The main factor seems to be due to caching behavior. With smaller work split among each processor, the working set of data can be entirely fit into a lower cache hierarchy level.
msfernan
Would it be possible to use instruction level parallelism to get a speedup greater than P when using P processors for a simple program?
For example lets assume we have a data-sheet that that we need to run a data processing instruction on.
We can run the data-processing instruction with half of the data-sheet on one core and half of the data-sheet on another core. If the data consists on numbers and the data-processing instruction just sums the numbers we should get a 2x speedup. (Im assuming the communication costs between cores are negligible)
Now if we design the cores to support instruction level parallelism wont we be able to get a greater than 2x speedup?
memebryant
@msfernan, it seems that we could've just gotten the ILP speedup in the first place if this were true.
SchizophrenicJedi
@huehue One example where I experienced something like this was in the Cloud Computing group project where we had to build a system with a parallel backend database (in this case it was HBase) with about 50 GB of data. With 4 nodes each having 6 GB memory, there was a lot of contention for the cache. Once we had 8 nodes, almost everything was served from memory leading to a performance improvement much greater than 2x. Not exactly a multiprocessor environment, but the same techniques to apply...
eknight7
@memebryant Why would @msfernan's technique not work? If the both cores support ILP and they have divided the work, we could possibly get greater than 2x speedup right?
MuscleNerd
@eknight7, there is probably scheduling cost in addition to the communication cost in ILP which prevent us from getting the perfect speed up. These costs can "severely limit" the speedup as mentioned in slide 11.
Richard
I remember there are both strong speedup and weak speedup, referring to whether or not to increase the number of tasks while assessing speedup, respectively. For the strong speedup, the concept is more like "decreasing latency"; for the weak one, it's more like "increase bandwidth".
bmperez
@msfernan, @eknight
I believe that @memebryant's point is that if the processor has ILP, then we are getting the speedup both when we run a serial version and when we run a parallel version. Thus, the effect of the ILP get nulled out because it is present in both versions.
For example, say ILP gave us a 2x speedup. So the serial version would run at 2x the time we initially expected. Now, let's say we parallelize to 4 cores. We get a 2x speedup from each core individually, so in total, we expect a 2 * 4 = 8x speedup. However, the serial implementation already has a 2x speedup, so the total speedup is 8/2 = 4x speedup. Thus, the effect of ILP on overall speedup is not seen, only the multicore speedup.
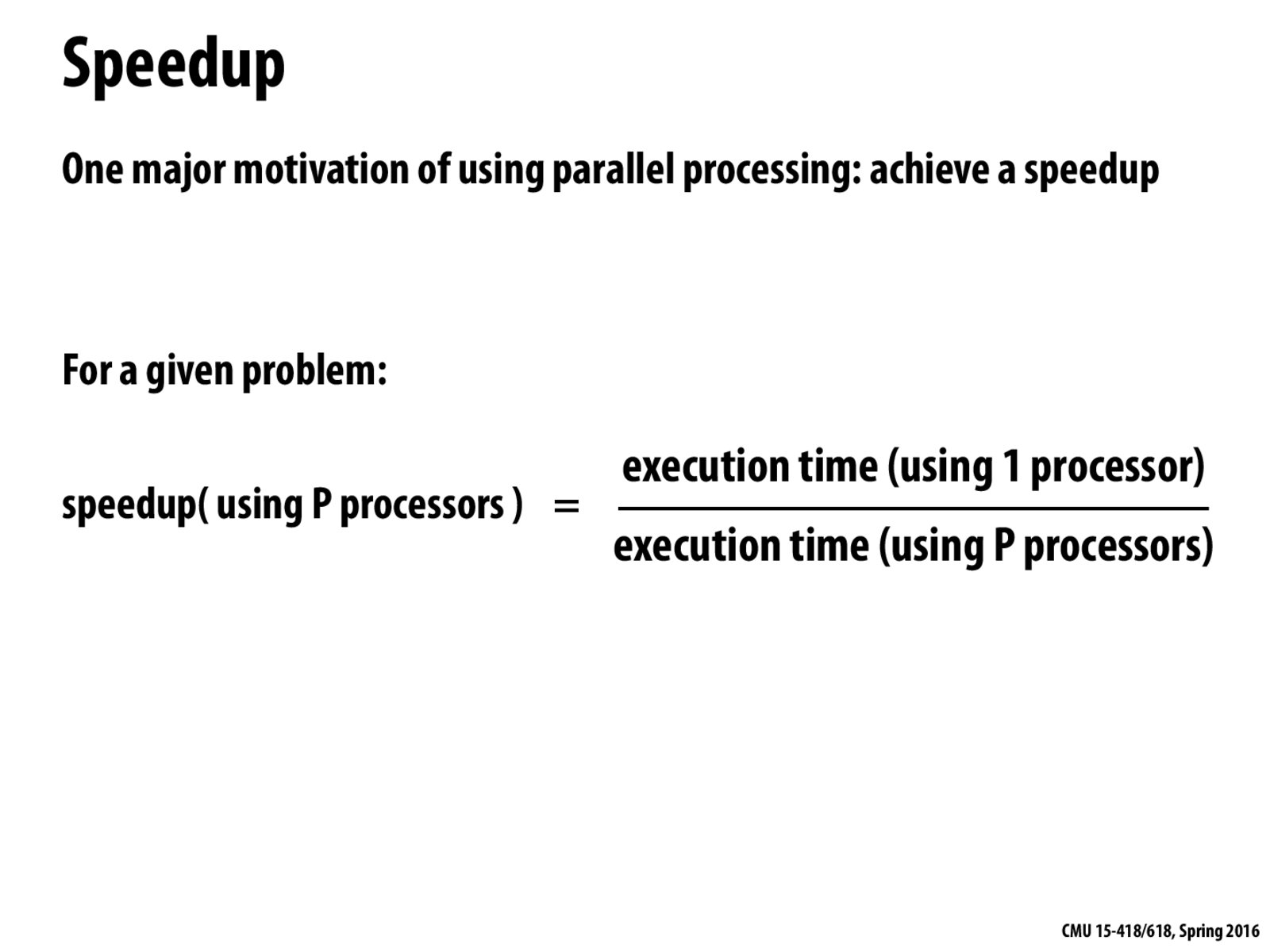
Is it possible to get a speedup of greater than P when using P processors? If so, how?
The wikipedia article for speedup gives some explanations for this.
The main factor seems to be due to caching behavior. With smaller work split among each processor, the working set of data can be entirely fit into a lower cache hierarchy level.
Would it be possible to use instruction level parallelism to get a speedup greater than P when using P processors for a simple program?
For example lets assume we have a data-sheet that that we need to run a data processing instruction on.
We can run the data-processing instruction with half of the data-sheet on one core and half of the data-sheet on another core. If the data consists on numbers and the data-processing instruction just sums the numbers we should get a 2x speedup. (Im assuming the communication costs between cores are negligible)
Now if we design the cores to support instruction level parallelism wont we be able to get a greater than 2x speedup?
@msfernan, it seems that we could've just gotten the ILP speedup in the first place if this were true.
@huehue One example where I experienced something like this was in the Cloud Computing group project where we had to build a system with a parallel backend database (in this case it was HBase) with about 50 GB of data. With 4 nodes each having 6 GB memory, there was a lot of contention for the cache. Once we had 8 nodes, almost everything was served from memory leading to a performance improvement much greater than 2x. Not exactly a multiprocessor environment, but the same techniques to apply...
@memebryant Why would @msfernan's technique not work? If the both cores support ILP and they have divided the work, we could possibly get greater than 2x speedup right?
@eknight7, there is probably scheduling cost in addition to the communication cost in ILP which prevent us from getting the perfect speed up. These costs can "severely limit" the speedup as mentioned in slide 11.
I remember there are both strong speedup and weak speedup, referring to whether or not to increase the number of tasks while assessing speedup, respectively. For the strong speedup, the concept is more like "decreasing latency"; for the weak one, it's more like "increase bandwidth".
@msfernan, @eknight
I believe that @memebryant's point is that if the processor has ILP, then we are getting the speedup both when we run a serial version and when we run a parallel version. Thus, the effect of the ILP get nulled out because it is present in both versions.
For example, say ILP gave us a 2x speedup. So the serial version would run at 2x the time we initially expected. Now, let's say we parallelize to 4 cores. We get a 2x speedup from each core individually, so in total, we expect a 2 * 4 = 8x speedup. However, the serial implementation already has a 2x speedup, so the total speedup is 8/2 = 4x speedup. Thus, the effect of ILP on overall speedup is not seen, only the multicore speedup.