I am wondering if this kind of asynchronous update will make the training never converge.
crow
there are provable convergence guarantees for asynchronous sgd as well
pdp
It could so happen that the number of steps taken (time taken to reach optima) by SGD might increase given we are not considering the entire training datastep for each update but the parallelization will overcompensate the additional time for convergence.
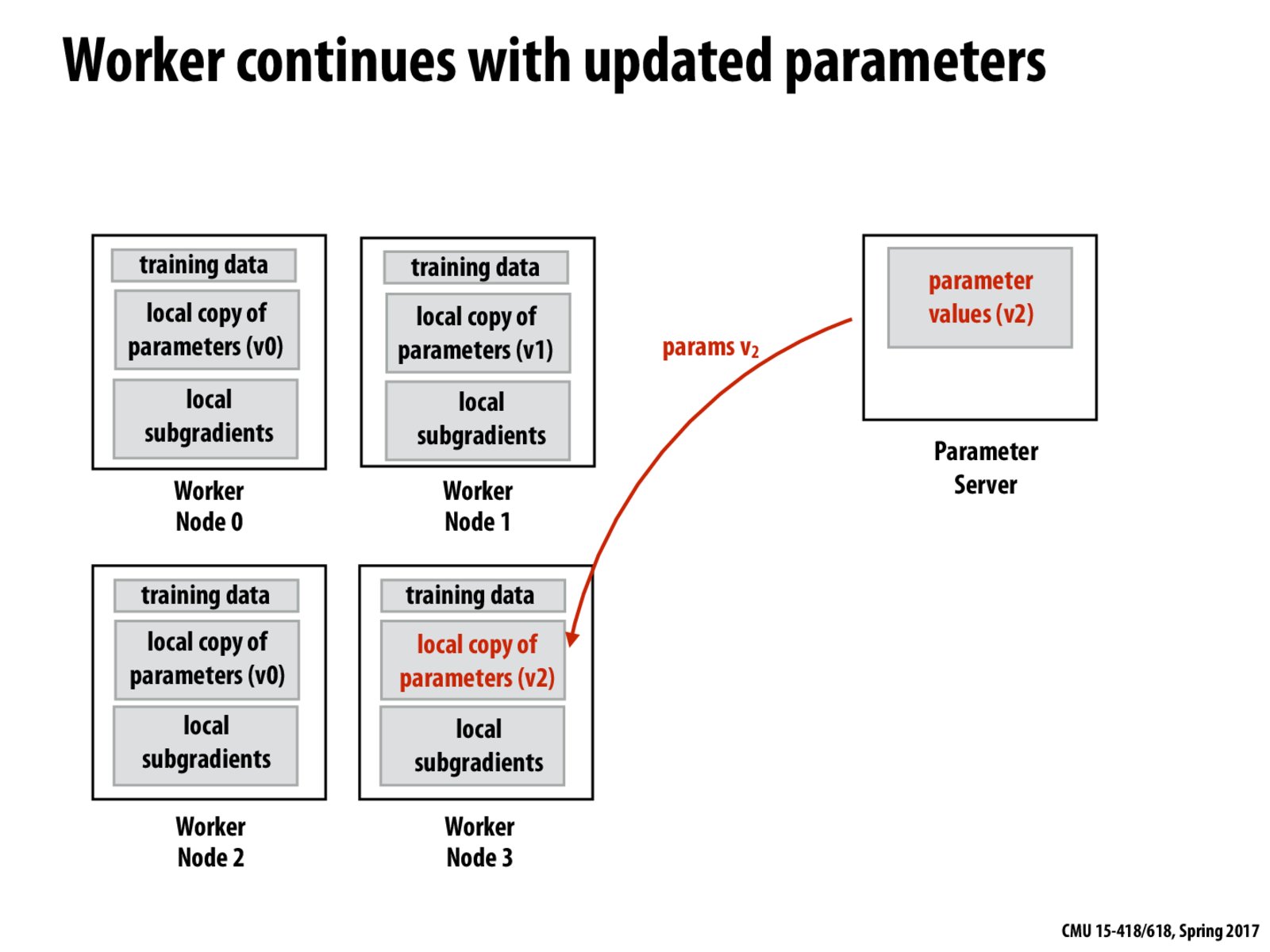
I am wondering if this kind of asynchronous update will make the training never converge.
there are provable convergence guarantees for asynchronous sgd as well
It could so happen that the number of steps taken (time taken to reach optima) by SGD might increase given we are not considering the entire training datastep for each update but the parallelization will overcompensate the additional time for convergence.