This relates to the first homework, where the optimal solution was to break the Mandelbrot pictures into 800 tasks, one task for each row. In that case, synchronization was not an issue, so dividing the work into smaller tasks was efficient.
lya
In the queue theory, we know that if we schedule the shorter jobs first and longer jobs last, we could achieve a smaller average latency of jobs. However, it is the opposite in the case of parallel task scheduling for a higher throughput. In this sense, latency and throughput is a pair of interesting tradeoff. It is also obvious that, in the parallelism world, we care more about balance and throughput than the latency.
pdp
@lya: "if we schedule the shorter jobs first and longer jobs last, we could achieve a smaller average latency of jobs." how? Please elaborate.
lya
@pdp For example, consider three tasks with running times of 1, 2, 7. If we schedule them in the order of 1, 2, 7, average latency (shown as '~' in figure below) = (0 + 1 + 3) / 3 = 1.33.
0123456789
1|
~2-|
~~~7------|
On the contrast, if we schedule them in the order of 7, 2, 1 average latency = (0 + 7 + 9) / 3 = 5.33.
0123456789
7------|
~~~~~~~2-|
~~~~~~~~~1|
apr
@lya Great point! In addition, I would like to add that task splitting can be and is applied in real-time systems. For example, when in the case where we are calculating latency - with all the tasks having arrived at time 0, the biggest task can be split into different parts that are dependent on each other and have to be run sequentially. They can then be scheduled on different cores (at the risk of losing locality but gaining average latency reduction.) The kernel will however, have to make sure that the dependent parts are not run in the wrong order, which results in extra work to be done.
In real-time systems, there is the additional requirement of meeting deadlines for tasks, which results in allotting priorities to the different parts of the task on different cores in a way that leads to the correct results.
jedi
@lya that's a great point. However, the queuing solution to minimize latency (run the Shortest Job First) is only useful when we want to minimize the average latency of the individual executions.
In our case, we only care about minimizing the overall latency for the set of all tasks, by reducing the likelihood of stragglers.
Consider, your example above, but process them two-at-a-time, instead of using a single thread.
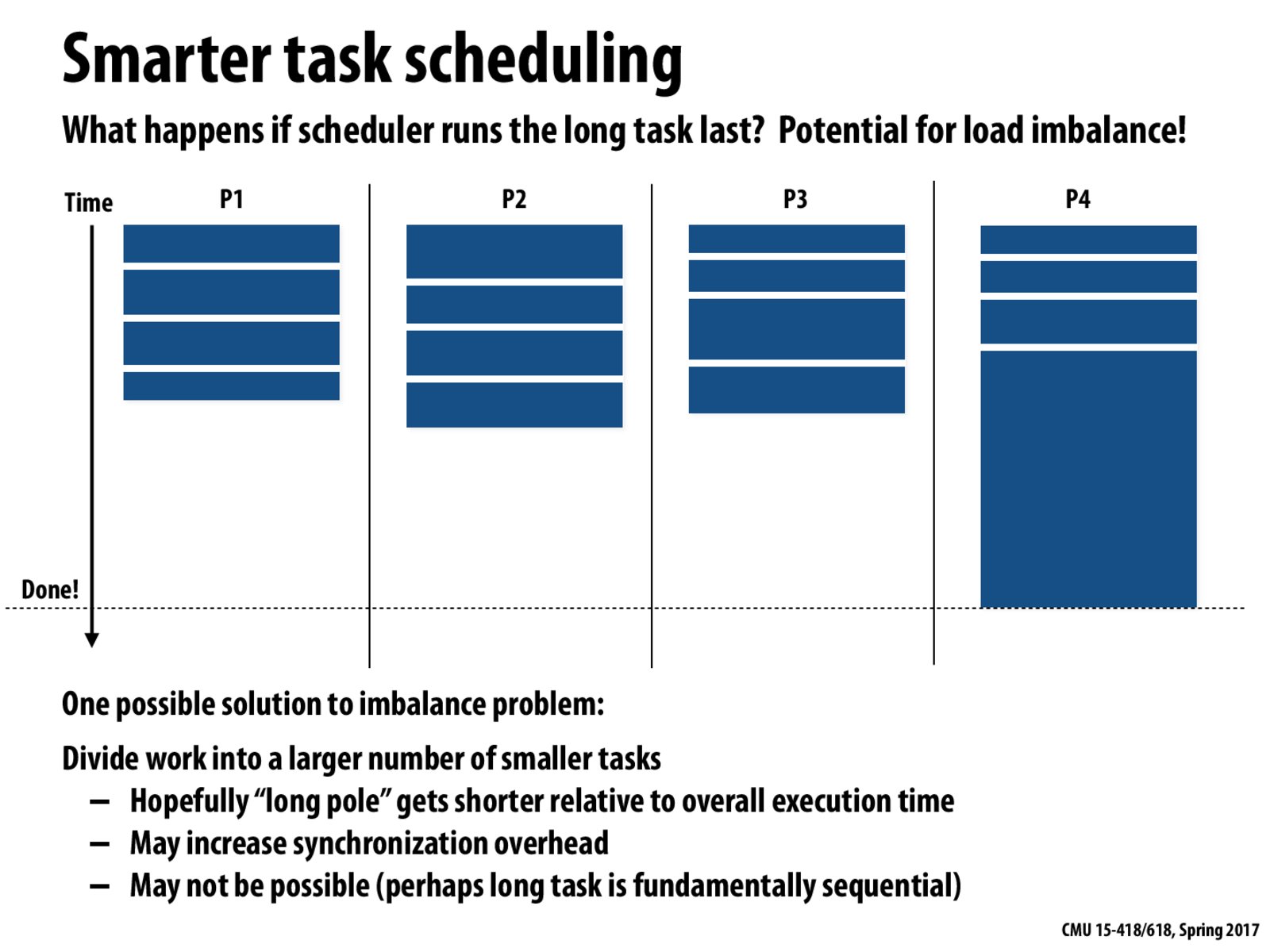
This relates to the first homework, where the optimal solution was to break the Mandelbrot pictures into 800 tasks, one task for each row. In that case, synchronization was not an issue, so dividing the work into smaller tasks was efficient.
In the queue theory, we know that if we schedule the shorter jobs first and longer jobs last, we could achieve a smaller average latency of jobs. However, it is the opposite in the case of parallel task scheduling for a higher throughput. In this sense, latency and throughput is a pair of interesting tradeoff. It is also obvious that, in the parallelism world, we care more about balance and throughput than the latency.
@lya: "if we schedule the shorter jobs first and longer jobs last, we could achieve a smaller average latency of jobs." how? Please elaborate.
@pdp For example, consider three tasks with running times of 1, 2, 7. If we schedule them in the order of 1, 2, 7, average latency (shown as '~' in figure below) = (0 + 1 + 3) / 3 = 1.33. 0123456789
1|
~2-|
~~~7------|
On the contrast, if we schedule them in the order of 7, 2, 1 average latency = (0 + 7 + 9) / 3 = 5.33. 0123456789
7------|
~~~~~~~2-|
~~~~~~~~~1|
@lya Great point! In addition, I would like to add that task splitting can be and is applied in real-time systems. For example, when in the case where we are calculating latency - with all the tasks having arrived at time 0, the biggest task can be split into different parts that are dependent on each other and have to be run sequentially. They can then be scheduled on different cores (at the risk of losing locality but gaining average latency reduction.) The kernel will however, have to make sure that the dependent parts are not run in the wrong order, which results in extra work to be done.
In real-time systems, there is the additional requirement of meeting deadlines for tasks, which results in allotting priorities to the different parts of the task on different cores in a way that leads to the correct results.
@lya that's a great point. However, the queuing solution to minimize latency (run the Shortest Job First) is only useful when we want to minimize the average latency of the individual executions.
In our case, we only care about minimizing the overall latency for the set of all tasks, by reducing the likelihood of stragglers.
Consider, your example above, but process them two-at-a-time, instead of using a single thread.