The Gather operation can be particularly expensive if the mem_base is large and the index vector is very scattered. Such operation lacks spatial locality.
kayvonf
Question: Who can tell use about the AVX gather or AVX-512 gather/scatter instructions?
I'll try to give an overview of the AVX2 intrinsic, _mm256_i32gather_epi32, which returns a __mm256i type. If you navigate to the intrinsics page, there seems to be an overwhelming amount of instructions--but most are just variations of several types. The entire function spec is as follows:
__m256i _mm256_i32gather_epi32 (int const* base_addr, __m256i vindex, const int scale)
All of Intel's instructions have pretty much the same naming scheme. The _mm256 indicates that the instruction operates on 256 bit registers. The return type of __mm256i indicates that the result of the operation is a 256 bit pack of int's (a d suffix stands for double).
i32gather is the operation. In this case, it is 'gathering' 32 bit integers. Finally, the epi32 suffix means that the instruction operates on extended packed 32 bit integers. More specifically, the input data to this instruction, vindex, is to be interpreted as a pack of 32 bit integers.
So, what does it do? _mm256_i32gather_epi32 returns a vector of eight 32 bit integers using eight 32 bit indecies. The location of the ith gathered element is calculated as MEM[base_addr + vindex[i] * scale], where scale can be 1, 2, 4, or 8.
The guide mentions that the instruction has a latency of 6, but does not state units. It seems reasonable to guess that they mean 6 clock cycles, but that seems a bit too fast if the indices hit different cache lines.
AVX-512 implements all AVX2 instructions using larger 512 bit registers, along with a few new operations such as _mm512_mask_prefetch_i32extgather_ps which prefetches 16 single precision (32 bit) elements into cache (you can even specify whether you want it in L1 or L2!).
Example
Say we have an integer array A (e.g. base_addr = A) and we want to gather elements at indices 2, 3, 5, 7, 11, 13, 17, and 19. First store the indices in a standard array, then pack them into a single __m256i.
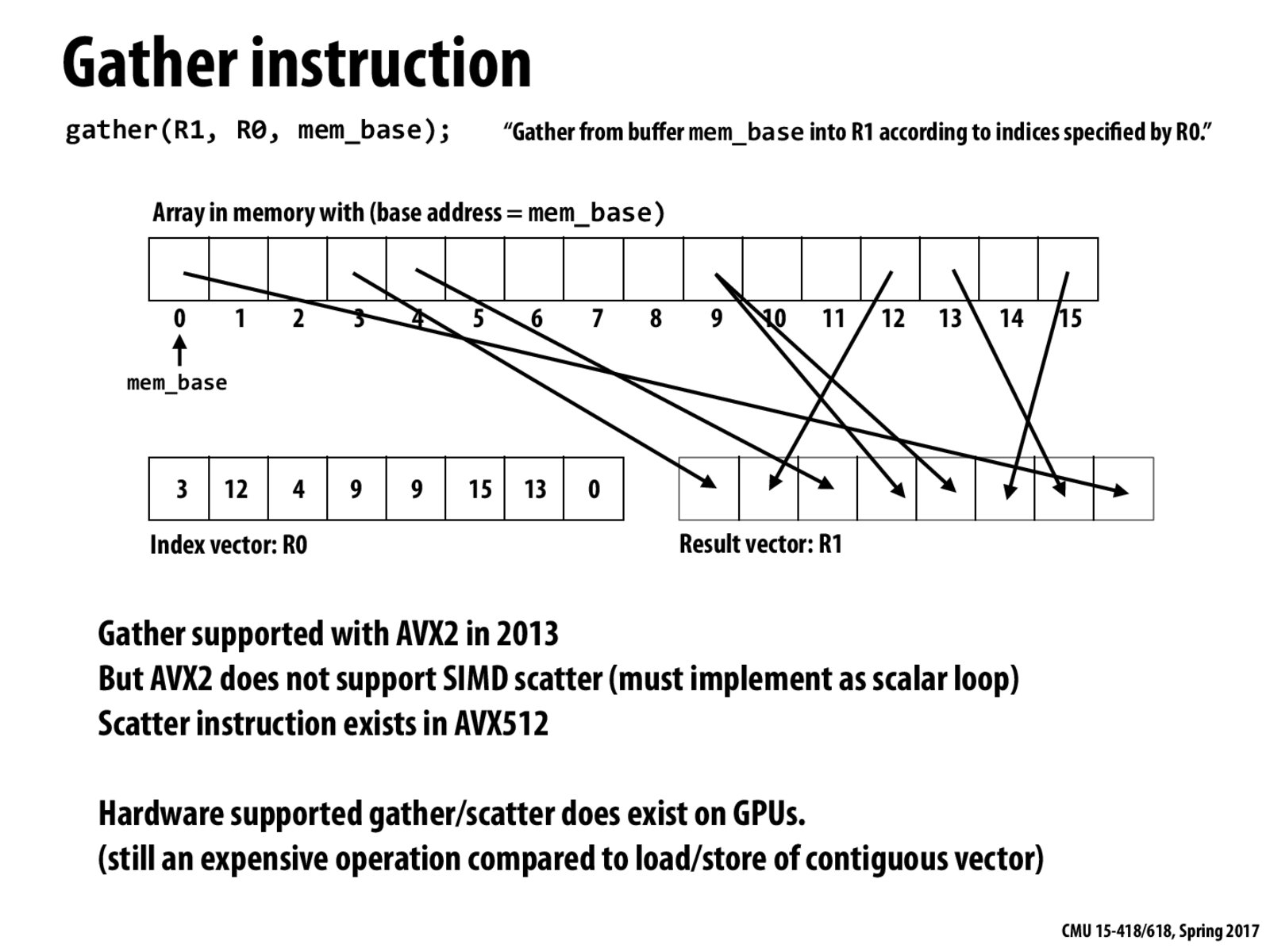
The Gather operation can be particularly expensive if the mem_base is large and the index vector is very scattered. Such operation lacks spatial locality.
Question: Who can tell use about the AVX gather or AVX-512 gather/scatter instructions?
See the very handy Intel Intrinsics Guide!
@kayvonf
I'll try to give an overview of the AVX2 intrinsic,
_mm256_i32gather_epi32, which returns a__mm256itype. If you navigate to the intrinsics page, there seems to be an overwhelming amount of instructions--but most are just variations of several types. The entire function spec is as follows:__m256i _mm256_i32gather_epi32 (int const* base_addr, __m256i vindex, const int scale)All of Intel's instructions have pretty much the same naming scheme. The
_mm256indicates that the instruction operates on 256 bit registers. The return type of__mm256iindicates that the result of the operation is a 256 bit pack ofint's (adsuffix stands fordouble).i32gatheris the operation. In this case, it is 'gathering' 32 bit integers. Finally, theepi32suffix means that the instruction operates on extended packed 32 bit integers. More specifically, the input data to this instruction,vindex, is to be interpreted as a pack of 32 bit integers.So, what does it do?
_mm256_i32gather_epi32returns a vector of eight 32 bit integers using eight 32 bit indecies. The location of the ith gathered element is calculated asMEM[base_addr + vindex[i] * scale], where scale can be 1, 2, 4, or 8.The guide mentions that the instruction has a latency of 6, but does not state units. It seems reasonable to guess that they mean 6 clock cycles, but that seems a bit too fast if the indices hit different cache lines.
AVX-512 implements all AVX2 instructions using larger 512 bit registers, along with a few new operations such as
_mm512_mask_prefetch_i32extgather_pswhich prefetches 16 single precision (32 bit) elements into cache (you can even specify whether you want it in L1 or L2!).Example
Say we have an integer array
A(e.g.base_addr = A) and we want to gather elements at indices 2, 3, 5, 7, 11, 13, 17, and 19. First store the indices in a standard array, then pack them into a single__m256i.int idxs [8] = { 2, 3, 5, 7, 11, 13, 17, 19 }; __m256i vindex = _mm256_maskload_epi32 (idxs, maskAll);Then we can invoke our gather, using a scale of 4 (32 bits => 4-wide elements).
__m256i result = _mm256_i32gather_epi32 (A, vindex, 4);