This slide is saying that if every web server saved its own session state. Then the Load Balancer can distribute work to servers with the particular saved session state. However, if many requests have the same session id, and want the same session state, all the traffic will be routed to the one web server, while the other web servers are doing nothing. This will lead to load imbalance.
418_touhenying
Is there some kind of scheme that, given session id, choose the corresponding server to work on given this id if that server is free, and choose the very next free server otherwise?
PID_1
Expanding on 418_touhenying's idea. It seems like maybe you could derive some benefit from keeping the session state in the database (as in the next slide) and then also subsets of the session state on individual servers (as in this slide). If the load on a server isn't too high, you assign the same user to it repeatedly and the user gets the benefit of what is essentially caching of that session state. If the load does get too high, the user gets moved to a different server and when the lookup of the local session state fails you just go to the database to get it.
We'd have to adopt a relaxed consistency model, where the local session states won't be immediately visible to the other servers. But if that's acceptable, it seems like this adds an extra level of cache to the system.
haboric
Just check my understanding of the "good" side of load balancing with persistence. Without session ID in web server, the requests from the same session may be distributed to different web servers to be serviced. This is bad because it does maintain session affinity. So what is session affinity exactly? In order to achieve session affinity, the application would have to program explicitly that requests from this session should go to one web server. Is this what it is saying in the slide? Appreciate it if anyone can help explain.
krillfish
@haboric I think yes, that every server has to explicitly have its own session state and take on requests from clients that have that session. I'm not sure if the session state for that server can change over time, but the added benefit seems to be the ability to cache if the same user always goes to the same server.
rmanne
In reality, with a good hash function, SessionIds should have reduced chance of overloading a single server. But what happens when the target of the hash is a server that just went down? Rehashing all of the servers doesn't seem to be an option. I can imagine that it would be a good option to just send all of those crashed server's requests to a predetermined backup. Even in the case that a rehash is required, the Database doesn't need to be queried and the servers themselves will have to make some communications. Thus, I think that stateful servers is overall NOT a bad idea, and is especially easy to implement in the case that crashes are uncommon.
huehue
What exactly is a "session"? What happens if there are more sessions than servers?
misaka-10032
We don't have to make the server stateful. Rather, we may just hash the sessionId to find a server. However, the possible issue of load imbalance still exists though.
enuitt
@huehue I believe a session refers to all the data/preferences associated with a particular user (i.e. like your product recommendations when you go onto Amazon ect)
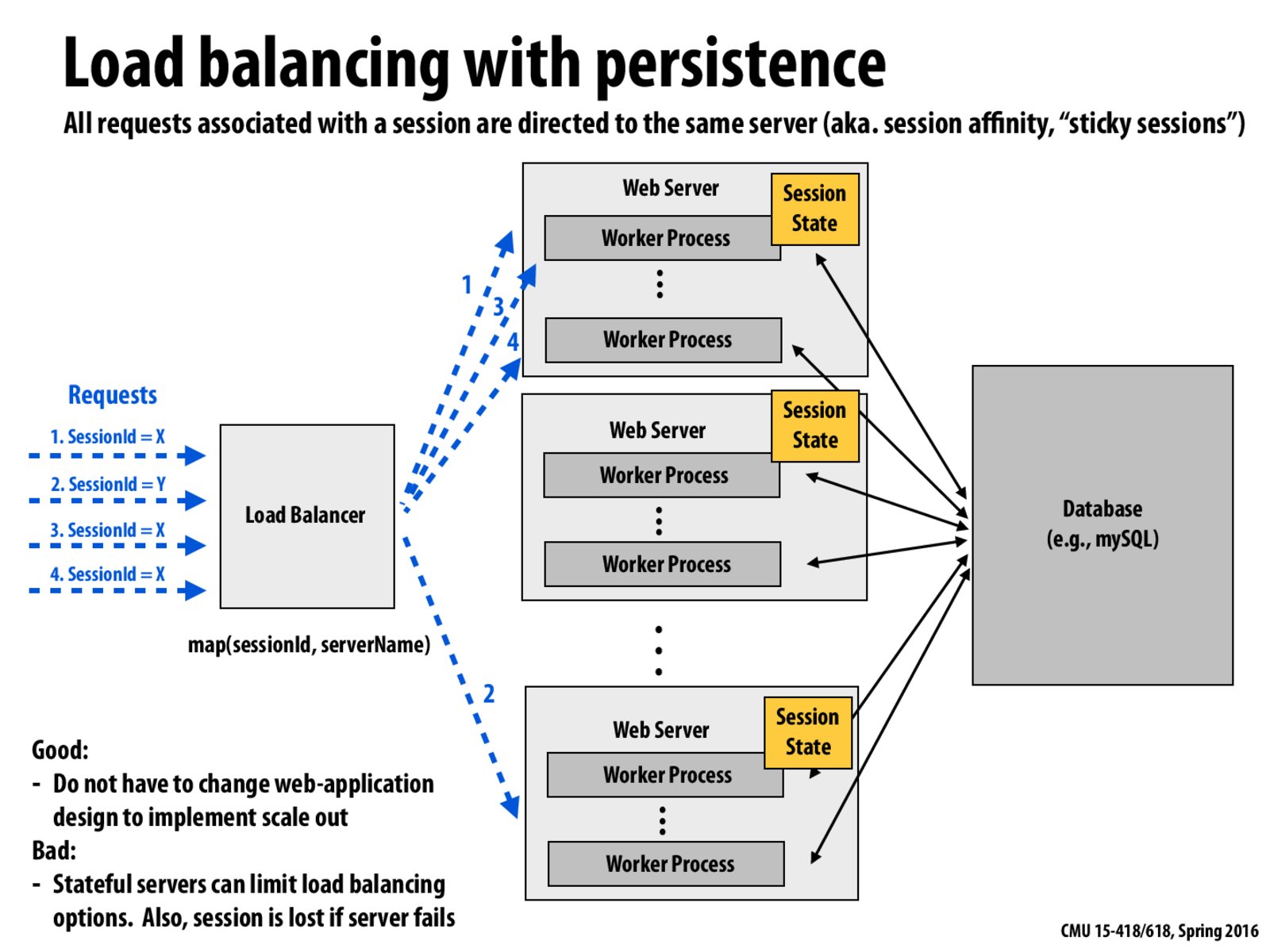
This slide is saying that if every web server saved its own session state. Then the Load Balancer can distribute work to servers with the particular saved session state. However, if many requests have the same session id, and want the same session state, all the traffic will be routed to the one web server, while the other web servers are doing nothing. This will lead to load imbalance.
Is there some kind of scheme that, given session id, choose the corresponding server to work on given this id if that server is free, and choose the very next free server otherwise?
Expanding on 418_touhenying's idea. It seems like maybe you could derive some benefit from keeping the session state in the database (as in the next slide) and then also subsets of the session state on individual servers (as in this slide). If the load on a server isn't too high, you assign the same user to it repeatedly and the user gets the benefit of what is essentially caching of that session state. If the load does get too high, the user gets moved to a different server and when the lookup of the local session state fails you just go to the database to get it.
We'd have to adopt a relaxed consistency model, where the local session states won't be immediately visible to the other servers. But if that's acceptable, it seems like this adds an extra level of cache to the system.
Just check my understanding of the "good" side of load balancing with persistence. Without session ID in web server, the requests from the same session may be distributed to different web servers to be serviced. This is bad because it does maintain session affinity. So what is session affinity exactly? In order to achieve session affinity, the application would have to program explicitly that requests from this session should go to one web server. Is this what it is saying in the slide? Appreciate it if anyone can help explain.
@haboric I think yes, that every server has to explicitly have its own session state and take on requests from clients that have that session. I'm not sure if the session state for that server can change over time, but the added benefit seems to be the ability to cache if the same user always goes to the same server.
In reality, with a good hash function, SessionIds should have reduced chance of overloading a single server. But what happens when the target of the hash is a server that just went down? Rehashing all of the servers doesn't seem to be an option. I can imagine that it would be a good option to just send all of those crashed server's requests to a predetermined backup. Even in the case that a rehash is required, the Database doesn't need to be queried and the servers themselves will have to make some communications. Thus, I think that stateful servers is overall NOT a bad idea, and is especially easy to implement in the case that crashes are uncommon.
What exactly is a "session"? What happens if there are more sessions than servers?
We don't have to make the server stateful. Rather, we may just hash the sessionId to find a server. However, the possible issue of load imbalance still exists though.
@huehue I believe a session refers to all the data/preferences associated with a particular user (i.e. like your product recommendations when you go onto Amazon ect)