For checkpointing, each node sends its state to centralized storage server. What would be the problem, if each node contains disks, which can be used only for checkpointing, and not for any other purposes. Does it make restore complicated and slower?
jedi
If I had to guess, disks are the most likely component to fail. Having a centralized, reliable redundant storage system is probably easier to manage than per-server local disks. If a single local disk fails, it seems like the entire job will fail across the cluster. Some checkpointing schemes, like the Fault Tolerant Interface seem to do a hierarchy of checkpoints-- local (as a quick buffer(, partner copy (fast transfer to a neighbour), ... eventually getting to the DFS.
The important point to note here is that, even if one node fails, the computation is restarted from the checkpoint for all nodes.
themj
If one processor fails, why does that entire computation get invalidated? Why doesn't the work from the processor that failed simply get redistributed to the rest of the processors?
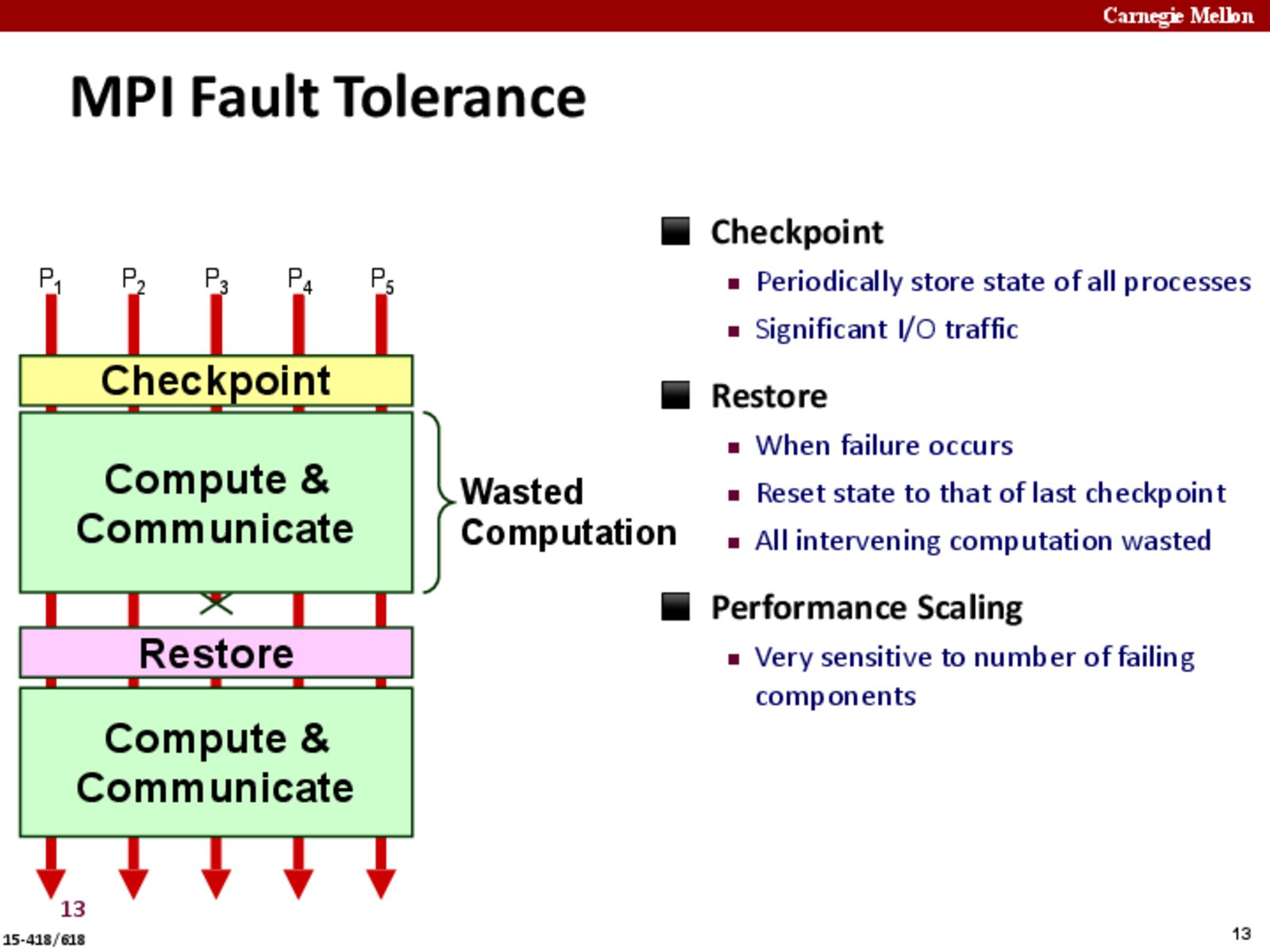
For checkpointing, each node sends its state to centralized storage server. What would be the problem, if each node contains disks, which can be used only for checkpointing, and not for any other purposes. Does it make restore complicated and slower?
If I had to guess, disks are the most likely component to fail. Having a centralized, reliable redundant storage system is probably easier to manage than per-server local disks. If a single local disk fails, it seems like the entire job will fail across the cluster. Some checkpointing schemes, like the Fault Tolerant Interface seem to do a hierarchy of checkpoints-- local (as a quick buffer(, partner copy (fast transfer to a neighbour), ... eventually getting to the DFS.
Source: Blue Waters Supercomputer
The important point to note here is that, even if one node fails, the computation is restarted from the checkpoint for all nodes.
If one processor fails, why does that entire computation get invalidated? Why doesn't the work from the processor that failed simply get redistributed to the rest of the processors?