There should be a lot of ways of partitioning data. Besides partitioning data on a partitcular column/field (user), I think partitioning different columns of data to different machines might work too under some situations. For example, some requests, like a list of available drivers in an area might be accessed and modified very frequently, but maybe except name, car model and plate, other fields of a driver are not needed in the most frequent lists. No longer in need of retrieving a lot of unnecesary fields, we could save the time to get a list of a few columns a lot faster. Therefore retrieving data of particular columns might be efficient in some cases. After some digging, I found that this is not only a way of partitioning data, but also a concept of columnar database, for example Amazon's RedShift.
maxdecmeridius
Here, the idea is to basically partition the database into specialized databases that handle one specific type of services. How is this cheaper or more efficient than buying a bigger database? It seems like this can also be limited by hardware resources, much like our earlier database.
Lawliet
So in order to figure out which database we should store data in, we should use a similar structure to a hash function, except on a larger scale.
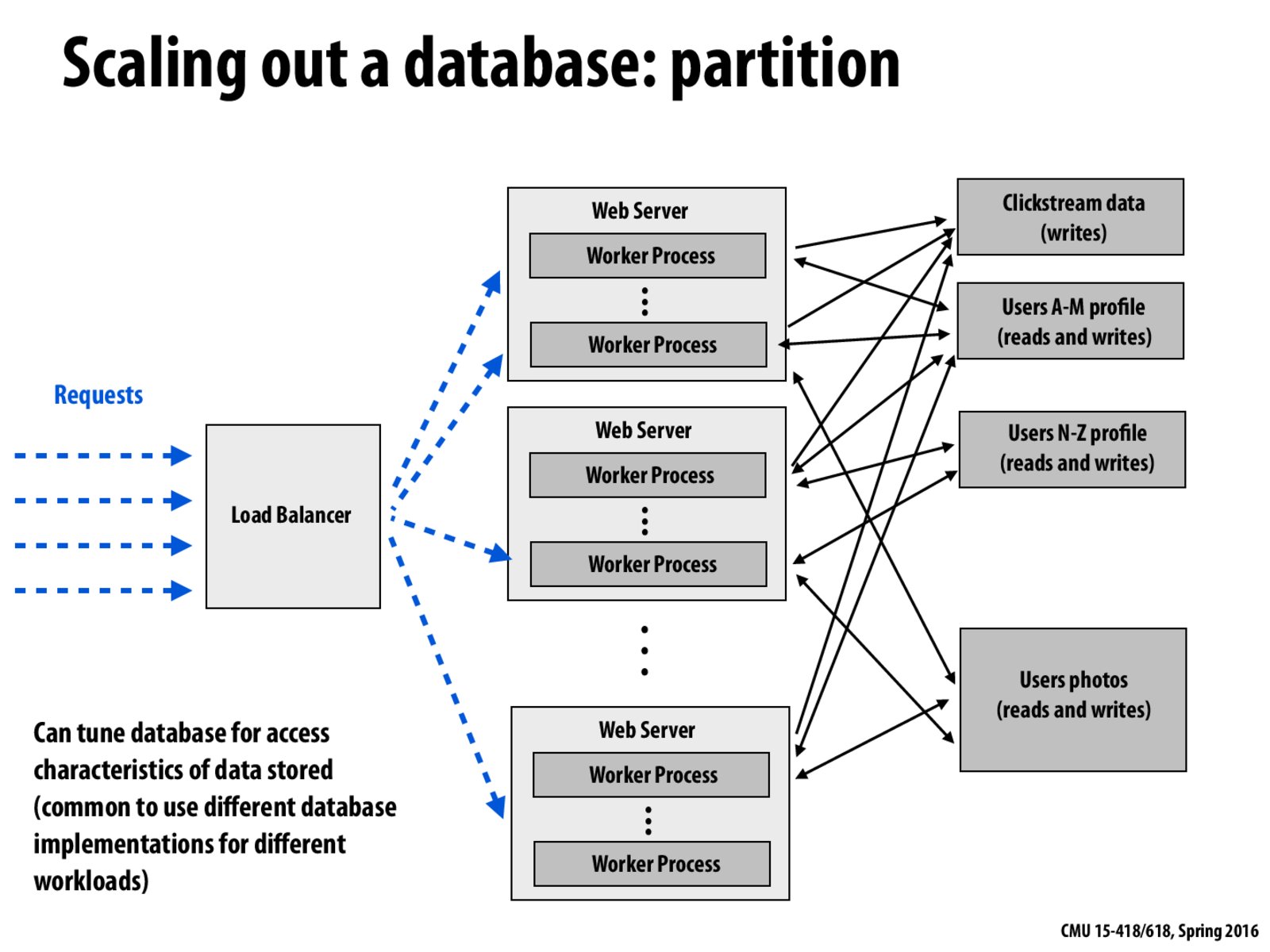
There should be a lot of ways of partitioning data. Besides partitioning data on a partitcular column/field (user), I think partitioning different columns of data to different machines might work too under some situations. For example, some requests, like a list of available drivers in an area might be accessed and modified very frequently, but maybe except name, car model and plate, other fields of a driver are not needed in the most frequent lists. No longer in need of retrieving a lot of unnecesary fields, we could save the time to get a list of a few columns a lot faster. Therefore retrieving data of particular columns might be efficient in some cases. After some digging, I found that this is not only a way of partitioning data, but also a concept of columnar database, for example Amazon's RedShift.
Here, the idea is to basically partition the database into specialized databases that handle one specific type of services. How is this cheaper or more efficient than buying a bigger database? It seems like this can also be limited by hardware resources, much like our earlier database.
So in order to figure out which database we should store data in, we should use a similar structure to a hash function, except on a larger scale.