In the mandelbrot fractal problem, we used a pattern of work distribution which gave each of the n threads one out of every n rows to process. Although this worked well for the mandelbrot input, an adversary could construct a problem where this assignment would not work well.
However, one solution to this is to used a randomized static assignment, by shuffling the rows before assigning them to each worker, so that on average, they all have about the same work. This makes it difficult for an adversary to make the work too unbalanced (as long as the maximum amount of work per row is not ridiculously large, which it isn't).
ctabrizi
I had recently been thinking about some general optimizations and realized just how many of them were dependent on and limited by the distribution of the data.
====== Very Basic and Exploratory Example (feel free to skip) ====
I considered an operation similar to what we saw in Assignment 1: an input array of base values "x" and an input array of exponent values "n". The output will be an array consisting of (x .^ n) (using the element-wise notation for exponent).
Consider the case where both input arrays consist of all equal values (x = [2,2,2,2] and n = [3,3,3,3]). This eliminates any regions of serial execution because all the "workers" (used generically) will perform the same set of instructions uniformly, finishing in unison. We would expect something to accumulate like the following:
In this case, all 4 workers are being used equally until the end.
There are many other input arrays that can yield this property. In this particular example, since we don't have any branching based on the result of the multiplications (unlike in the assignment), we don't have any dependence on the base values (if they're greater than 1 in value). An example of this would be x = [2,2,2,3] and n = [3,3,3,3]. Then (x .^ n) would evolve like so:
In the SIMD model, the above is the equivalent of some lanes masking early. As early as the completion of the first multiply, we lose full worker utilization!
==============================================
The optimizations I was considering are actually mostly covered in these slides.
The conclusion I usually got to is that it depends on what we're trying to optimize for in terms of the range and distribution of behaviors. We may not be okay with some worst-case scenarios. Or maybe we have some priors on what our inputs might be and can pick a better policy accordingly.
@crow, your idea of randomized assignment could work on average. But I wonder how the worst and average cases (and the variance) on a random assignment compare to the distributions that result from a spatially-consistent assignment (it could be the case that a given mandelbrot equation will naturally have favorable work distribution, for some definition of favorable).
shpeefps
I am curious as to how many applications of parallel programming are generalized and how many are specific. I imagine in many cases where you know exactly the properties of data you're processing you would prefer static assignments. What about if you don't know much about the data? Are there ways to analyze the data before determining the best algorithm?
rrudolph
I think the divergence is only an issue when we're considering parallelization at the SIMD level or thread level. Divergence between different thread blocks should have almost no negative affect, as long as there are several execution contexts on each core.
1_1
Static assignments are possible when we know the work a priori. We used a static assignment, for example, in the Mandelbrot fractal problem in assignment one. We decided to interleave to divide up the workload among the threads since we knew that certain parts of the image were brighter than others and took more time to calculate.
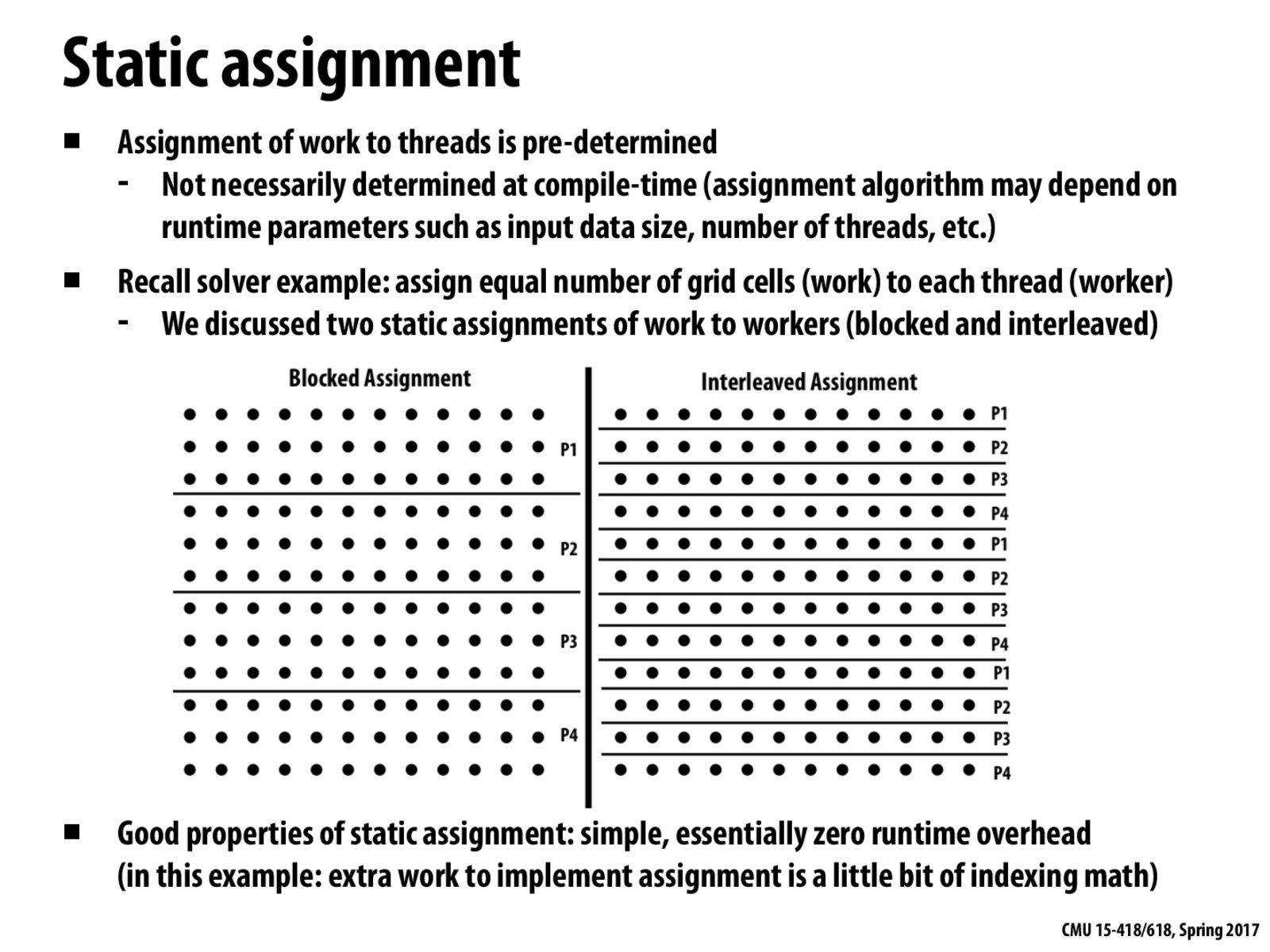
In the mandelbrot fractal problem, we used a pattern of work distribution which gave each of the n threads one out of every n rows to process. Although this worked well for the mandelbrot input, an adversary could construct a problem where this assignment would not work well.
However, one solution to this is to used a randomized static assignment, by shuffling the rows before assigning them to each worker, so that on average, they all have about the same work. This makes it difficult for an adversary to make the work too unbalanced (as long as the maximum amount of work per row is not ridiculously large, which it isn't).
I had recently been thinking about some general optimizations and realized just how many of them were dependent on and limited by the distribution of the data.
====== Very Basic and Exploratory Example (feel free to skip) ====
I considered an operation similar to what we saw in Assignment 1: an input array of base values "x" and an input array of exponent values "n". The output will be an array consisting of (x .^ n) (using the element-wise notation for exponent).
Consider the case where both input arrays consist of all equal values (x = [2,2,2,2] and n = [3,3,3,3]). This eliminates any regions of serial execution because all the "workers" (used generically) will perform the same set of instructions uniformly, finishing in unison. We would expect something to accumulate like the following:
[2,2,2,2] .* [2,2,2,2] = [4,4,4,4] <-- temporary output [4,4,4,4] .* [2,2,2,2] = [8,8,8,8] <-- final output
In this case, all 4 workers are being used equally until the end.
There are many other input arrays that can yield this property. In this particular example, since we don't have any branching based on the result of the multiplications (unlike in the assignment), we don't have any dependence on the base values (if they're greater than 1 in value). An example of this would be x = [2,2,2,3] and n = [3,3,3,3]. Then (x .^ n) would evolve like so:
[2,2,2,3] .* [2,2,2,3] = [4,4,4,9] [4,4,4,9] .* [2,2,2,3] = [8,8,8,27]
Like before, every worker is doing equal amounts of useful work (still no idling visible).
However, if we revert x and change n (x = [2,2,2,2], n = [1,2,2,3]), it might evolve like so:
[2,2,2,2] .* [-,2,2,2] = [2,4,4,4] [2,4,4,4] .* [-,-,-,2] = [2,4,4,8]
In the SIMD model, the above is the equivalent of some lanes masking early. As early as the completion of the first multiply, we lose full worker utilization!
==============================================
The optimizations I was considering are actually mostly covered in these slides.
The conclusion I usually got to is that it depends on what we're trying to optimize for in terms of the range and distribution of behaviors. We may not be okay with some worst-case scenarios. Or maybe we have some priors on what our inputs might be and can pick a better policy accordingly.
@crow, your idea of randomized assignment could work on average. But I wonder how the worst and average cases (and the variance) on a random assignment compare to the distributions that result from a spatially-consistent assignment (it could be the case that a given mandelbrot equation will naturally have favorable work distribution, for some definition of favorable).
I am curious as to how many applications of parallel programming are generalized and how many are specific. I imagine in many cases where you know exactly the properties of data you're processing you would prefer static assignments. What about if you don't know much about the data? Are there ways to analyze the data before determining the best algorithm?
I think the divergence is only an issue when we're considering parallelization at the SIMD level or thread level. Divergence between different thread blocks should have almost no negative affect, as long as there are several execution contexts on each core.
Static assignments are possible when we know the work a priori. We used a static assignment, for example, in the Mandelbrot fractal problem in assignment one. We decided to interleave to divide up the workload among the threads since we knew that certain parts of the image were brighter than others and took more time to calculate.