Interesting trick to reduce number of parameters:
If there are lot of fully connected layers, like in VGGNet, the number of parameters to be trained are significantly higher than conv layers. So many recent networks try to avoid FC layers and mimic the same through multiple different sized conv layers. (Eg. GoogleNet)
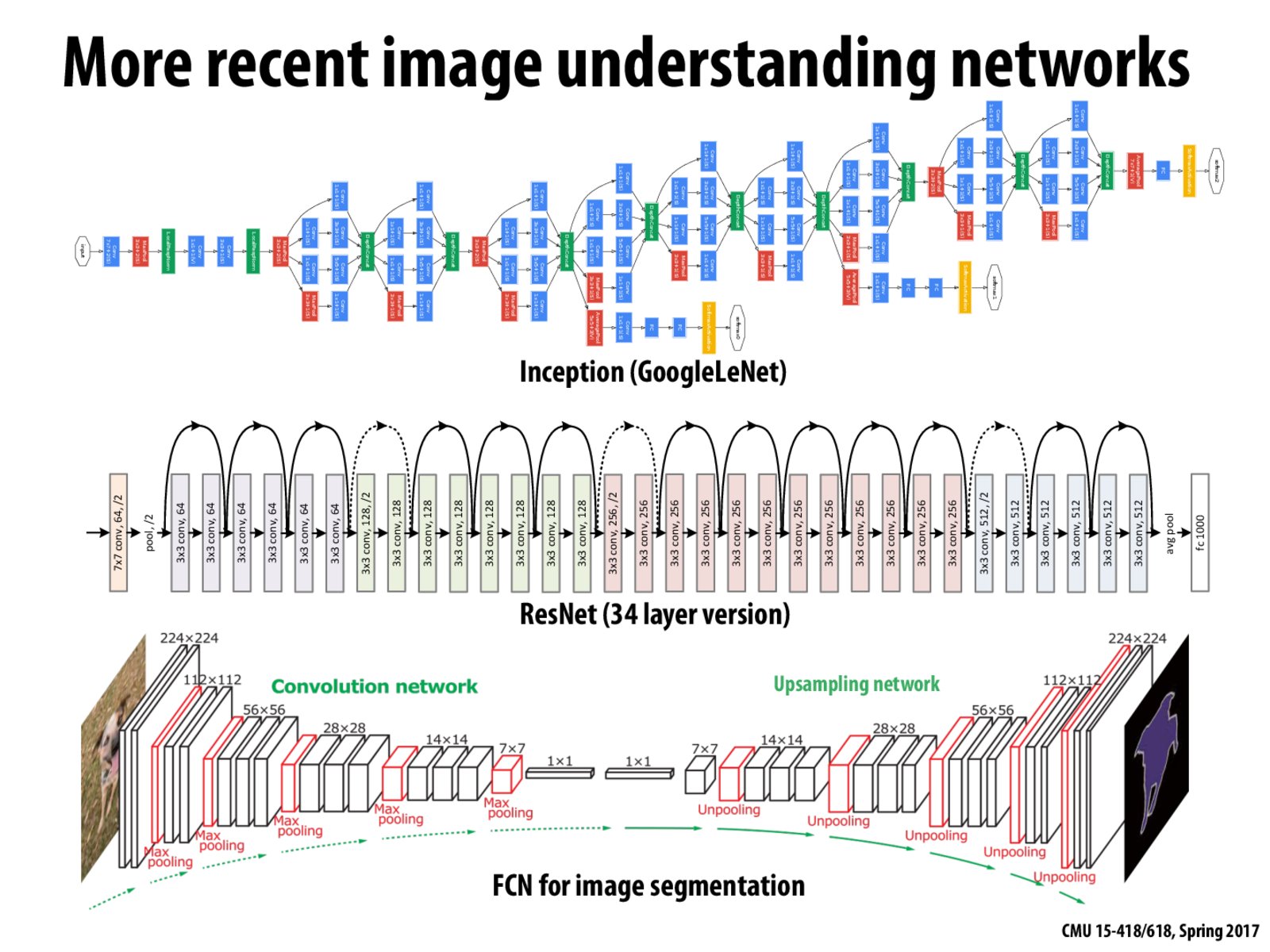
Inception: https://arxiv.org/abs/1409.4842
ResNet: https://arxiv.org/abs/1512.03385
FCN: https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdf
Interesting trick to reduce number of parameters: If there are lot of fully connected layers, like in VGGNet, the number of parameters to be trained are significantly higher than conv layers. So many recent networks try to avoid FC layers and mimic the same through multiple different sized conv layers. (Eg. GoogleNet)