One good example is of matrix multiplication. The other one is of grid solver, where the data was stored as blocks instead of row-wise.
anonymous
In assignment2, CUDA circle render, one optimization we use is to replace global memory with shared memory since the former is allocated on heap and the later is allocated on stack.
hweetvpu
The size of tmp_buf in convolution example is another case where we considered cache locality as we designed the code.
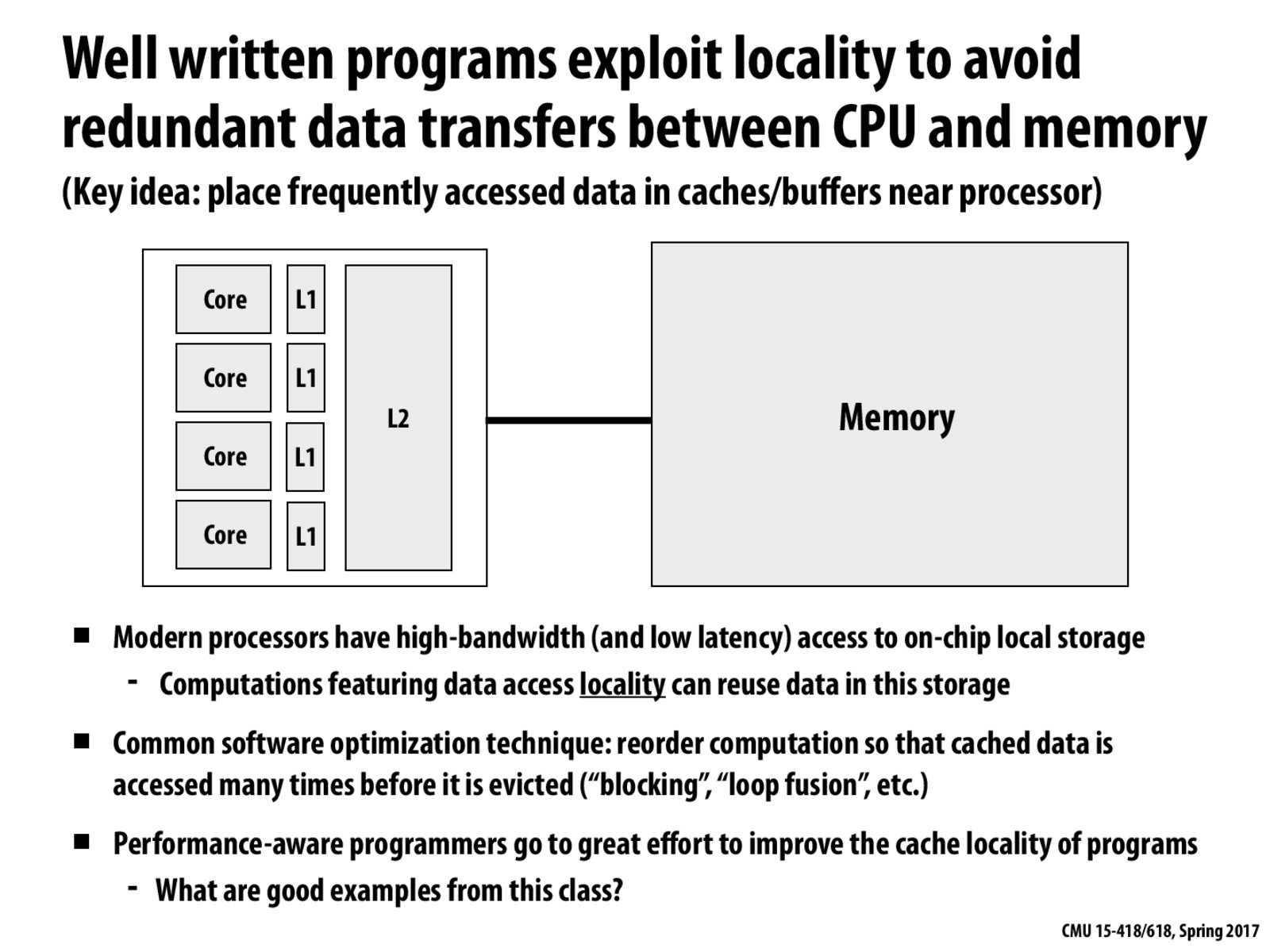
One good example is of matrix multiplication. The other one is of grid solver, where the data was stored as blocks instead of row-wise.
In assignment2, CUDA circle render, one optimization we use is to replace global memory with shared memory since the former is allocated on heap and the later is allocated on stack.
The size of
tmp_bufin convolution example is another case where we considered cache locality as we designed the code.