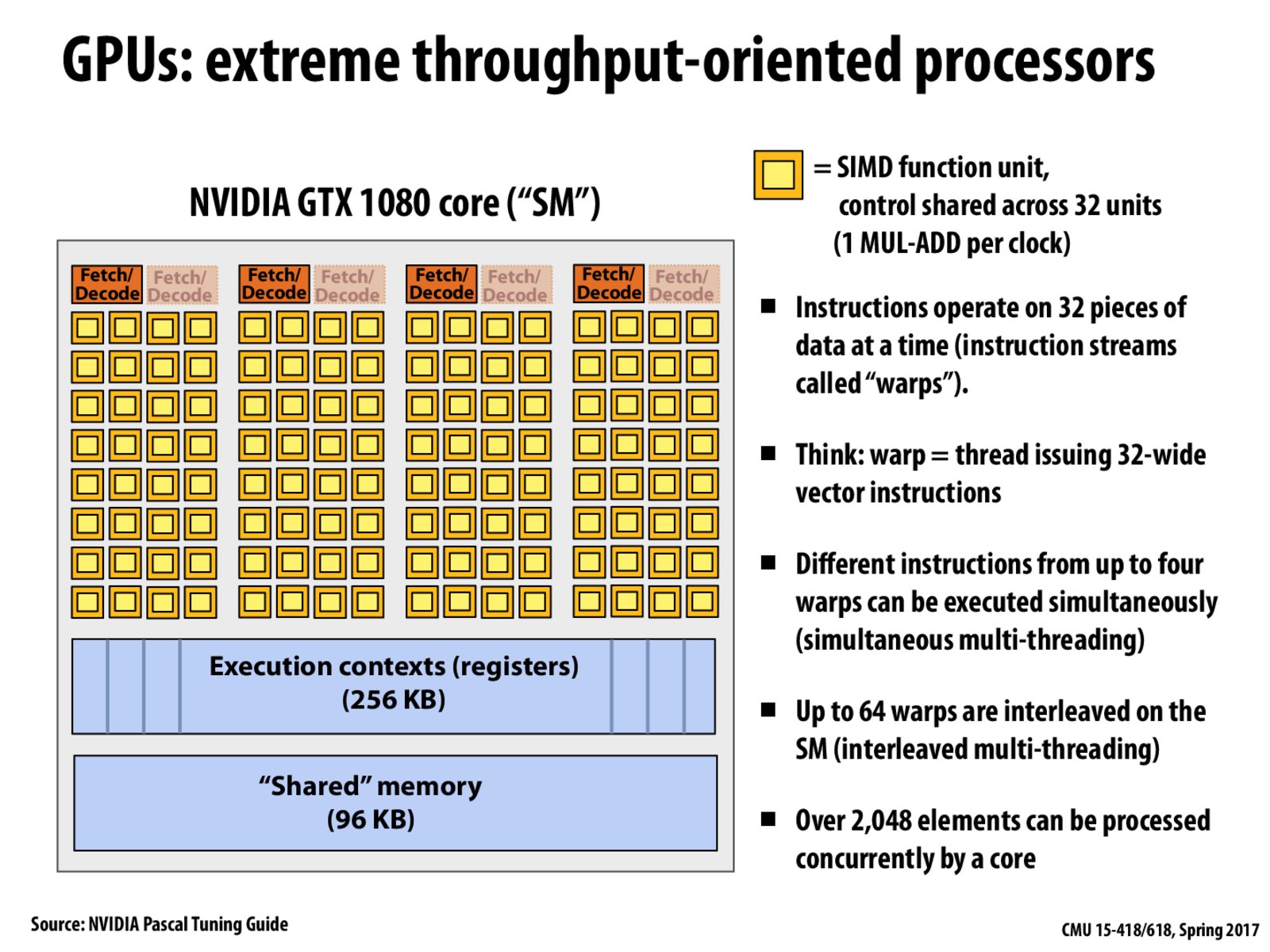
As a question, I know that GPUs are composed of streaming multiprocessors (SM), however I also know that NVIDIA and other GPU manufacturers like to claim that GPUs have a large number of 'cores'. Are the GPU cores they are referring to the same thing as the SIMD function units? My assumption is that they are probably the same, but I have not found any references to support or disprove that claim.
kayvonf
@metalbird. Yes, your assumption is correct. While a hardware architect could legitimately point out some notable differences between the implicit and explicit SIMD approaches, from a application-programmer's perspective, when writing SPMD-style code, each program instance/CUDA thread will get mapped to a vector lane in an array of SIMD ALUs. What NVIDIA refers to as "CUDA cores" are more-or-less in one-to-one correspondence with AVX vector lanes on an Intel CPU.
kayvonf
Point being: a 2,560 CUDA core GPU sounds a whole lot better than an eight-core CPU, and that's just good NVIDIA marketing.
-o4
How do we arrive at the number 64 for #wrap in interleaved multi-threading? Is it related to the 16 execution contexts? And why there are 2 Fetch/Decode per wrap?
paramecinm
@-o4 I think that may because 'each SIMD function unit is shared across 32 units' and '1 MUL-ADD per clock'. So there can be 32 * 2 = 64 instructions interleaved.
sampathchanda
Are the 2 Fetch/Decode units for executing 1MUL & 1ADD per clock ? Or is it because of some other reason ?
sampathchanda
Also, is there any specific reason for not showing L1 cache in this illustration ?
As a question, I know that GPUs are composed of streaming multiprocessors (SM), however I also know that NVIDIA and other GPU manufacturers like to claim that GPUs have a large number of 'cores'. Are the GPU cores they are referring to the same thing as the SIMD function units? My assumption is that they are probably the same, but I have not found any references to support or disprove that claim.
@metalbird. Yes, your assumption is correct. While a hardware architect could legitimately point out some notable differences between the implicit and explicit SIMD approaches, from a application-programmer's perspective, when writing SPMD-style code, each program instance/CUDA thread will get mapped to a vector lane in an array of SIMD ALUs. What NVIDIA refers to as "CUDA cores" are more-or-less in one-to-one correspondence with AVX vector lanes on an Intel CPU.
Point being: a 2,560 CUDA core GPU sounds a whole lot better than an eight-core CPU, and that's just good NVIDIA marketing.
How do we arrive at the number 64 for #wrap in interleaved multi-threading? Is it related to the 16 execution contexts? And why there are 2 Fetch/Decode per wrap?
@-o4 I think that may because 'each SIMD function unit is shared across 32 units' and '1 MUL-ADD per clock'. So there can be 32 * 2 = 64 instructions interleaved.
Are the 2 Fetch/Decode units for executing 1MUL & 1ADD per clock ? Or is it because of some other reason ?
Also, is there any specific reason for not showing L1 cache in this illustration ?