This seems like a good use case for augmented trees as taught in 15210. Storing additional information (i.e. total mass and center of mass) of each subtree could potentially reduce redundant computation.
emt
Since the amount of work done is proportional to the distribution of the particles, a tree data structure works well. Whenever a node corresponds to a small enough mass, we can stop traversing down that branch of the tree and treat it as a single mass.
nemo
The fan-out for the tree structure will increase exponentially with the number of dimensions. Would it make sense to shift to a more efficient structure like KD-Trees in that scenario?
crow
Since for cosmological simulations, the dimension is pretty much always fixed at 3, octrees work fine
pdp
How is expected number of nodes touched, (lg N / theta^2) ?
CSGuy
For theta > 1 it isn't super hard because at any square, only one of the 4 subsquares won't satisfy L/D < theta. So assuming a relatively even distribution of particles we cut the number of particles we're considering by a fourth at each step, leading to O(log(n)) number of nodes visited. For theta < 1 I actually couldn't find the answer anywhere.
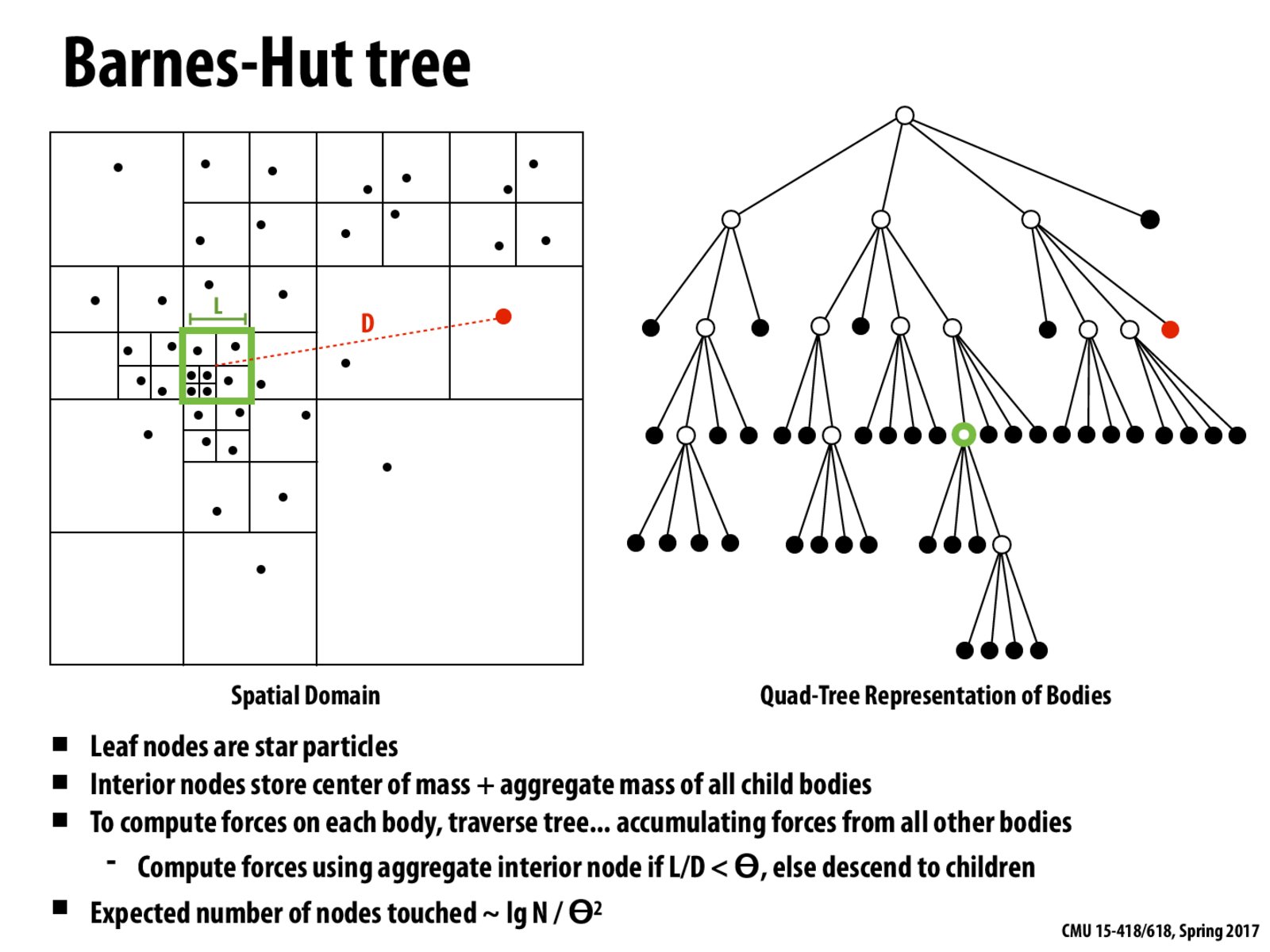
This seems like a good use case for augmented trees as taught in 15210. Storing additional information (i.e. total mass and center of mass) of each subtree could potentially reduce redundant computation.
Since the amount of work done is proportional to the distribution of the particles, a tree data structure works well. Whenever a node corresponds to a small enough mass, we can stop traversing down that branch of the tree and treat it as a single mass.
The fan-out for the tree structure will increase exponentially with the number of dimensions. Would it make sense to shift to a more efficient structure like KD-Trees in that scenario?
Since for cosmological simulations, the dimension is pretty much always fixed at 3, octrees work fine
How is expected number of nodes touched, (lg N / theta^2) ?
For theta > 1 it isn't super hard because at any square, only one of the 4 subsquares won't satisfy L/D < theta. So assuming a relatively even distribution of particles we cut the number of particles we're considering by a fourth at each step, leading to O(log(n)) number of nodes visited. For theta < 1 I actually couldn't find the answer anywhere.