Utilization of the processors is 100% here because at any time, there is some thread running on the processor.
rrp123
Although this slide shows 100% utilization of the processors, the programs in the slides still finish later than if they are running sequentially, since there's a difference in time between when the program can be run and when each program actually runs. Thus, if we want just one program to finish fast, we may not want to run other execution contexts, although this means that we don't attain full utilization of the processor.
nnx
How does the thread signal the other threads that the stall is over? Or does the process know to constantly check to see if thread one's stall is completed? Or does the process only do that after all threads are run (much like in this case)?
blah329
@nnx One way that I can imagine that this could occur is by putting the thread in a state that it is not runnable when the stall begins--this stall can be a memory access. Once that stall is over, an interrupt can be generated, at which point an interrupt service routine is executed, and that thread is made runnable again.
bschmuck
The utilization of the processors is 100%, but wouldn't the efficiency be far from it for small tasks because of the overhead of calling an ISR and switching thread context?
rrudolph
If all four of the initial blocks finished executing before the first block's memory access finished, we would not be running at 100% efficiency, correct? I'm confused about the 100% efficiency, as far as I can tell, it seems like this is only the case GIVEN that the memory access takes < 4x the exectuion time of the first segment of instructions.
tarabyte
This slide also shows an important distinction between decreasing latency and hiding it. Here, thread one finishes later than it would have, so we are not decreasing latency. But, since one of the four threads is always running, it feels as if we are not stalling for anything. In this case we are just hiding latency. An example of actually decreasing latency would be with caches.
kayvonf
@nnx. I would like clarify that the decision of what thread to run at what time is the decision of the processor, not software. Therefore, there is no need for a "thread" to signal another thread. The processor attempts to run the next instruction in a thread's instruction stream. If it cannot, because inputs to the instruction are not yet available (e.g., waiting on the results of a prior instruction, waiting on memory), then rather than stalling and executing no instruction from the thread in a cycle, the processor automatically switches over to execute instructions from a different thread.
This diagram illustrated interleaved multi-threading, with a scheduling policy of switching threads only when a stall is encountered. I highly encourage everyone to take a look at the extra multi-threading review slides at the end of the lecture that illustrate other possible scheduling strategies (e.g., switch every instruction).
Levy
This multithreading here is a little bit different from multithreading in OS. In OS, the context of each thread is stored in memories, and context switch between threads pains since it has to access memory. The hardware support threads, however, keep several (say, two) sets of registers in the core and switching between them is extremely cheap. Another difference is that the switch between hardware threads will be triggered in memory access, while context switch of OS threads cannot be triggered by normal memory access (since it is not trapped).
fxffx
Multithreading can let a program better utilize the execution resources it has because when one thread is waiting for memory, another thread can proceed, so that the program can still make progress.
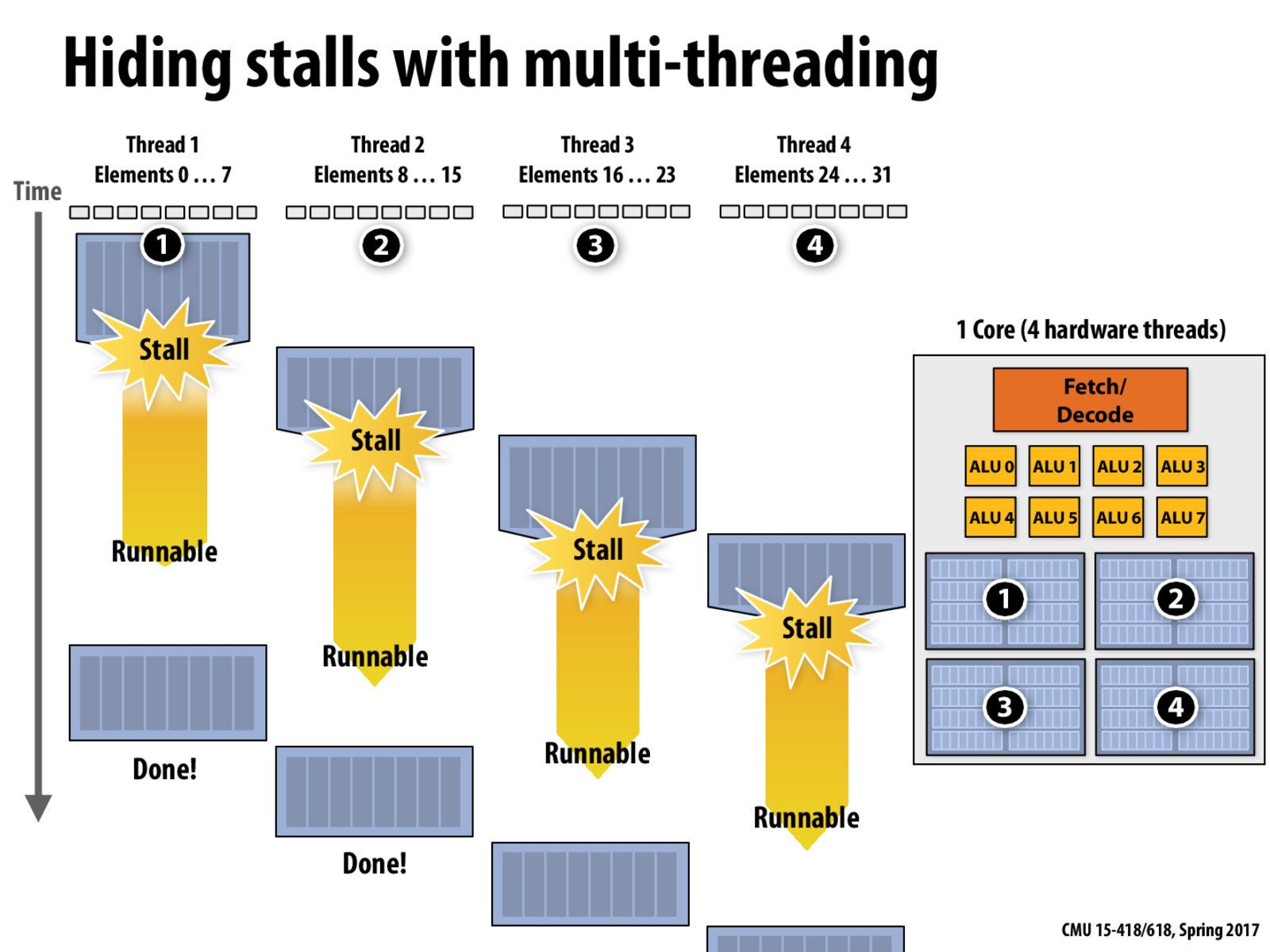
Utilization of the processors is 100% here because at any time, there is some thread running on the processor.
Although this slide shows 100% utilization of the processors, the programs in the slides still finish later than if they are running sequentially, since there's a difference in time between when the program can be run and when each program actually runs. Thus, if we want just one program to finish fast, we may not want to run other execution contexts, although this means that we don't attain full utilization of the processor.
How does the thread signal the other threads that the stall is over? Or does the process know to constantly check to see if thread one's stall is completed? Or does the process only do that after all threads are run (much like in this case)?
@nnx One way that I can imagine that this could occur is by putting the thread in a state that it is not runnable when the stall begins--this stall can be a memory access. Once that stall is over, an interrupt can be generated, at which point an interrupt service routine is executed, and that thread is made runnable again.
The utilization of the processors is 100%, but wouldn't the efficiency be far from it for small tasks because of the overhead of calling an ISR and switching thread context?
If all four of the initial blocks finished executing before the first block's memory access finished, we would not be running at 100% efficiency, correct? I'm confused about the 100% efficiency, as far as I can tell, it seems like this is only the case GIVEN that the memory access takes < 4x the exectuion time of the first segment of instructions.
This slide also shows an important distinction between decreasing latency and hiding it. Here, thread one finishes later than it would have, so we are not decreasing latency. But, since one of the four threads is always running, it feels as if we are not stalling for anything. In this case we are just hiding latency. An example of actually decreasing latency would be with caches.
@nnx. I would like clarify that the decision of what thread to run at what time is the decision of the processor, not software. Therefore, there is no need for a "thread" to signal another thread. The processor attempts to run the next instruction in a thread's instruction stream. If it cannot, because inputs to the instruction are not yet available (e.g., waiting on the results of a prior instruction, waiting on memory), then rather than stalling and executing no instruction from the thread in a cycle, the processor automatically switches over to execute instructions from a different thread.
This diagram illustrated interleaved multi-threading, with a scheduling policy of switching threads only when a stall is encountered. I highly encourage everyone to take a look at the extra multi-threading review slides at the end of the lecture that illustrate other possible scheduling strategies (e.g., switch every instruction).
This multithreading here is a little bit different from multithreading in OS. In OS, the context of each thread is stored in memories, and context switch between threads pains since it has to access memory. The hardware support threads, however, keep several (say, two) sets of registers in the core and switching between them is extremely cheap. Another difference is that the switch between hardware threads will be triggered in memory access, while context switch of OS threads cannot be triggered by normal memory access (since it is not trapped).
Multithreading can let a program better utilize the execution resources it has because when one thread is waiting for memory, another thread can proceed, so that the program can still make progress.