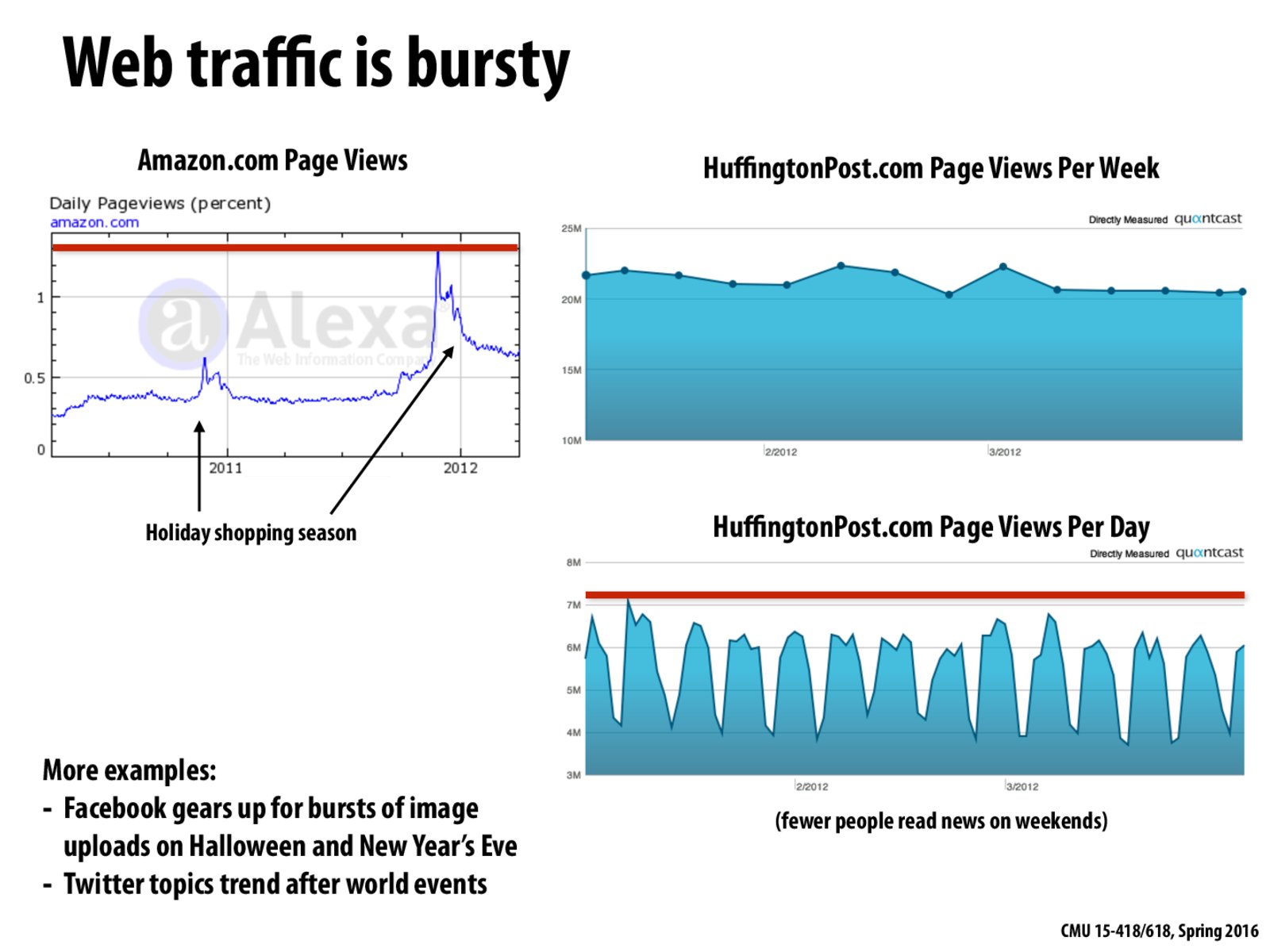
Is there a cost we need to pay for changing the number of active servers?
It seems like sites like HuffingtonPost.com will have a high frequency of bursty traffic, which means frequent scaling up and down.
bdebebe
I think that's the whole point of an elastic web server. The capability of the web server to swing back and forth to handle this demand (as well as handling normal traffic) is worth the overhead required to scale to demand. Someone feel free to correct me if I'm wrong!
Funky9000
@bdebebe You are correct. Web servers are created/deleted to meet changing number of requests. However, it should be noted if requests suddenly spike, then it is possible for the machines abilities to be exceeded, resulting in slow traffic, no matter how good your scaling is. But in general, elastic web servers should meet most of the website needs.
mperron
One interesting thing to note is that other companies may have complementary access patterns, spiking on the weekends and dropping during the week. If there are enough users with different access pattern, hopefully the total load on the systems is more even.
temmie
@mperron I worked at a company last summer that ran a gaming website mainly aimed at kids and teens, and their access patterns were complementary just as you described: we would see spikes every weekend and school holiday, as well as far more traffic overall during summer and winter breaks. Presumably that would moderate the overall load somewhat, but I guess the holiday season is a big enough boost for enough sites to still be an issue.
fleventyfive
Isn't burstiness the reason that Amazon Web Services was started? Amazon sort of stocked up on resources to gear up for the end-of-the-year traffic, around Halloween, Christmas, New Years etc. But for the rest of the year, they realized that they were underutilizing their resources. This led them to think of renting out their compute capacity to people who were willing to use them with a pay-as-you-go model, leading to the birth of AWS!
teamG
Based on what I learned from assignment 4, it seems like even though it is a good idea to launch or kill workers according to the traffic, we may want to be careful in terms of the metrics that we use to make the decision. When we used a very simple threshold to determine if we want to kill or spawn, like current requests, it resulted in a lot of thrashing. And from our testing it seems like it was better for us to make the decision over slightly more advanced metrics. It seems like from my experience for assignment 4, we want to implement a strict policy for both killing or spawning. But apparently both policies are fine according to what kayvon said in office hours.
bojianh
One thing about assignment 4 is that if it is possible to figure out the computational resources needed by tasks, then it is possible to make decisions using more advanced metrics of assigning workload in a certain pattern and also there is another point on that it is sometimes important to spawn a lot of new nodes at the same time when reacting to bursts in traffic.
jellybean
Another way some large websites (such as Facebook) handle burstiness is to run internal jobs on web servers during down time. For example, Facebook teams can add large regression tests, ML training sets, or any other job to a queue that will be put on servers when they aren't needed to handle user requests.
Is there a cost we need to pay for changing the number of active servers? It seems like sites like HuffingtonPost.com will have a high frequency of bursty traffic, which means frequent scaling up and down.
I think that's the whole point of an elastic web server. The capability of the web server to swing back and forth to handle this demand (as well as handling normal traffic) is worth the overhead required to scale to demand. Someone feel free to correct me if I'm wrong!
@bdebebe You are correct. Web servers are created/deleted to meet changing number of requests. However, it should be noted if requests suddenly spike, then it is possible for the machines abilities to be exceeded, resulting in slow traffic, no matter how good your scaling is. But in general, elastic web servers should meet most of the website needs.
One interesting thing to note is that other companies may have complementary access patterns, spiking on the weekends and dropping during the week. If there are enough users with different access pattern, hopefully the total load on the systems is more even.
@mperron I worked at a company last summer that ran a gaming website mainly aimed at kids and teens, and their access patterns were complementary just as you described: we would see spikes every weekend and school holiday, as well as far more traffic overall during summer and winter breaks. Presumably that would moderate the overall load somewhat, but I guess the holiday season is a big enough boost for enough sites to still be an issue.
Isn't burstiness the reason that Amazon Web Services was started? Amazon sort of stocked up on resources to gear up for the end-of-the-year traffic, around Halloween, Christmas, New Years etc. But for the rest of the year, they realized that they were underutilizing their resources. This led them to think of renting out their compute capacity to people who were willing to use them with a pay-as-you-go model, leading to the birth of AWS!
Based on what I learned from assignment 4, it seems like even though it is a good idea to launch or kill workers according to the traffic, we may want to be careful in terms of the metrics that we use to make the decision. When we used a very simple threshold to determine if we want to kill or spawn, like current requests, it resulted in a lot of thrashing. And from our testing it seems like it was better for us to make the decision over slightly more advanced metrics. It seems like from my experience for assignment 4, we want to implement a strict policy for both killing or spawning. But apparently both policies are fine according to what kayvon said in office hours.
One thing about assignment 4 is that if it is possible to figure out the computational resources needed by tasks, then it is possible to make decisions using more advanced metrics of assigning workload in a certain pattern and also there is another point on that it is sometimes important to spawn a lot of new nodes at the same time when reacting to bursts in traffic.
Another way some large websites (such as Facebook) handle burstiness is to run internal jobs on web servers during down time. For example, Facebook teams can add large regression tests, ML training sets, or any other job to a queue that will be put on servers when they aren't needed to handle user requests.