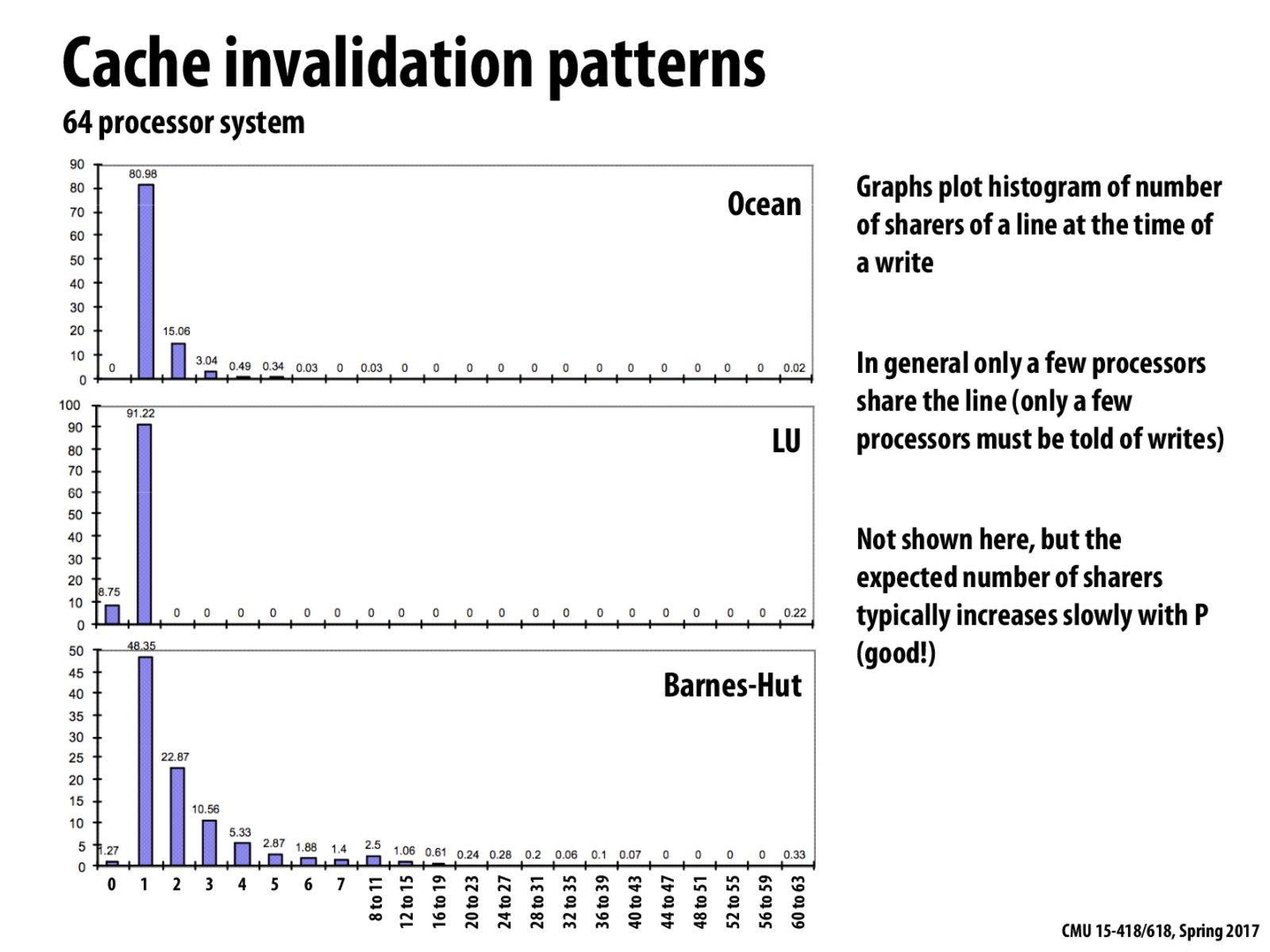
Is the time spent communicating invalidation/ack messages linear with respect to the number of sharers? If so, it might be informative to adjust the histogram with respect to time spent on writes instead of number of writes. In particular, Barnes-Hut would have a much slower drop-off on such a graph.
holard
Is it fair to say that this relationship generally follows a power law?
pdp
@holard: Since the distribution is dependent on the problem we are trying to solve, there is no one single distribution. Statistically, for most commonly studied problems, broadcasting doesn't seem to be necessary as the distributions "appears/looks" like a power law. Please correct me if I am wrong.
chenh1
What this graph means and what each axis represent?
ZoSo
The x-axis represents the number of processors holding a cache line. The y-axis represents the cache lines (cache lines 0 - N). So the topmost graph (ocean) says that 1 processor holds on an average 90 cache lines for writes, and 2 processors will have about 15 lines. So, most of the cache lines are held only by a few processors at a time, so the processors do not have to communicate to very many processors to invalidate and flush their cache lines. (Some one correct me if my interpretation of the axes are wrong).
pk267
(Discussed in class) Q: How will the graph change of there are large number of reads for a particular data line and hardly any writes? And what scheme would be better to deal with such a case - Directory, or Snooping?
Ans: There will be a long bar towards the right, indicating that large number of processors have it in their cache lines. Snooping protocol would be better because reading a cache line does not need any other message transactions. While Snooping on the other hand would require sending a message to all the other processors in the system every time a new request comes in. Thus, DIrectory is better.
pht
Is there a reason why there is the largest number of cache lines on processor 1 instead of processor 0? And why in LU and Barnes Hut, there's some on processor 0 but the majority is on processor 1?
kayvonf
@pht. The x-axis of the graph is not specific processors, it is the number of processors sharing a line on a write. In other words, the number of processors that need need to invalidate their copy of the line to allow the writer to have exclusive access.
o_o
It seems that directory based cache coherence leads to less communication between processors as processors don't need to notify many other processors to invalidate their cache lines. Does this mean that directory based cache coherence is more efficient?
fxffx
From this diagram, we can see that in most programs, the number of sharers for a line at the time of a write. So maybe we should optimize for common case here.
Is the time spent communicating invalidation/ack messages linear with respect to the number of sharers? If so, it might be informative to adjust the histogram with respect to time spent on writes instead of number of writes. In particular, Barnes-Hut would have a much slower drop-off on such a graph.
Is it fair to say that this relationship generally follows a power law?
@holard: Since the distribution is dependent on the problem we are trying to solve, there is no one single distribution. Statistically, for most commonly studied problems, broadcasting doesn't seem to be necessary as the distributions "appears/looks" like a power law. Please correct me if I am wrong.
What this graph means and what each axis represent?
The x-axis represents the number of processors holding a cache line. The y-axis represents the cache lines (cache lines 0 - N). So the topmost graph (ocean) says that 1 processor holds on an average 90 cache lines for writes, and 2 processors will have about 15 lines. So, most of the cache lines are held only by a few processors at a time, so the processors do not have to communicate to very many processors to invalidate and flush their cache lines. (Some one correct me if my interpretation of the axes are wrong).
(Discussed in class) Q: How will the graph change of there are large number of reads for a particular data line and hardly any writes? And what scheme would be better to deal with such a case - Directory, or Snooping?
Ans: There will be a long bar towards the right, indicating that large number of processors have it in their cache lines. Snooping protocol would be better because reading a cache line does not need any other message transactions. While Snooping on the other hand would require sending a message to all the other processors in the system every time a new request comes in. Thus, DIrectory is better.
Is there a reason why there is the largest number of cache lines on processor 1 instead of processor 0? And why in LU and Barnes Hut, there's some on processor 0 but the majority is on processor 1?
@pht. The x-axis of the graph is not specific processors, it is the number of processors sharing a line on a write. In other words, the number of processors that need need to invalidate their copy of the line to allow the writer to have exclusive access.
It seems that directory based cache coherence leads to less communication between processors as processors don't need to notify many other processors to invalidate their cache lines. Does this mean that directory based cache coherence is more efficient?
From this diagram, we can see that in most programs, the number of sharers for a line at the time of a write. So maybe we should optimize for common case here.