The idea here is that we can avoid the expensive synchronization for frequent parameter updates if we are okay with having some amount of "fuzziness" in the updates, as we ignore locks and simply push updates to the shared set of gradients whenever a mini-batch is finished.
This means that we might end up missing some updates or some core(s) may be working with slightly outdated parameters, but the differences should not be too large and the parameters will converge eventually anyway.
sushi
Sometimes, using asynchronous update can add randomness to the model and can have better performance though its convergence lacks guarantees.
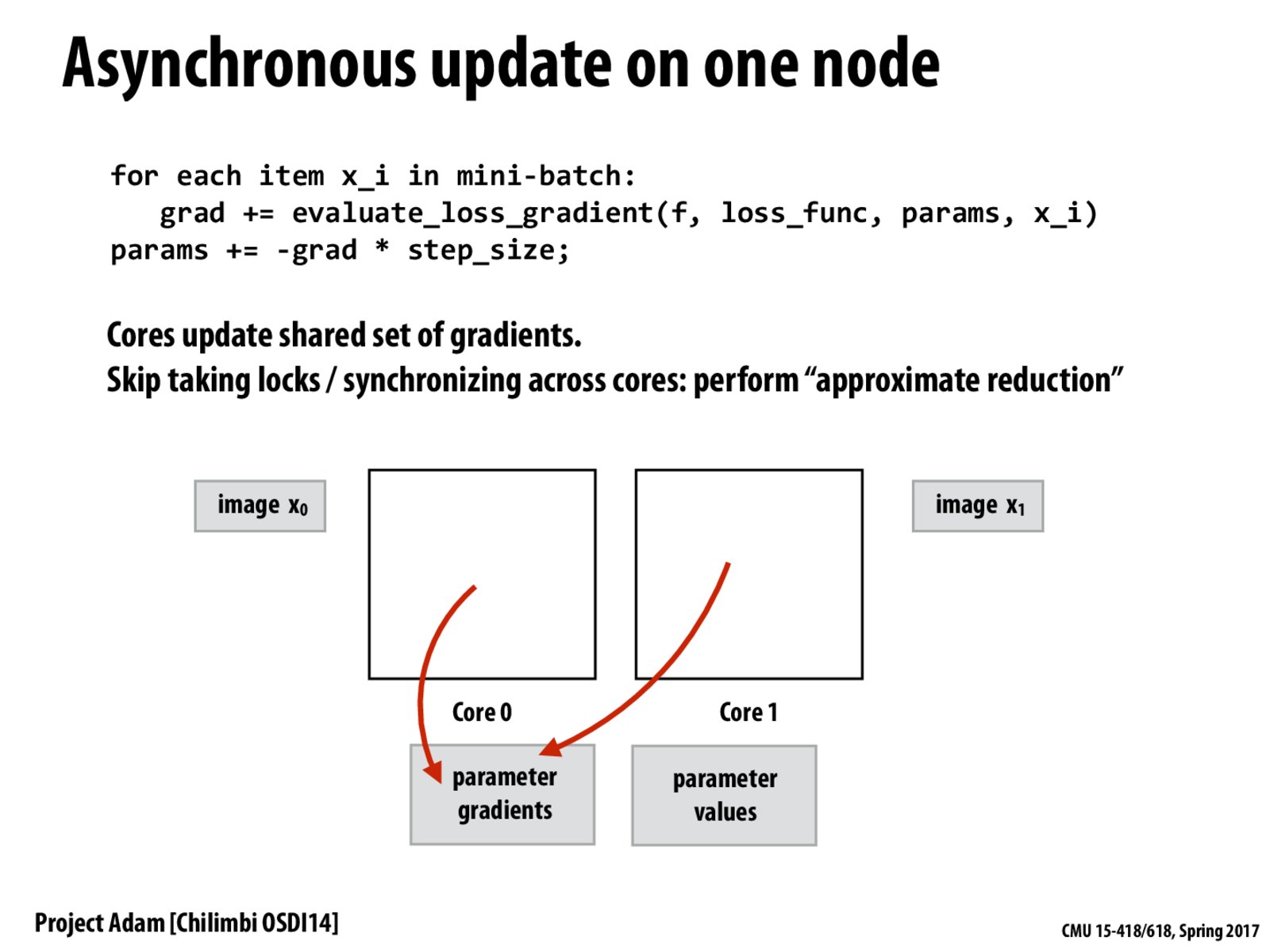
The idea here is that we can avoid the expensive synchronization for frequent parameter updates if we are okay with having some amount of "fuzziness" in the updates, as we ignore locks and simply push updates to the shared set of gradients whenever a mini-batch is finished.
This means that we might end up missing some updates or some core(s) may be working with slightly outdated parameters, but the differences should not be too large and the parameters will converge eventually anyway.
Sometimes, using asynchronous update can add randomness to the model and can have better performance though its convergence lacks guarantees.