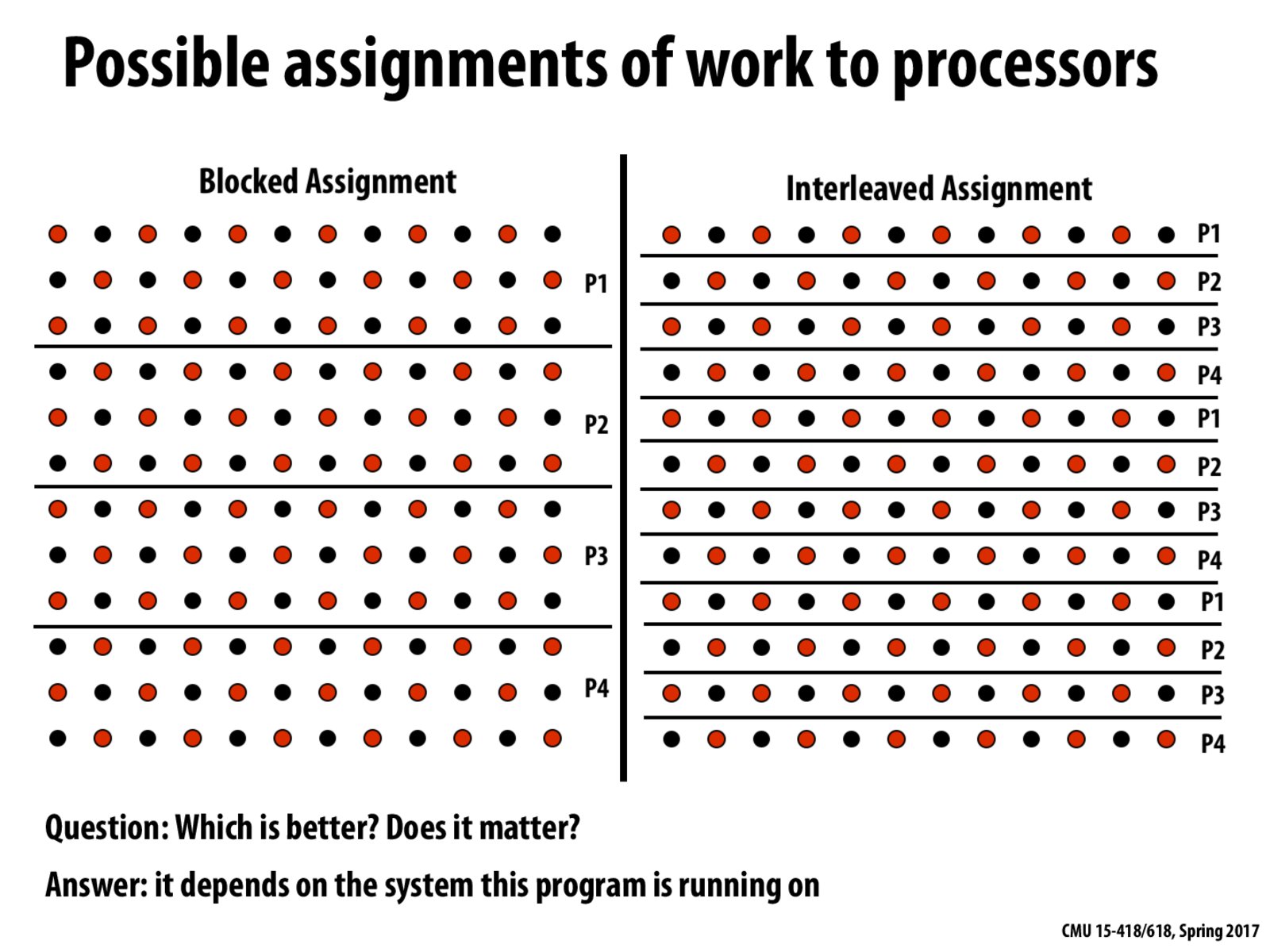
The blocked assignment tends to work better here as opposed to interleaved assignment due to cache locality, and lesser communication overhead. The communication overhead is reduced since in the blocked scenario, only 2/3 of the rows need to communicate information but in the interleaved scenario, rows have to communicate information to their neighbours.
kayvonf
@paracon. Nice post. But I'd like to mention that it may not necessarily be cache locality specifically that is improved in the blocked assignment. If the different processors were different machines, it would be main memory locality (and the communication saved would be machine-to-machine communication).
whitelez
So I would assume in a distributed system, on which threads share information through messages, it would be better to assign even larger blocks to lesser threads. So I think for a large image or dataset that need to be processed parallel, there should be doing some pre-calculation about the optimized tasks assignment. This calculation should include information-share latency, as well as the execution speed of each single processors. Is there any "smart" compiler or scheduling system could perform this for programmer?
Firephinx
Since blocked assignment is usually better on most systems as there needs to be less communication between the processors (only the top and bottom lines of each block), what type of system would run the interleaved assignment better than the blocked assignment?
apr
@Firephinx As mentioned in earlier comments, the blocked assignment helps decrease the communication overhead between different processors / different machines, and also allows better exploitation of spacial locality. I think that in a system where one row of the matrix is too big to fit in one cache line and when there are fast mechanisms for inter-core communication, we will lose the advantage gained from blocked assignment. For example, there are different topologies that form the interconnection between different cores through shared buses. Here is an interesting but dated link I found when I looked up different interconnect schemes http://www.intel.com/content/dam/doc/white-paper/quick-path-interconnect-introduction-paper.pdf
hzxa21
I guess if we are assignment work to ISPC program instances not processors, the block assignment is not cache-friendly because there will be gather/scatter instead of load/store for continuous memory. However, I think a good strategy is to do block assignment for ISPC tasks then within each task do interleaved assignment.
The blocked assignment tends to work better here as opposed to interleaved assignment due to cache locality, and lesser communication overhead. The communication overhead is reduced since in the blocked scenario, only 2/3 of the rows need to communicate information but in the interleaved scenario, rows have to communicate information to their neighbours.
@paracon. Nice post. But I'd like to mention that it may not necessarily be cache locality specifically that is improved in the blocked assignment. If the different processors were different machines, it would be main memory locality (and the communication saved would be machine-to-machine communication).
So I would assume in a distributed system, on which threads share information through messages, it would be better to assign even larger blocks to lesser threads. So I think for a large image or dataset that need to be processed parallel, there should be doing some pre-calculation about the optimized tasks assignment. This calculation should include information-share latency, as well as the execution speed of each single processors. Is there any "smart" compiler or scheduling system could perform this for programmer?
Since blocked assignment is usually better on most systems as there needs to be less communication between the processors (only the top and bottom lines of each block), what type of system would run the interleaved assignment better than the blocked assignment?
@Firephinx As mentioned in earlier comments, the blocked assignment helps decrease the communication overhead between different processors / different machines, and also allows better exploitation of spacial locality. I think that in a system where one row of the matrix is too big to fit in one cache line and when there are fast mechanisms for inter-core communication, we will lose the advantage gained from blocked assignment. For example, there are different topologies that form the interconnection between different cores through shared buses. Here is an interesting but dated link I found when I looked up different interconnect schemes http://www.intel.com/content/dam/doc/white-paper/quick-path-interconnect-introduction-paper.pdf
I guess if we are assignment work to ISPC program instances not processors, the block assignment is not cache-friendly because there will be gather/scatter instead of load/store for continuous memory. However, I think a good strategy is to do block assignment for ISPC tasks then within each task do interleaved assignment.