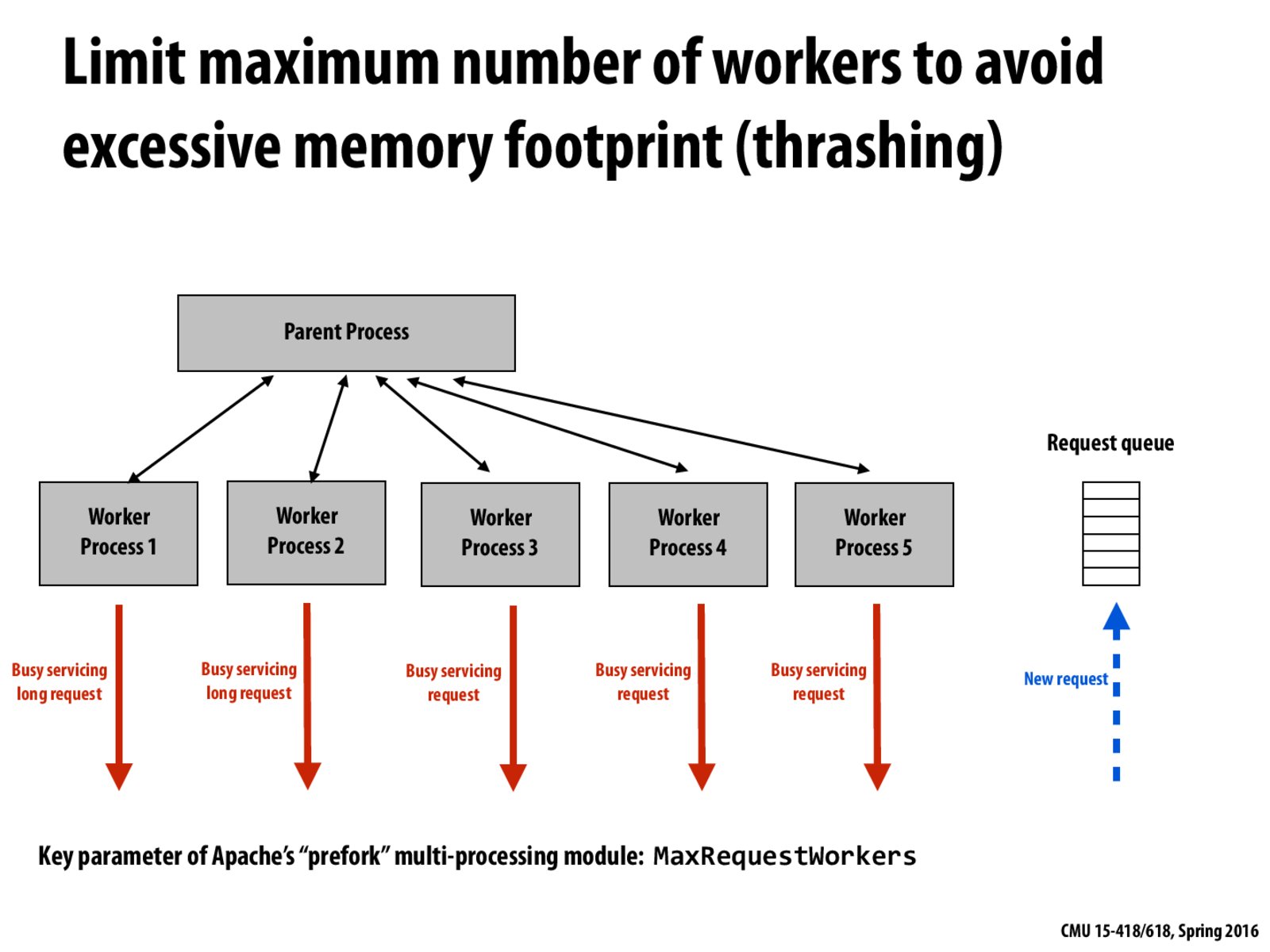
I have deployed web services on Apache for years, and it's really interesting to learn how Apache handles multiple web requests concurrently. The key idea is that Apache always maintains a couple of idle worker processes which can handle incoming requests instantaneously, such that thread-creation is out of the critical path of request handling.
Meanwhile, to prevent excessive thrashing between worker processes, Apache sets a limit on the max number of total threads. When the limit is reached, incoming requests must wait for existing jobs on the worker processes to finish. (In fact, denial-of-service attack happens when this queueing happens on a massive scale, such that legitimate requests are queued behind malicious bogus requests.)
vincom2
Another way to do this is with epoll/select, like I believe nginx uses
FYI, prior to Apache 1.3, after the initial spawning of StartServers children, only one child per second would be created to satisfy the MinSpareServers setting. The one-per-second rule was implemented in an effort to avoid swamping the machine with the startup of new children.
As of Apache 1.3, the code will relax the one-per-second rule. It will spawn one, wait a second, then spawn two, wait a second, then spawn four, and it will continue exponentially until it is spawning 32 children per second. It will stop whenever it satisfies the MinSpareServers setting.
For a single process that spawn multiple threads, different threads will share the same
code
data
kernel context (e.q., VM structure, Descriptor table, brk pointer.)
If we want to isolate the requests, we'd better use multiple process instead of the multiple thread, though the cost are consuming more system resources and higher latency.
--15213
I have deployed web services on Apache for years, and it's really interesting to learn how Apache handles multiple web requests concurrently. The key idea is that Apache always maintains a couple of idle worker processes which can handle incoming requests instantaneously, such that thread-creation is out of the critical path of request handling.
Meanwhile, to prevent excessive thrashing between worker processes, Apache sets a limit on the max number of total threads. When the limit is reached, incoming requests must wait for existing jobs on the worker processes to finish. (In fact, denial-of-service attack happens when this queueing happens on a massive scale, such that legitimate requests are queued behind malicious bogus requests.)
Another way to do this is with
epoll/select, like I believe nginx uses