The other option here was to make this cut vertical but that would be an inefficient implementation for 2 major reasons -
The calculations are sequential layerwise, so the second half will wait for the first half before it can start.
The memory load distribution will be uneven as the number of parameters is higher for the second part due to fully connected layers.
Abandon
For some machine learning algorithms such as LDA, model parallelism is brought out automatically by data parallelism. For deep neural network, data and model (parameters) are fully connected. So, model parallelism is considered individually. Project Adam discusses how to do distributed model parallelism among a cluster.
hdd
The problems associated with data can be solved by attempting weight sharing and deep compression along with a sparse matrix - sparse vector multiplication. This is what the EIE paper aims to implement in the EIE ASIC. In essence, the memory transfers are the most dominant part of the neural network latency and due to higher number of model parameters, this can scale badly when we want to train a higher network. This is a highly explored research problem in the deep neural network systems community.
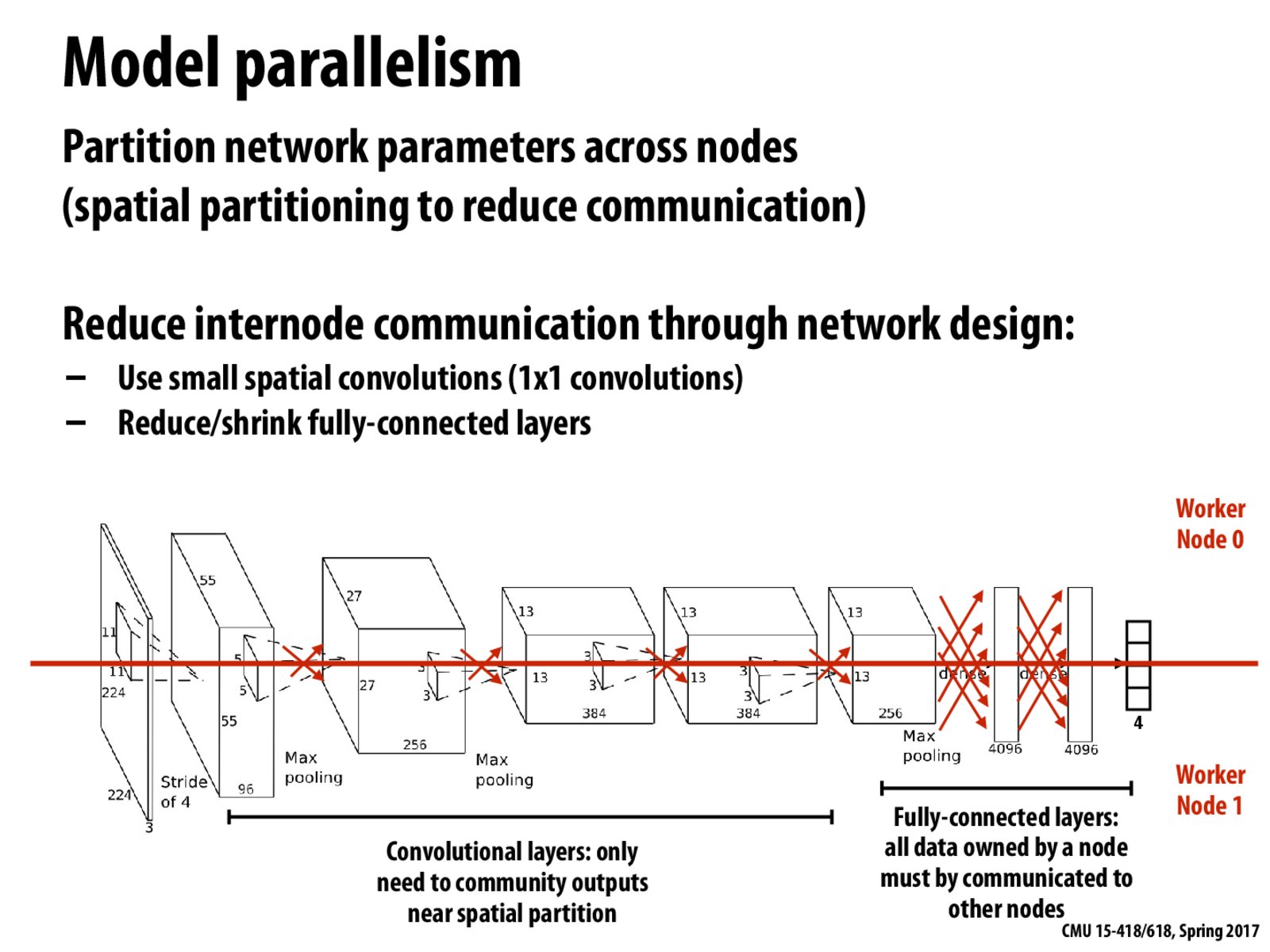
The other option here was to make this cut vertical but that would be an inefficient implementation for 2 major reasons -
For some machine learning algorithms such as LDA, model parallelism is brought out automatically by data parallelism. For deep neural network, data and model (parameters) are fully connected. So, model parallelism is considered individually. Project Adam discusses how to do distributed model parallelism among a cluster.
The problems associated with data can be solved by attempting weight sharing and deep compression along with a sparse matrix - sparse vector multiplication. This is what the EIE paper aims to implement in the EIE ASIC. In essence, the memory transfers are the most dominant part of the neural network latency and due to higher number of model parameters, this can scale badly when we want to train a higher network. This is a highly explored research problem in the deep neural network systems community.