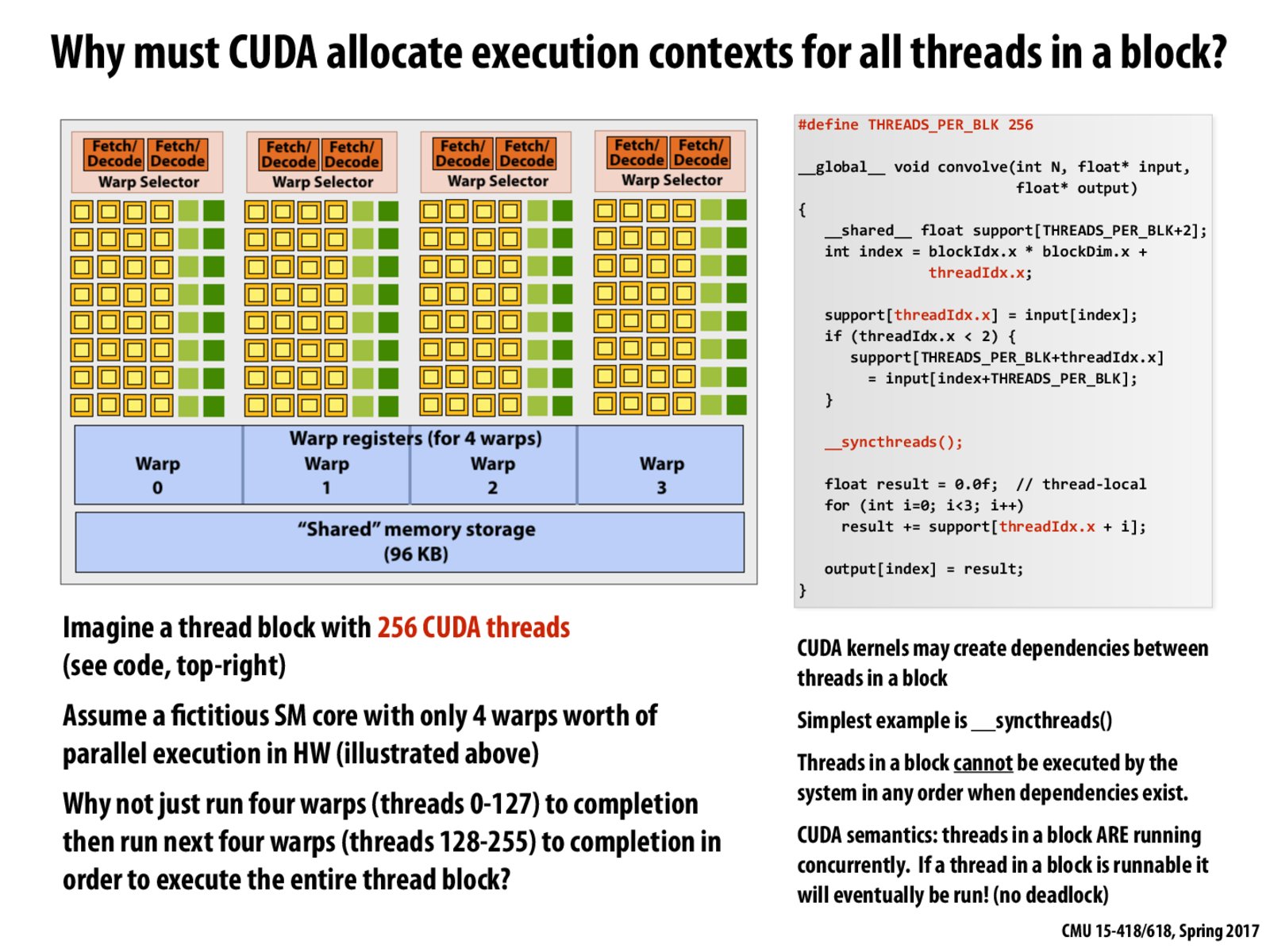
What really happens if we try to run this code? Does CUDA throw a compile-time or run-time error?
In this example, if we remove __syncthreads(), can the GPU work-scheduler possibly schedule the 256 CUDA threads per block in two sequential sets for 0-127 followed by 128-255, since without __syncthreads, we do not explicitly communicate about the dependency between threads in a block?
Or would it never schedule them anyway knowing that it simply cannot support 256 concurrent CUDA threads on the underlying GPU hardware?
aperiwal
Is the above THREADS_PER_BLOCK value of 256 correct if you have, say, 8 Warp Execution Contexts ?
The question is whether the limitation for number of threads per block is the number of HW execution units available (or) the number of execution contexts available ?
jocelynh
Relocated question:
Is it possible for there to be a thread block with enough threads such that they cannot all be run concurrently on one core? And if that happens, how would __syncthreads() work, if at all?
My guess would be that the threads would hang while waiting for other, non-running threads to finish, which would never happen, but I'm not sure.
apk
@bazinga answer to question 1 - compile-time error
kayvonf
@apk is correct. A CUDA program that defines more threads per block than allowed by the CUDA Compute Capability it is compiled for will generate a compile-time error.
@bazinga. CUDA stipulates that all CUDA threads in a CUDA thread block must run currently on a core. As this slide indicates, this scheduling guarantee is required from the system to ensure correct execution of programs that use barriers (__syncthreads). If this guarantee was not provided, then a program with a thread block size greater that maximum number of threads per core, could deadlock at the __syncthreads. (Some of the threads would be waiting at the barrier, waiting for other threads that were not allowed to run since there were no execution contexts to run them. Note: that this explanation assumes that CUDA threads are never pre-empted to make room for other threads in the thread block, which is true of all modern CUDA implementations.)
This scheduling requirement is part of CUDA's definition, so even if a CUDA program was written to not use __syncthreads (and therefore could have been correctly executed in a manner that did not require all 256 to be live on the core at once), the program would still not compile.
Said more explicitly: All CUDA programs are compiled against a CUDA compute capability, and if a program exceeds the resources provided by the compute capability, then compilation will fail.
apr
Just to make sure I understand, shared memory limits and the shared memory per CUDA thread does also limit the number of threads per block, right?
If there is enough space in an SM core for the execution contexts for all threads in one thread block, then that means that these threads can be scheduled on one SM core, and interleaved (4 warps chosen every cycle). In that case, if there is not enough space in the shared memory (DRAM) for the shared memory for this thread block, then will this lead to a run-time error?
o__o
@apr Yes, shared memory limits limit the number of active kernels per SM core. As for allocating too much shared memory in a single thread, I'm also interested in this question. I tried allocating large arrays in shared memory, but the cuda program only terminates incorrectly. It didn't cause any error.
sandeep6189
Little confusion about warp. Is it possible to have multiple warps running together? How is warp size selected? What is the need of dividing the number of threads in a block into warp?
atadkase
@sandeep6189 If you check out slide 58, you can see that at a time, in one core, 4 warps can run. A warp represents a pack of threads which work on different data, but have the same instructions. At times, it would be beneficial to switch out a warp which has blocked on some external I/O, and switch in another ready warp. So dividing the number of threads makes sense.
So I have couple of questions about this slide.
Is the above THREADS_PER_BLOCK value of 256 correct if you have, say, 8 Warp Execution Contexts ? The question is whether the limitation for number of threads per block is the number of HW execution units available (or) the number of execution contexts available ?
Relocated question: Is it possible for there to be a thread block with enough threads such that they cannot all be run concurrently on one core? And if that happens, how would __syncthreads() work, if at all?
My guess would be that the threads would hang while waiting for other, non-running threads to finish, which would never happen, but I'm not sure.
@bazinga answer to question 1 - compile-time error
@apk is correct. A CUDA program that defines more threads per block than allowed by the CUDA Compute Capability it is compiled for will generate a compile-time error.
@bazinga. CUDA stipulates that all CUDA threads in a CUDA thread block must run currently on a core. As this slide indicates, this scheduling guarantee is required from the system to ensure correct execution of programs that use barriers (
__syncthreads). If this guarantee was not provided, then a program with a thread block size greater that maximum number of threads per core, could deadlock at the __syncthreads. (Some of the threads would be waiting at the barrier, waiting for other threads that were not allowed to run since there were no execution contexts to run them. Note: that this explanation assumes that CUDA threads are never pre-empted to make room for other threads in the thread block, which is true of all modern CUDA implementations.)This scheduling requirement is part of CUDA's definition, so even if a CUDA program was written to not use __syncthreads (and therefore could have been correctly executed in a manner that did not require all 256 to be live on the core at once), the program would still not compile.
Said more explicitly: All CUDA programs are compiled against a CUDA compute capability, and if a program exceeds the resources provided by the compute capability, then compilation will fail.
Just to make sure I understand, shared memory limits and the shared memory per CUDA thread does also limit the number of threads per block, right?
If there is enough space in an SM core for the execution contexts for all threads in one thread block, then that means that these threads can be scheduled on one SM core, and interleaved (4 warps chosen every cycle). In that case, if there is not enough space in the shared memory (DRAM) for the shared memory for this thread block, then will this lead to a run-time error?
@apr Yes, shared memory limits limit the number of active kernels per SM core. As for allocating too much shared memory in a single thread, I'm also interested in this question. I tried allocating large arrays in shared memory, but the cuda program only terminates incorrectly. It didn't cause any error.
Little confusion about warp. Is it possible to have multiple warps running together? How is warp size selected? What is the need of dividing the number of threads in a block into warp?
@sandeep6189 If you check out slide 58, you can see that at a time, in one core, 4 warps can run. A warp represents a pack of threads which work on different data, but have the same instructions. At times, it would be beneficial to switch out a warp which has blocked on some external I/O, and switch in another ready warp. So dividing the number of threads makes sense.