In the row-major array layout, cache lines may be split across different processors that are performing the computation, leading to more overhead in accessing the shared lines.
Arranging your array elements to be adjacent to each other within a block minimizes the shared cache lines and allows the processor to utilize more spatial locality, thereby also decreasing data access times.
firebb
Does 4D mean (block row id, block column id, row id in block, column id in block)?
Cake
Yes. The equivalent way of thinking about this using CUDA builtins is to first look at blockIdx, then threadIdx.
lfragago
I agree with jocelynh.
Additionally if we think in the context of shared memory in CUDA, we can put the whole block region in shared memory, and therefore have faster memory accesses than if we just had it in cache.
pdp
At the boundaries of the grid, we will still have the issue of fetching the immediate adjacent elements for the update!
1_1
In the block layout, we are just changing what i,j means in the address space. We achieve perfect spatial locality since all of the consecutive elements in memory are assigned to the same processor. Thus, now we have reduced both inherent communication and artifactual communication.
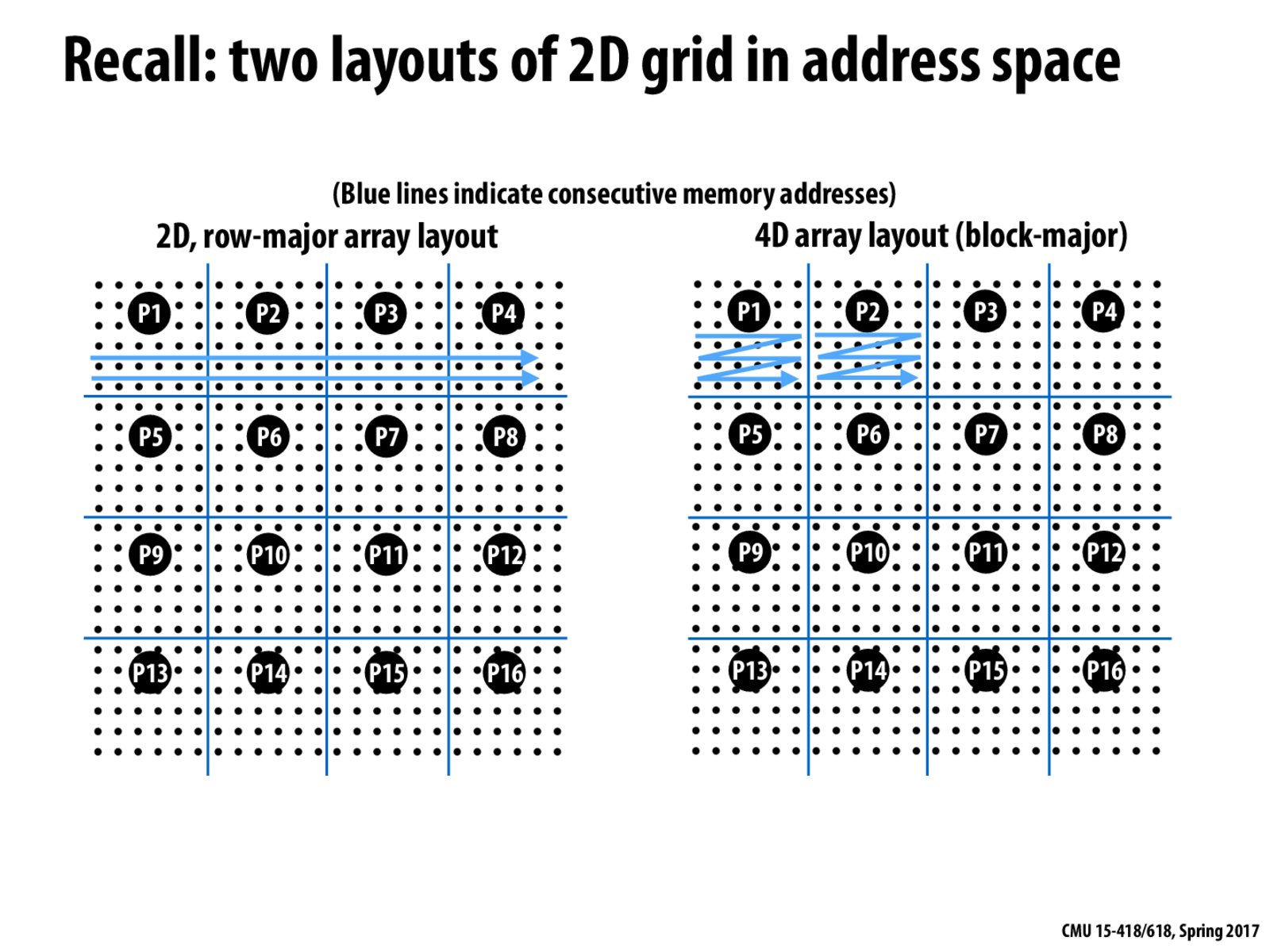
If I'm understanding this correctly:
In the row-major array layout, cache lines may be split across different processors that are performing the computation, leading to more overhead in accessing the shared lines.
Arranging your array elements to be adjacent to each other within a block minimizes the shared cache lines and allows the processor to utilize more spatial locality, thereby also decreasing data access times.
Does 4D mean (block row id, block column id, row id in block, column id in block)?
Yes. The equivalent way of thinking about this using CUDA builtins is to first look at blockIdx, then threadIdx.
I agree with jocelynh.
Additionally if we think in the context of shared memory in CUDA, we can put the whole block region in shared memory, and therefore have faster memory accesses than if we just had it in cache.
At the boundaries of the grid, we will still have the issue of fetching the immediate adjacent elements for the update!
In the block layout, we are just changing what i,j means in the address space. We achieve perfect spatial locality since all of the consecutive elements in memory are assigned to the same processor. Thus, now we have reduced both inherent communication and artifactual communication.