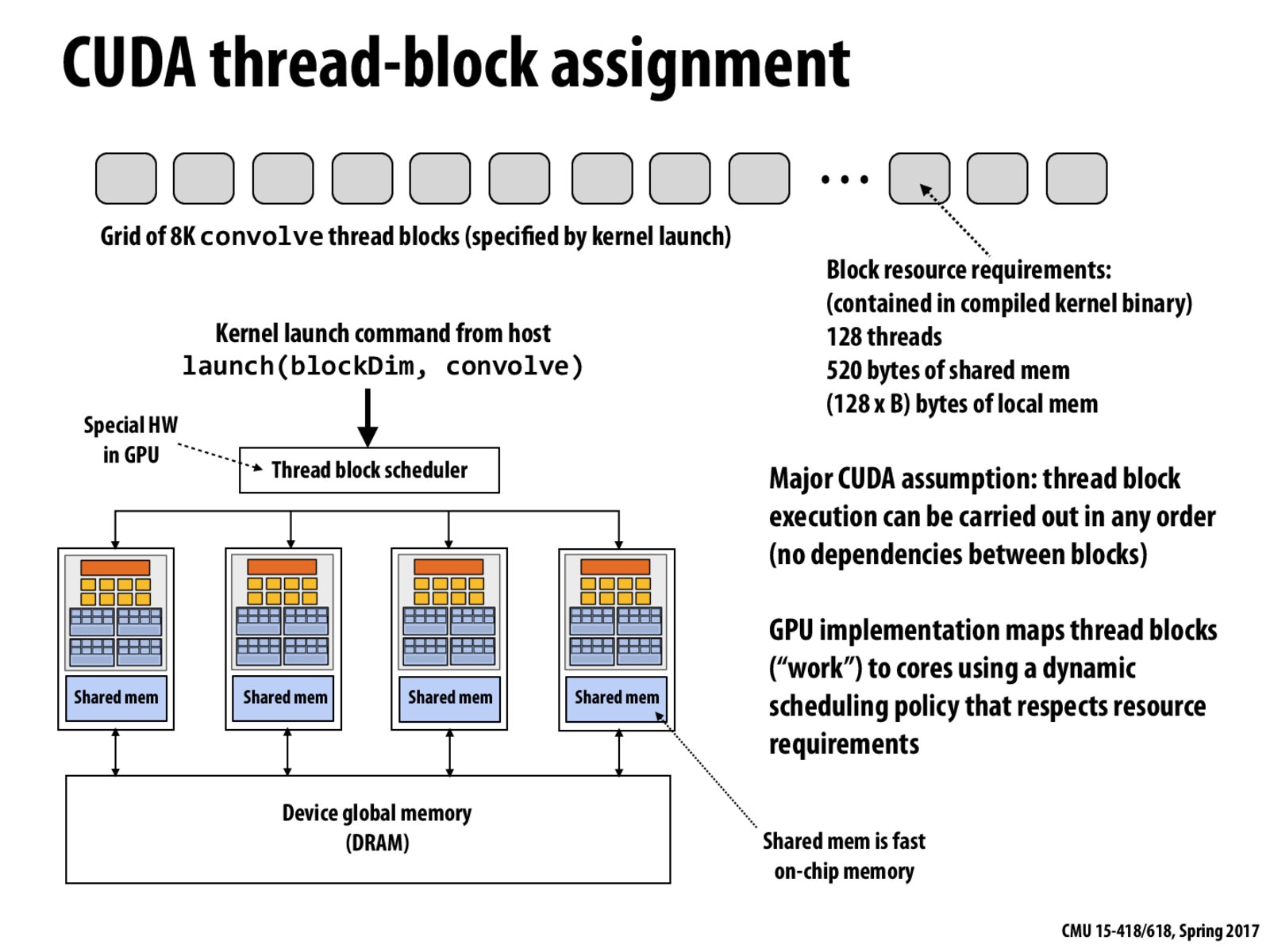
CUDA reserves the right to run thread blocks in any order it wishes, i.e in between blocks, CUDA makes no scheduling requirements. Whereas all such threads in a block must be running concurrently.
shhhh
What happens for the code in slide 49? These threads need to be able to run in parallel and sequentially, but the code contains a syncthreads() command.
bharadwaj
@shhh I think about it in a per-block way.
Each thread in a single block will load its part of the data into shared memory in parallel. Then, all threads in a block will wait at __syncthreads() until everyone is done with the load. Then, they resume the remainder of the kernel at once.
Notice that interleaving doesn't affect program correctness at all. The code is only "sequential" in that a thread will only pass __syncthreads() when all other threads in the block have also reached that __syncthreads().
shhhh
What happens if you require syncthreads between different blocks?
machine6
Remember that thread blocks cannot be 'preempted', in the sense that once the CUDA scheduler assigns a thread block to a core, that block is run to completion.
So imagine a gazillion thread blocks across all cores. With the original way of CUDA scheduling, each thread block assigned to a core will attempt to run to completion, but note that once it hits _global_syncthreads(), it will stop to wait for all the other threadblocks to reach the barrier.
So now, we have a deadlock: threadblocks that are waiting to be assigned to a core can't do so because the blocks currently running on the core are blocking at _global_syncthreads.
One way to possibly solve this is to allow for preemption: as in thread blocks can be interrupted and 'context switched' with other thread blocks waiting to be run.
I can see a lot of complications arising from this though, mainly the issue what happens to shared variables of a thread block that is preempted, where would they be stored, etc.
CUDA reserves the right to run thread blocks in any order it wishes, i.e in between blocks, CUDA makes no scheduling requirements. Whereas all such threads in a block must be running concurrently.
What happens for the code in slide 49? These threads need to be able to run in parallel and sequentially, but the code contains a syncthreads() command.
@shhh I think about it in a per-block way.
Each thread in a single block will load its part of the data into shared memory in parallel. Then, all threads in a block will wait at __syncthreads() until everyone is done with the load. Then, they resume the remainder of the kernel at once.
Notice that interleaving doesn't affect program correctness at all. The code is only "sequential" in that a thread will only pass __syncthreads() when all other threads in the block have also reached that __syncthreads().
What happens if you require syncthreads between different blocks?
Remember that thread blocks cannot be 'preempted', in the sense that once the CUDA scheduler assigns a thread block to a core, that block is run to completion.
So imagine a gazillion thread blocks across all cores. With the original way of CUDA scheduling, each thread block assigned to a core will attempt to run to completion, but note that once it hits _global_syncthreads(), it will stop to wait for all the other threadblocks to reach the barrier.
So now, we have a deadlock: threadblocks that are waiting to be assigned to a core can't do so because the blocks currently running on the core are blocking at _global_syncthreads.
One way to possibly solve this is to allow for preemption: as in thread blocks can be interrupted and 'context switched' with other thread blocks waiting to be run.
I can see a lot of complications arising from this though, mainly the issue what happens to shared variables of a thread block that is preempted, where would they be stored, etc.