A superscalar processor that respects program order produces the same output as a sequential processor that runs the program in the order the instructions are given. The superscalar processor may run instructions out of order but that's ok as long as it produces the same output, the one one would expect out of this program.
emt
For superscalar processors, instructions can be carried out in an order that's different from what they appeared in. The processor looks for instructions that can be carried out independently, so that even though they might be executed out of order, they still produce the same result as the sequential order of instructions. Thus, superscalar processors are limited by the instruction-level parallelism of the code.
Bye
"Respect program order" means that the super-scalar processor should not violate instruction-level dependencies, which suggests that a super-scalar processor should produce the same outcome as if the program is executed sequentially in given instruction order on a simple processor.
kayvonf
@everyone -- Those that reported a bug on the slide, nice catch! There was a typo on the slide. But it's in the code, not the DAG. The predicate:
if (tmp4 > 7)
should have been
if (tmp3 > 7)
The slide is now fixed to reflect this, and you may need to refresh the page. I'm going to archive all the comments in this discussion to avoid confusing others that see the correct slide.
Note that the DAG elides dependencies that are captured by existing transitive relationships. For example, node 3 is clearly dependent on both 0 and 2. However, since 2 is also dependent on 0, if node 3's dependency on 2 is satisfied (i.e., 2 has been computed), we're guaranteed that 0 has also been generated at this time. Therefore, it is unnecessary to check both the dependency on 2 and on 0.
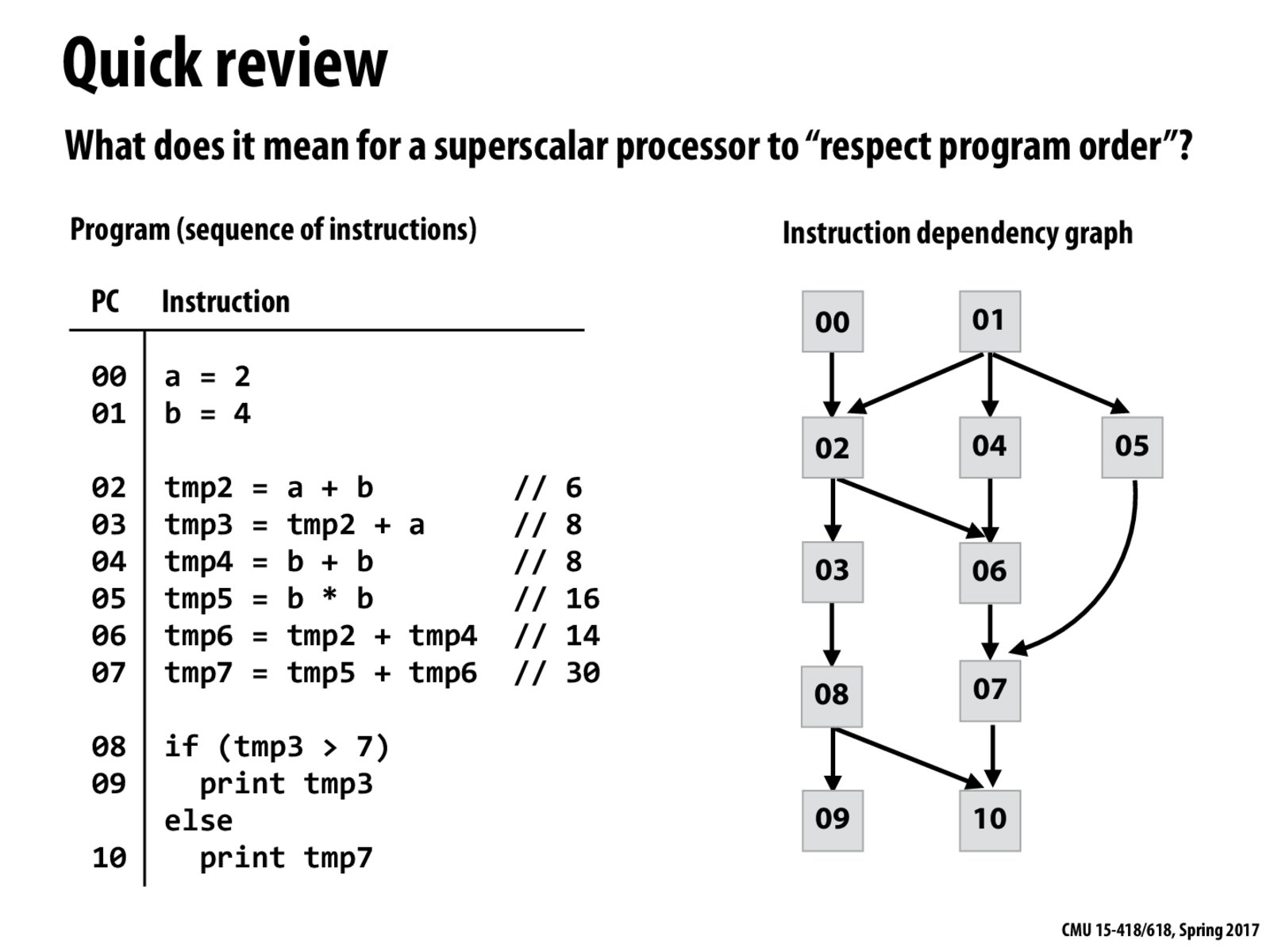
For instruction-level parallelism, the processor can execute instructions in any topological order of the dependency graph. Amusingly, computing a topological order on a graph is linear on a single core but parallelizes very well.
A superscalar processor that respects program order produces the same output as a sequential processor that runs the program in the order the instructions are given. The superscalar processor may run instructions out of order but that's ok as long as it produces the same output, the one one would expect out of this program.
For superscalar processors, instructions can be carried out in an order that's different from what they appeared in. The processor looks for instructions that can be carried out independently, so that even though they might be executed out of order, they still produce the same result as the sequential order of instructions. Thus, superscalar processors are limited by the instruction-level parallelism of the code.
"Respect program order" means that the super-scalar processor should not violate instruction-level dependencies, which suggests that a super-scalar processor should produce the same outcome as if the program is executed sequentially in given instruction order on a simple processor.
@everyone -- Those that reported a bug on the slide, nice catch! There was a typo on the slide. But it's in the code, not the DAG. The predicate:
should have been
The slide is now fixed to reflect this, and you may need to refresh the page. I'm going to archive all the comments in this discussion to avoid confusing others that see the correct slide.
Note that the DAG elides dependencies that are captured by existing transitive relationships. For example, node 3 is clearly dependent on both 0 and 2. However, since 2 is also dependent on 0, if node 3's dependency on 2 is satisfied (i.e., 2 has been computed), we're guaranteed that 0 has also been generated at this time. Therefore, it is unnecessary to check both the dependency on 2 and on 0.