It can be seen that in a normal processor, the instruction fetch and decode stage takes up a lot of time and energy. These kinds of overheads aren't present in an FPGA or an ASIC, where the execution stream is built directly into the hardware, making it much more time and energy efficient.
(In a SIMD execution, since there are vector instructions, the number of instructions to be fetched reduces, making the processing more efficient).
pdp
In SIMD execution, one instruction fetch and decode can operate on a vector of input elements, making these computations more efficient in comparison to sequential case.
eosofsky
Computations that take advantage of SIMD execution must involve repeating the same instruction on a number of elements, and each computation must be independent.
SR_94
Additionally, SIMD computations can be run efficiently only on convergent code otherwise we end up doing wasteful work on the divergent elements.
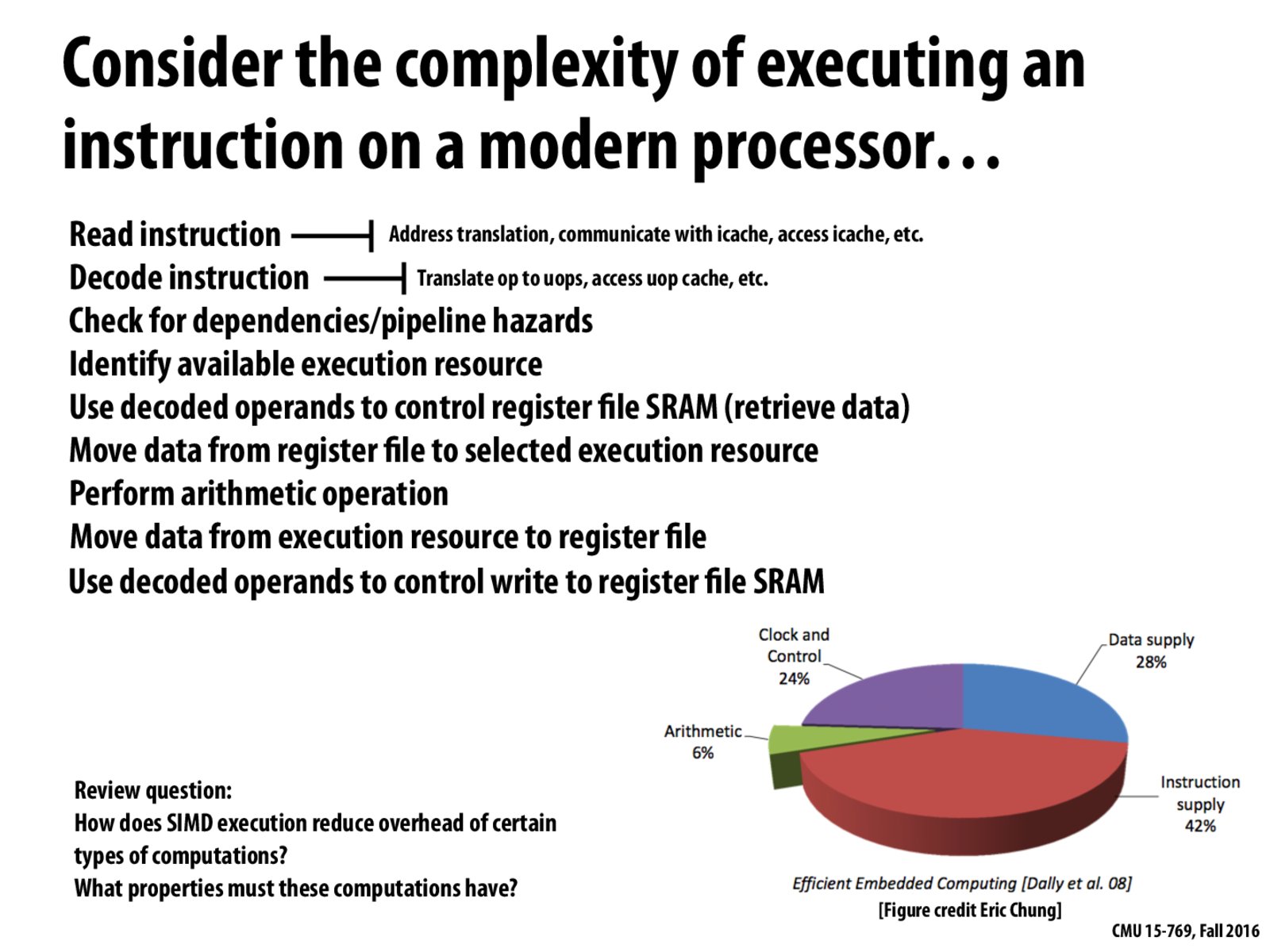
It can be seen that in a normal processor, the instruction fetch and decode stage takes up a lot of time and energy. These kinds of overheads aren't present in an FPGA or an ASIC, where the execution stream is built directly into the hardware, making it much more time and energy efficient.
(In a SIMD execution, since there are vector instructions, the number of instructions to be fetched reduces, making the processing more efficient).
In SIMD execution, one instruction fetch and decode can operate on a vector of input elements, making these computations more efficient in comparison to sequential case.
Computations that take advantage of SIMD execution must involve repeating the same instruction on a number of elements, and each computation must be independent.
Additionally, SIMD computations can be run efficiently only on convergent code otherwise we end up doing wasteful work on the divergent elements.