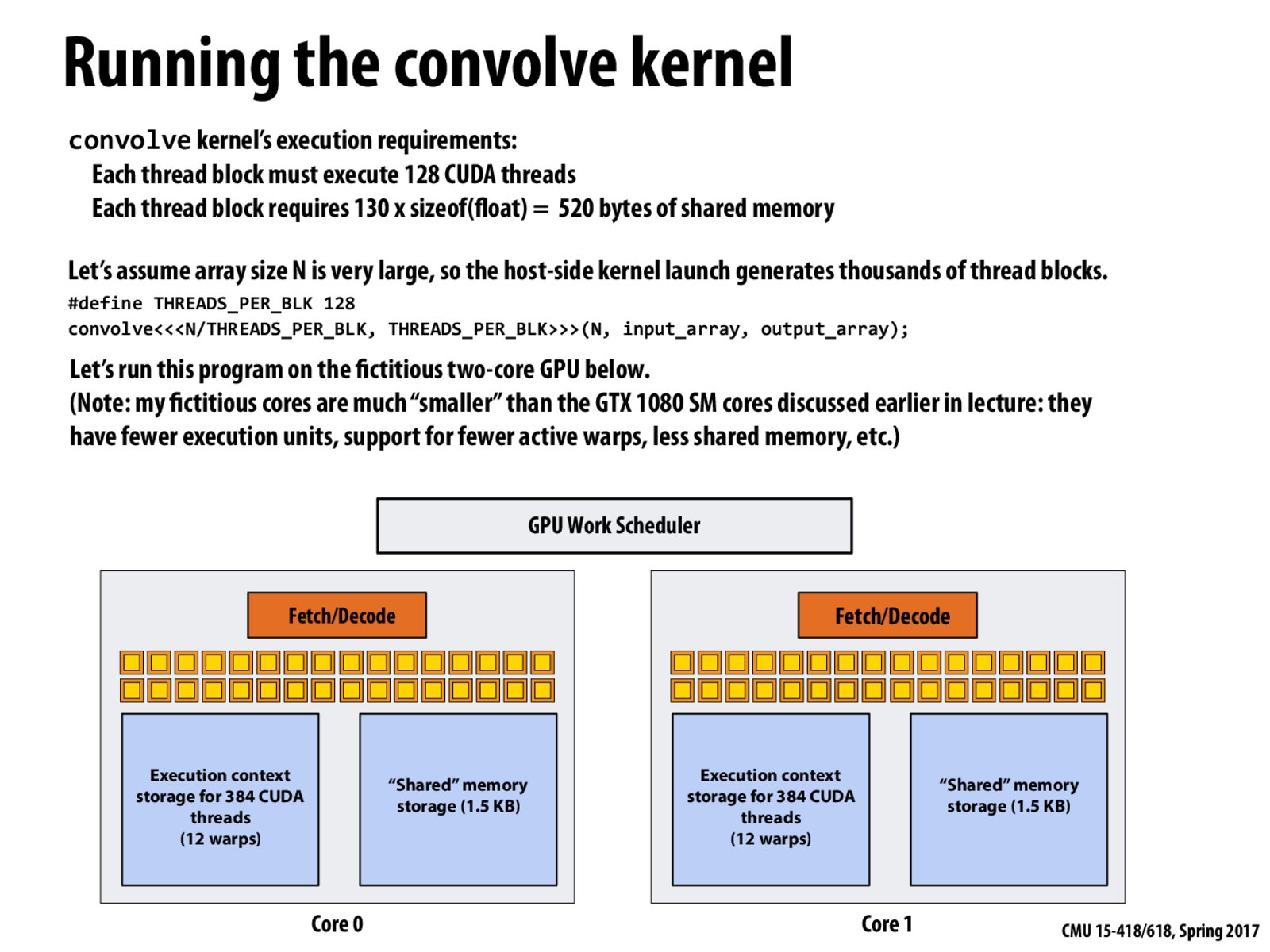
Each CUDA thread block requires all CUDA threads in it to be executing at the same time.
cwchang
In the class (Feb 1.), on this page of slide, Kayvon were discussing on the analogy between CUDA and ISPC, and I didn't really follow the details. Could someone help explain this or summarize the correspondence? Thanks.
sushi
Question: what if the shared memory is not enough for a single warp to run? Will the program encounter compile problem or it will stops at runtime?
googlebleh
@sushi Since shared memory is allocated using the type qualifier __shared__, the compiler is able to decide whether the target device has enough shared memory for the warp to run.
200
@sampathchanda Actually, I think all the threads within a same block must be schedule to a same core, however, they might not be executed at the same time. Only threads within a same warp would be executed at the same time.
paracon
@200, I would agree with that. Since only 4 warps are executed simultaneously in a clock cycle, all threads in block are not executing at the same time. CUDA requires that there is enough compute capability to support the threads of the block. If not, the code will not compile.
pk267
@cwchang: CUDA'a thread is equivalent to ISPC's Program Instance because both map to the same Vector lane in the core.
Also, CUDA's thread block is roughly equivalent to ISPC's gang.
Edit: CUDA's warp is equivalent to ISPC gang, not thread block.
Thank you for pointing it out, @200!
200
@pk267 Thread block is not equivalent to ISPC's gang, warp is.
Levy
@googlebleh agree.
And when a thread block has more threads than what one SM core can handle in context, the block will also have no place to run.
But i think it should be decided on run time, instead of compile time. Otherwise a compiled cuda application will be not portable at all.
SR_94
@Levy, when a thread block has more threads than what the SM core can handle in context then it is a compile time error. In assignment 2, the GTX 1080 had a limit of 1024 CUDA threads per block and if we declared more threads than that => it would throw a compile time error!
themj
The scheduler dynamically maps the the blocks onto the core as space frees up in the execution context.
Each CUDA thread block requires all CUDA threads in it to be executing at the same time.
In the class (Feb 1.), on this page of slide, Kayvon were discussing on the analogy between CUDA and ISPC, and I didn't really follow the details. Could someone help explain this or summarize the correspondence? Thanks.
Question: what if the shared memory is not enough for a single warp to run? Will the program encounter compile problem or it will stops at runtime?
@sushi Since shared memory is allocated using the type qualifier
__shared__, the compiler is able to decide whether the target device has enough shared memory for the warp to run.@sampathchanda Actually, I think all the threads within a same block must be schedule to a same core, however, they might not be executed at the same time. Only threads within a same warp would be executed at the same time.
@200, I would agree with that. Since only 4 warps are executed simultaneously in a clock cycle, all threads in block are not executing at the same time. CUDA requires that there is enough compute capability to support the threads of the block. If not, the code will not compile.
@cwchang: CUDA'a thread is equivalent to ISPC's Program Instance because both map to the same Vector lane in the core.
Also, CUDA's thread block is roughly equivalent to ISPC's gang.
Edit: CUDA's warp is equivalent to ISPC gang, not thread block.
Thank you for pointing it out, @200!
@pk267 Thread block is not equivalent to ISPC's gang, warp is.
@googlebleh agree. And when a thread block has more threads than what one SM core can handle in context, the block will also have no place to run. But i think it should be decided on run time, instead of compile time. Otherwise a compiled cuda application will be not portable at all.
@Levy, when a thread block has more threads than what the SM core can handle in context then it is a compile time error. In assignment 2, the GTX 1080 had a limit of 1024 CUDA threads per block and if we declared more threads than that => it would throw a compile time error!
The scheduler dynamically maps the the blocks onto the core as space frees up in the execution context.