This implementation is nice in that we no longer need to barrier and wait for all nodes to finish calculations. What people found was that the solution was still good enough if you update local copy of parameters based on only partially complete gradient information. I believe that the reason for this is that the gradient information on each node should be similar. So we are able to find the optimal training points with less synchronization, without losing accurate solutions.
atadkase
@Metalbird, I don't think that the gradient information on each node will be similar. It is rather the question of throwing more compute at the problem and taking the risk of using more iterations in order to converge, rather than waiting to synchronize and waste those cycles in communication and in barriers.
kapalani
Why can't the local sub gradients be updated without involving the parameter server? Is it to account for updates to parameters sent by the other workers?
muchanon
I believe it is because you want the local subgradients from other nodes to also update the parameters. If those other nodes have not finished, like in this case, then you just accept that and use your own, but as shown on the next slide, when the next node finishes, they want to update the v1 parameters not the v0 parameters that they have locally.
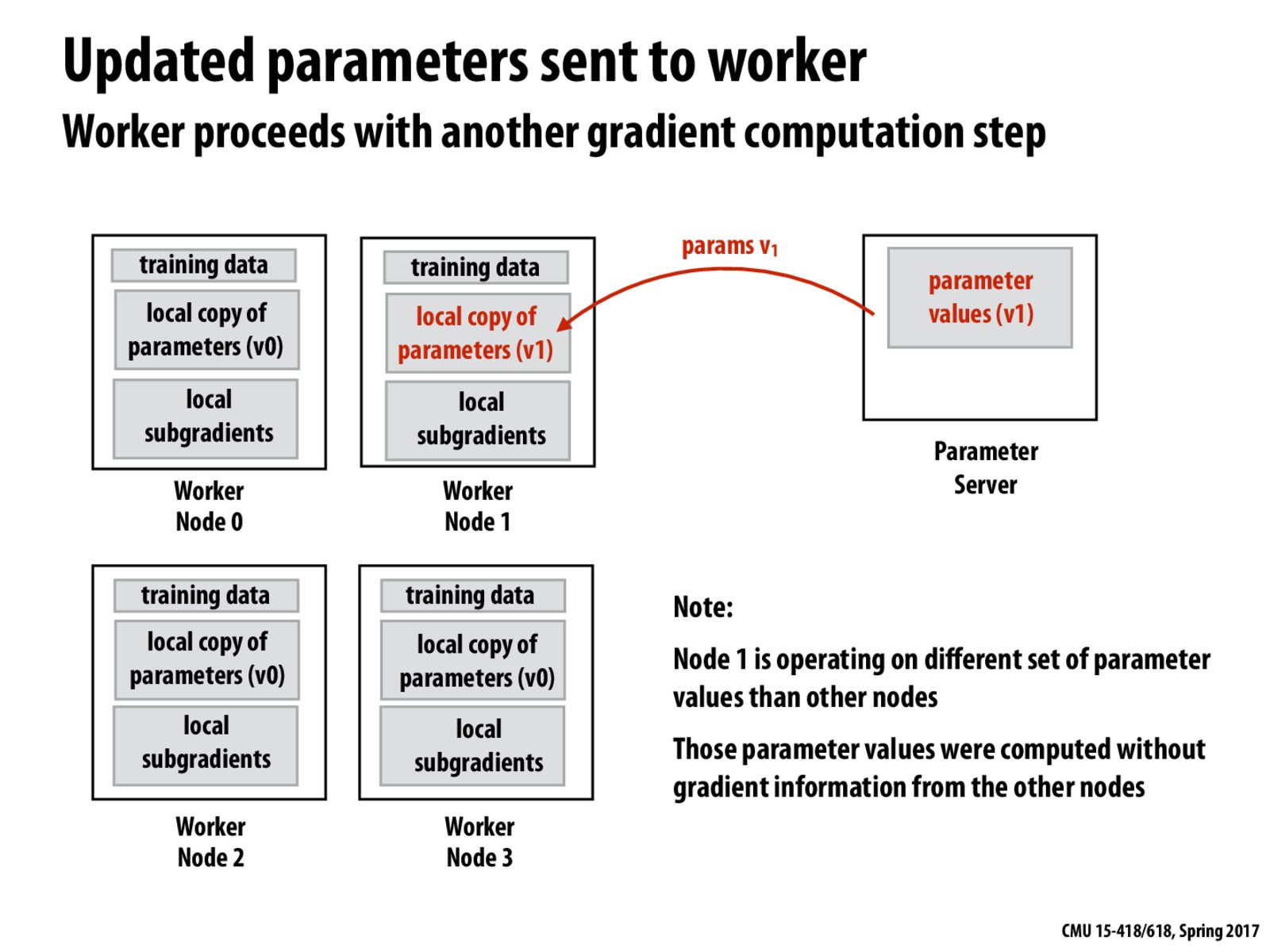
This implementation is nice in that we no longer need to barrier and wait for all nodes to finish calculations. What people found was that the solution was still good enough if you update local copy of parameters based on only partially complete gradient information. I believe that the reason for this is that the gradient information on each node should be similar. So we are able to find the optimal training points with less synchronization, without losing accurate solutions.
@Metalbird, I don't think that the gradient information on each node will be similar. It is rather the question of throwing more compute at the problem and taking the risk of using more iterations in order to converge, rather than waiting to synchronize and waste those cycles in communication and in barriers.
Why can't the local sub gradients be updated without involving the parameter server? Is it to account for updates to parameters sent by the other workers?
I believe it is because you want the local subgradients from other nodes to also update the parameters. If those other nodes have not finished, like in this case, then you just accept that and use your own, but as shown on the next slide, when the next node finishes, they want to update the v1 parameters not the v0 parameters that they have locally.