Suppose thread 71 is in block(2, 1), and its thread id in block(2, 1) is (3, 2).
blockDim.x which represents the number of threads per block in x dimension, and for the pervious question the value of blockDim.x is 4, for the same reason, the value of blockDim.y is 3. The overall grid thread id is:
int i = 2 * 4 + 3 = 11
int j = 1 * 3 + 2 = 5
So it is (11, 5).
paracon
global specifier can be considered to be functioning like the export specifier in ISPC, the one difference being, that tasks (which can be considered equivalent to blocks) were not launched when the function was called. Here, a grid of CUDA threads (number of blocks times number of threads per block) are launched together.
kapalani
Just to confirm, Nx x Ny array means 12 columns and 6 rows (as opposed to the way I thought of it first which was 12 rows and 6 columns) in being consistent with the x and y dimensions being used in the previous slide and each thread processes one element of the array?
From the array accesses it looks like Block 0,0 will access A[0-2][0-3], Block 1,0 will access [0-2][4-7] and Block 2,0 will access A[0-2][8-11] and so on
sreevisp
@kapalani: Yes, you're right. It's a bit confusing to think about, especially with the A[Ny][Nx] syntax, but based on the previous slide we should be moving column-wise and then row-wise. I suppose we could arbitrarily transpose the diagram from the previous slide and then the picture would match your initial intuition, so the exact convention we choose shouldn't be relevant as long as it's consistent.
bschmuck
Why was the keyword global chosen to specify a CUDA function?
annag
@bschmuck: A CUDA function can be accessed from both the host and the CUDA device, so maybe they used the keyword global to reflect that it's "globally" accessible?
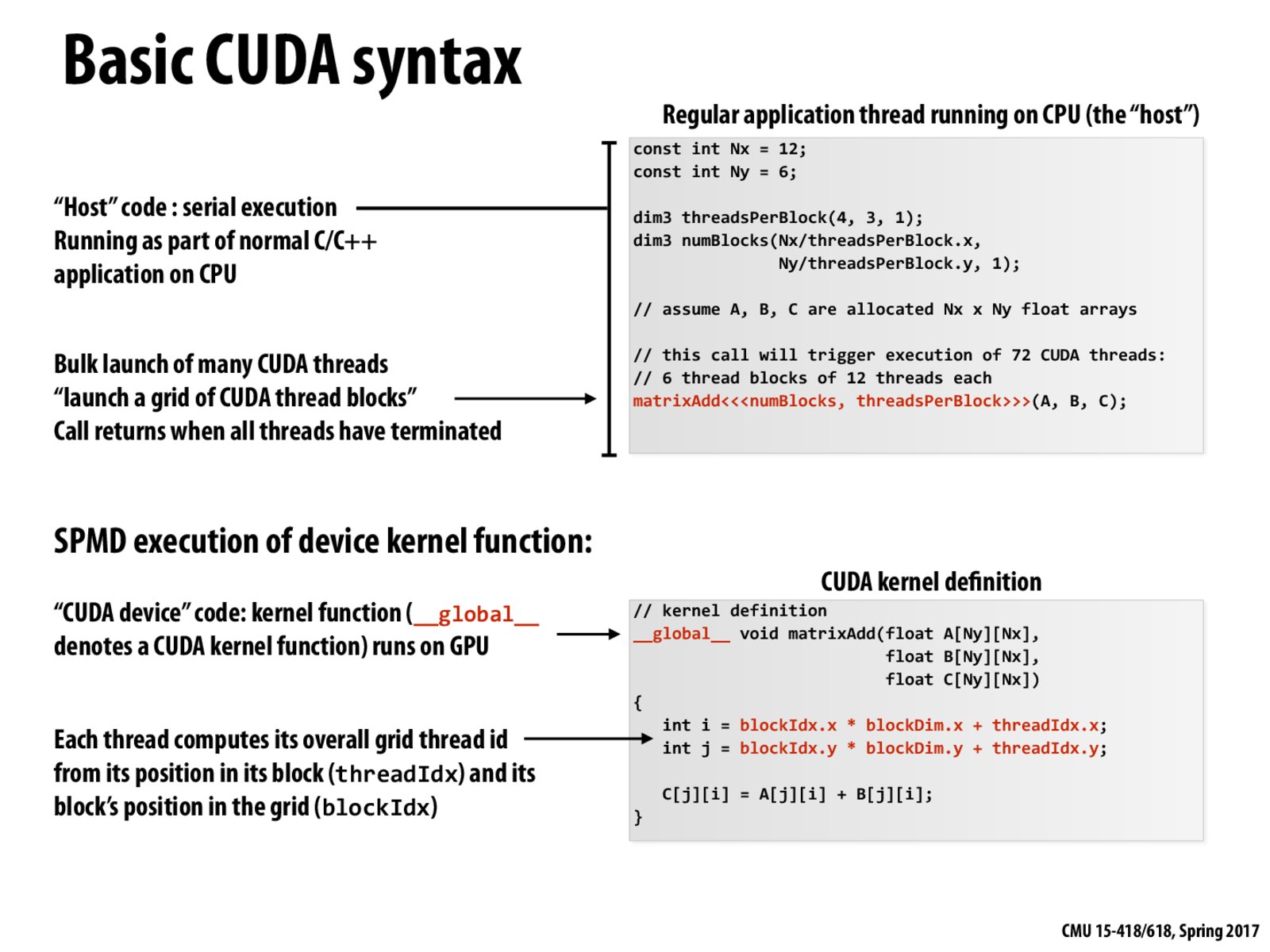
Suppose thread 71 is in block(2, 1), and its thread id in block(2, 1) is (3, 2). blockDim.x which represents the number of threads per block in x dimension, and for the pervious question the value of blockDim.x is 4, for the same reason, the value of blockDim.y is 3. The overall grid thread id is: int i = 2 * 4 + 3 = 11 int j = 1 * 3 + 2 = 5 So it is (11, 5).
global specifier can be considered to be functioning like the export specifier in ISPC, the one difference being, that tasks (which can be considered equivalent to blocks) were not launched when the function was called. Here, a grid of CUDA threads (number of blocks times number of threads per block) are launched together.
Just to confirm, Nx x Ny array means 12 columns and 6 rows (as opposed to the way I thought of it first which was 12 rows and 6 columns) in being consistent with the x and y dimensions being used in the previous slide and each thread processes one element of the array?
From the array accesses it looks like Block 0,0 will access A[0-2][0-3], Block 1,0 will access [0-2][4-7] and Block 2,0 will access A[0-2][8-11] and so on
@kapalani: Yes, you're right. It's a bit confusing to think about, especially with the A[Ny][Nx] syntax, but based on the previous slide we should be moving column-wise and then row-wise. I suppose we could arbitrarily transpose the diagram from the previous slide and then the picture would match your initial intuition, so the exact convention we choose shouldn't be relevant as long as it's consistent.
Why was the keyword global chosen to specify a CUDA function?
@bschmuck: A CUDA function can be accessed from both the host and the CUDA device, so maybe they used the keyword global to reflect that it's "globally" accessible?