In this case, the load balancer and database become the potential bottleneck of the system. Besides the two approaches mentioned in the following two slides, we can also carefully choose the type of database used in the system, depending on the workload of the query.
For example, if the requests are mostly analytical/read queries which involves scanning the entire database table(for example, calculate the sum of all records), databases such as HP Vertica is designed to handle this kind of workload. On the other hand, for requests which are mostly transactional/write (e.g. insert/delete a user record in database), databases like VoltDB handles these kind of queries very well. The type of databases to use in the web backend heavily depends on the service its providing and can make a huge different in terms of latency and throughput.
mallocanswer
Hi, @haibinl, Could you elaborate more on the details of HP Vertica and VoltDB? Why will they have different performance on write or read queries?
haibinl
Vertica and VoltDB are both relational databases, but designed for different workloads and have different storage engines optimized for its use case. There're two general approaches, one is column-based(Vertica), where the database retrieve a column at a time during query execution; the other is row-based(VoltDB), where the database retrieve a tuple/row at a time.
For example, it's common that telecom companies like AT&T have a table of more than 100 columns in their database to store the information for each customer. When inserting a new customer's record to this table, row-based storage model is better since the database can simply insert the new row to the last row; meanwhile column-based storage model requires the database to load each column and append the new attribute value to each of them, which is terrible in performance.
On the other hand, analytical queries usually involves a small subset of the attributes(e.g. select name, salary, age from table). Column-based approach performs much better compared to row-based one when the table spans more than 100 columns, since only relevant column is retrieved by the database, meanwhile row-based database will load all the columns for each row and discard irrelevant columns, which wastes lots of memory/disk access.
narainsk
Anyone familiar with the scalability differences between NoSQL and Relational databases?
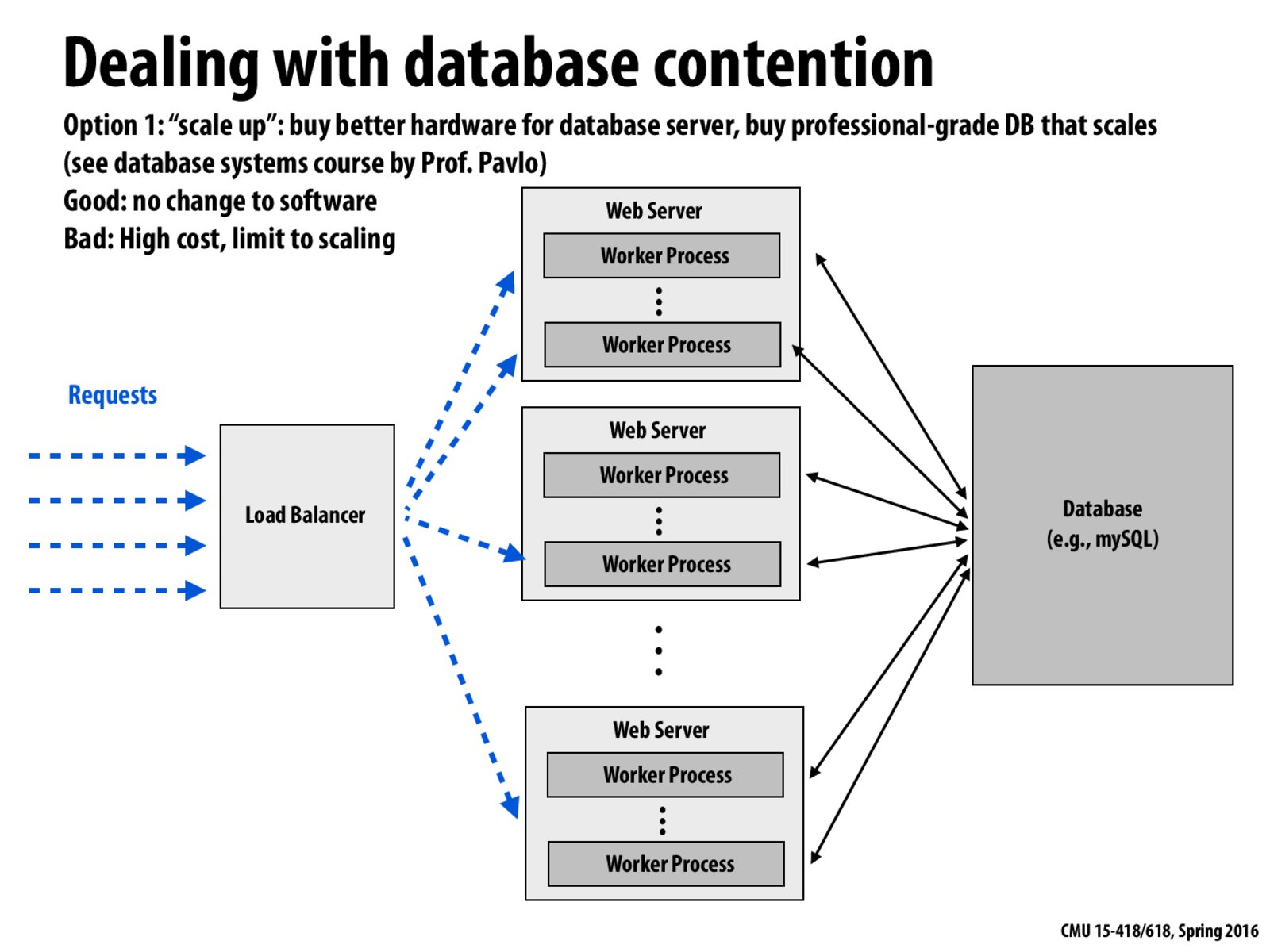
In this case, the load balancer and database become the potential bottleneck of the system. Besides the two approaches mentioned in the following two slides, we can also carefully choose the type of database used in the system, depending on the workload of the query.
For example, if the requests are mostly analytical/read queries which involves scanning the entire database table(for example, calculate the sum of all records), databases such as HP Vertica is designed to handle this kind of workload. On the other hand, for requests which are mostly transactional/write (e.g. insert/delete a user record in database), databases like VoltDB handles these kind of queries very well. The type of databases to use in the web backend heavily depends on the service its providing and can make a huge different in terms of latency and throughput.
Hi, @haibinl, Could you elaborate more on the details of HP Vertica and VoltDB? Why will they have different performance on write or read queries?
Vertica and VoltDB are both relational databases, but designed for different workloads and have different storage engines optimized for its use case. There're two general approaches, one is column-based(Vertica), where the database retrieve a column at a time during query execution; the other is row-based(VoltDB), where the database retrieve a tuple/row at a time.
For example, it's common that telecom companies like AT&T have a table of more than 100 columns in their database to store the information for each customer. When inserting a new customer's record to this table, row-based storage model is better since the database can simply insert the new row to the last row; meanwhile column-based storage model requires the database to load each column and append the new attribute value to each of them, which is terrible in performance.
On the other hand, analytical queries usually involves a small subset of the attributes(e.g. select name, salary, age from table). Column-based approach performs much better compared to row-based one when the table spans more than 100 columns, since only relevant column is retrieved by the database, meanwhile row-based database will load all the columns for each row and discard irrelevant columns, which wastes lots of memory/disk access.
Anyone familiar with the scalability differences between NoSQL and Relational databases?