I guess after the control transfers to the CUDA threads and before it returns to the host, the OS may do context switch and make other threads run in CPU?
apk
@hzxa21 yeah, OS does context switches all the time, many times per second.
kayvonf
@hzxa21. Actually, to be precise, by default the CUDA kernel launch executes asynchronously with the calling host thread. (Ensuring the kernel launch has actually completed can be done by calling cudaThreadSynchronize() from the host, which returns only when all prior CUDA kernel launches are complete.)
kayvonf
Question: Why is it most efficient for the CUDA thread block size to be a multiple of 32?
The processor has 32-wide SIMD vector lanes (and 32 threads can thus fit into 1 warp). So, having the number of threads as a multiple of 32 in a thread block would have the most efficient utilization of all the vector lanes in an execution unit.
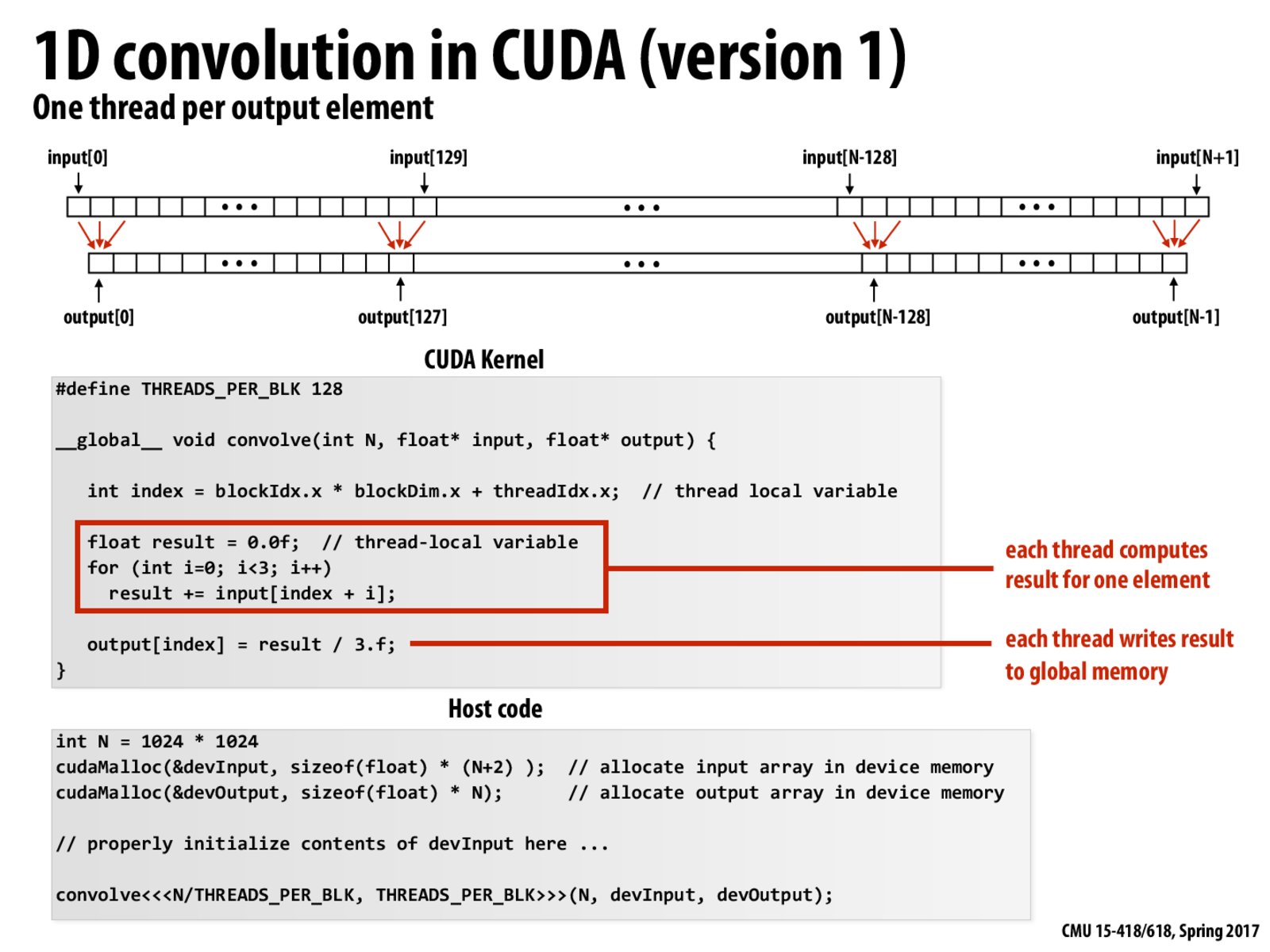
I guess after the control transfers to the CUDA threads and before it returns to the host, the OS may do context switch and make other threads run in CPU?
@hzxa21 yeah, OS does context switches all the time, many times per second.
@hzxa21. Actually, to be precise, by default the CUDA kernel launch executes asynchronously with the calling host thread. (Ensuring the kernel launch has actually completed can be done by calling
cudaThreadSynchronize()from the host, which returns only when all prior CUDA kernel launches are complete.)Question: Why is it most efficient for the CUDA thread block size to be a multiple of 32?
(Hint: see slide 60.)
The processor has 32-wide SIMD vector lanes (and 32 threads can thus fit into 1 warp). So, having the number of threads as a multiple of 32 in a thread block would have the most efficient utilization of all the vector lanes in an execution unit.