By using vector ops and vector registers, many fragments can be processed through shader functions. In modern GPUs, 16 to 64 fragments share an instruction stream.
To achieve high-throughput execution, use many "slimmed down" cores and run them in parallel, pack cores full of ALUs, and avoid latency stalls by interleaving execution between fragment groups. These concepts are similar to when we discussed threads.
For more information: refer to https://www.cs.cmu.edu/afs/cs/academic/class/15462-f11/www/lec_slides/lec19.pdf.
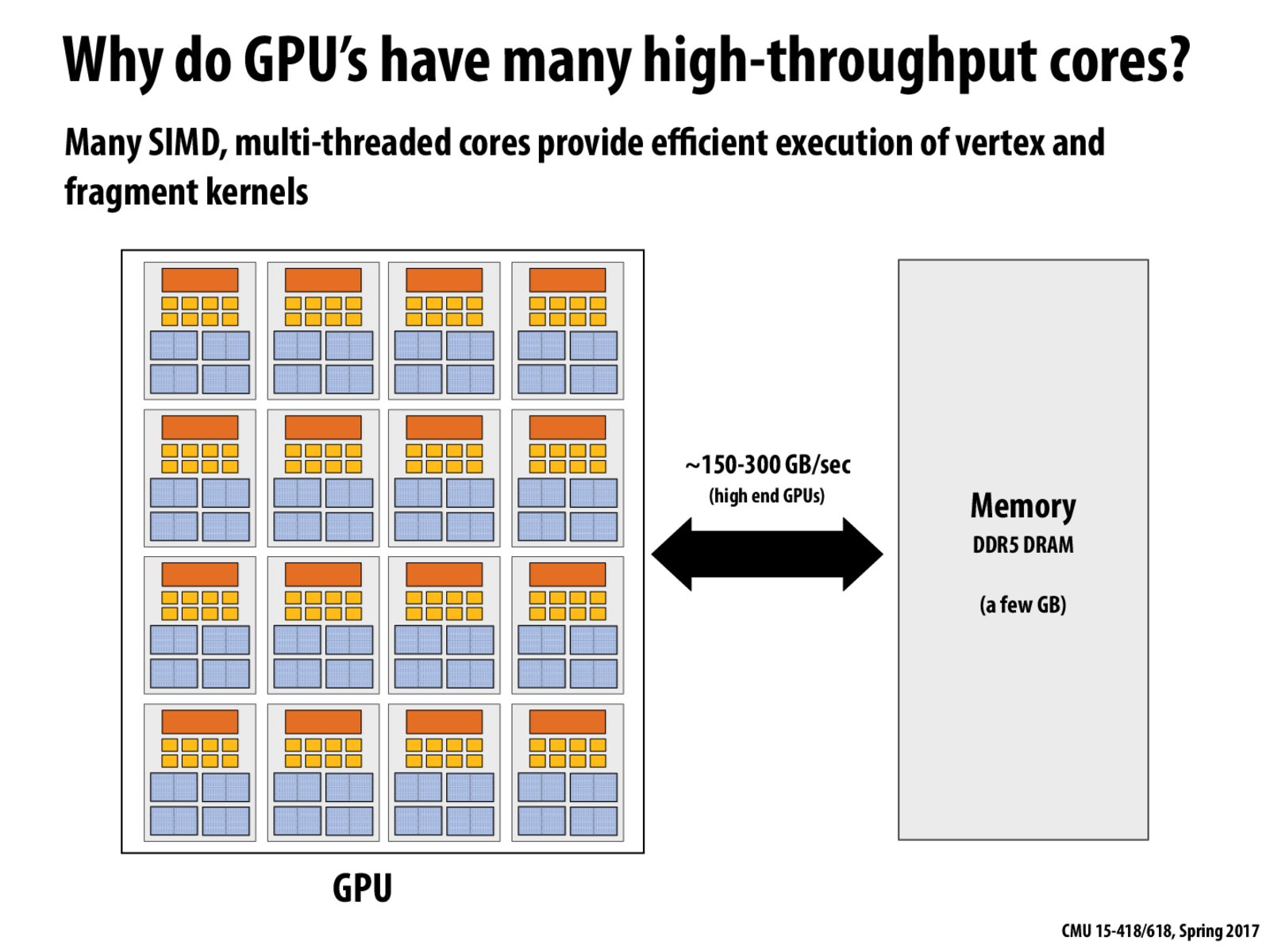
By using vector ops and vector registers, many fragments can be processed through shader functions. In modern GPUs, 16 to 64 fragments share an instruction stream.
To achieve high-throughput execution, use many "slimmed down" cores and run them in parallel, pack cores full of ALUs, and avoid latency stalls by interleaving execution between fragment groups. These concepts are similar to when we discussed threads.
For more information: refer to https://www.cs.cmu.edu/afs/cs/academic/class/15462-f11/www/lec_slides/lec19.pdf.