One possible explanation for the super-linear speed-up on the right might be that the entire working set fit in the cache.
jedi
@ask, you're likely right. The Liszt paper says: The FEM application experiences super-linear scaling from 256 to 512 cores, as the working set of the algorithm becomes small enough to fit entirely into L3 cache. ... FEM is a different simulation that had a more pronounced superlinear speedup.
Other observations from the same paper that relate to our course:
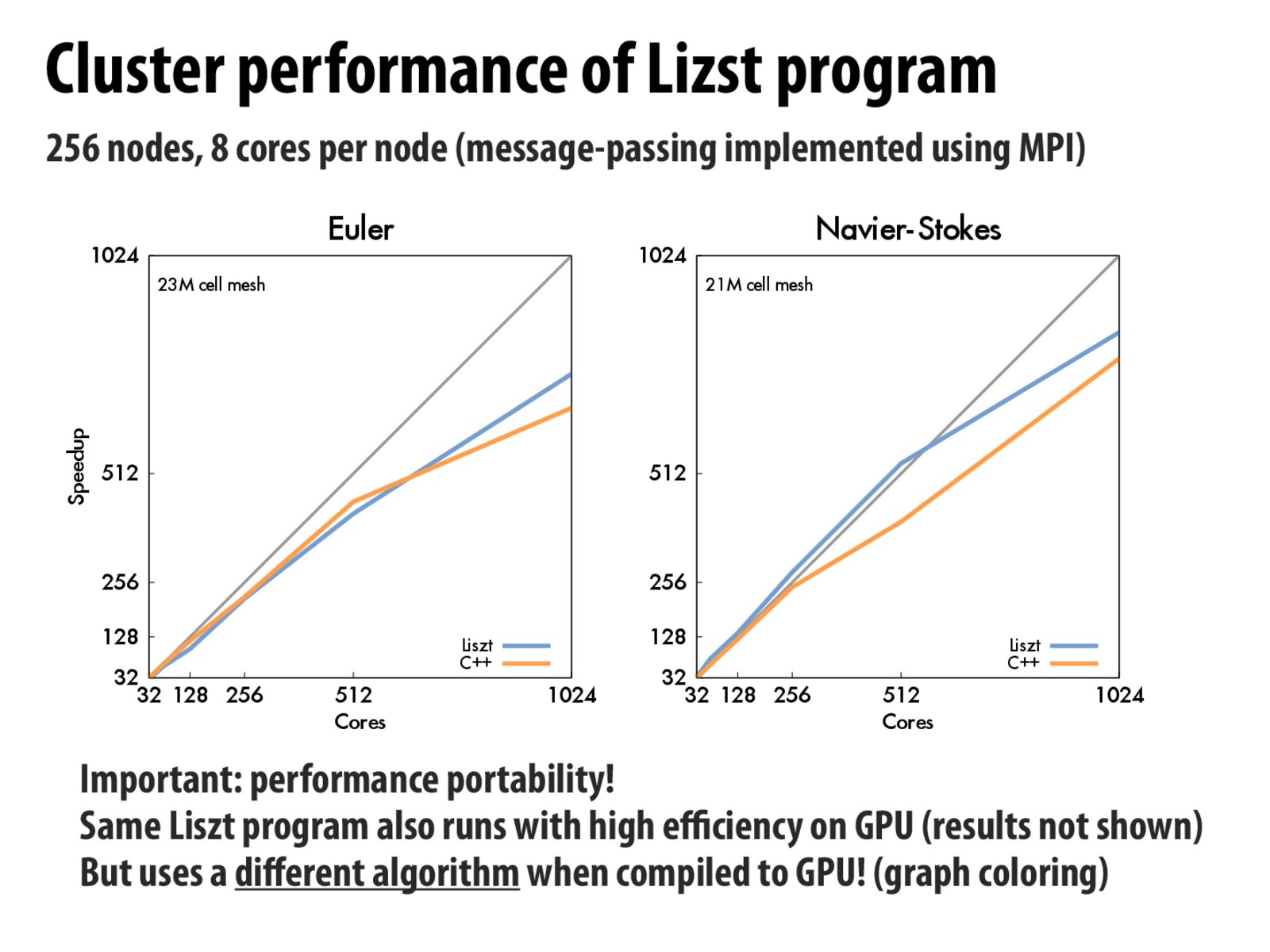
For the Euler simulation, Liszt scales slightly better than the reference C++ code because the reference application’s framework hard-coded communication of two fields that were never used. Liszt discovered only the fields necessary for the algorithm and communicated less.
We notice that both the Liszt and C++ Euler and NavierStokes applications stop scaling after 1024 cores. Scaling performance on a cluster is limited by the amount of data per node, since the communication across boundaries limits performance if too little computation occurs in the interior of the partition. ... Given a larger mesh we expect these applications to continue scaling.
sampathchanda
The gray line indicates the maximum linear speedup that can be achieved. And hence in the second graph, Liszt program is showing a super-linear speedup due to temporal and spatial locality of data, as mentioned by ask.
One possible explanation for the super-linear speed-up on the right might be that the entire working set fit in the cache.
@ask, you're likely right. The Liszt paper says: The FEM application experiences super-linear scaling from 256 to 512 cores, as the working set of the algorithm becomes small enough to fit entirely into L3 cache. ... FEM is a different simulation that had a more pronounced superlinear speedup.
Other observations from the same paper that relate to our course:
The gray line indicates the maximum linear speedup that can be achieved. And hence in the second graph, Liszt program is showing a super-linear speedup due to temporal and spatial locality of data, as mentioned by ask.