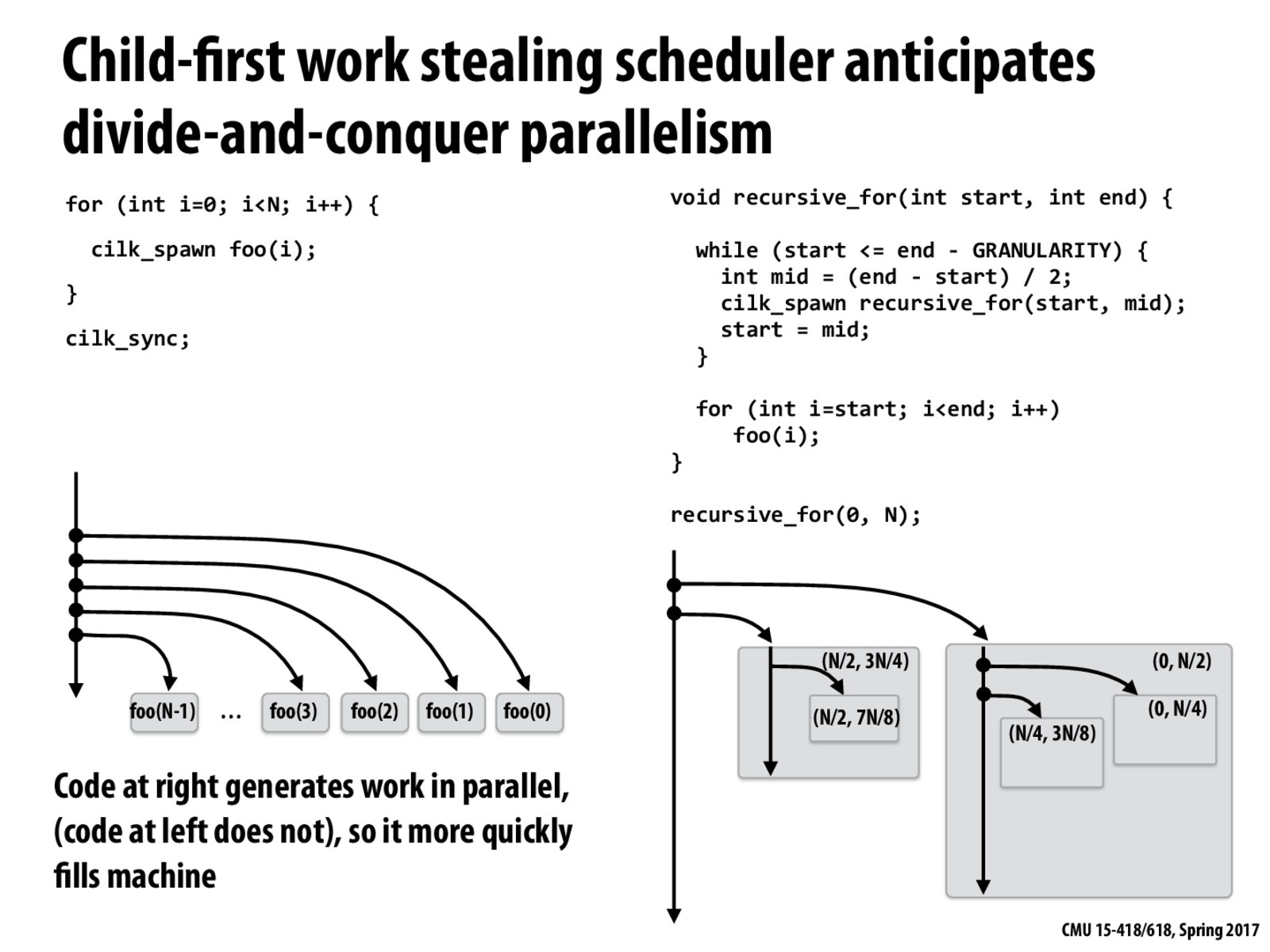
From my view, the right program makes the machine filled quickly because it distribute the cost of cilk_spawn into different cores. Am I right?
sushi
From my point of view, the reason why the right program performs better is that the granularity of tasks is bigger. For the left program, each work can be finished so fast and the total amount of work (N) is surely larger than the total amount of workers. Therefore, there're lots of work "stealing"s between threads which makes it slow.
axiao
Why does running the child first benefit divide-and-conquer parallelism?
It seems like that when you split the problem in half, the continuation and the child are pretty much the same: they both operate on half the problem and spawn more children on their half. So why should the original thread run the child first and leave the continuation for others to steal? Isn't it the same as running the continuation first and leaving the child for others to steal?
Master
My thoughts on the comparison of the two programs:
The right one distributes tasks faster. Not very precisely speaking, the left one takes O(N) time to finish distributing all the tasks, while the right one takes O(log(N)) time to distribute all the tasks. This is because there is only one thread on the left working on distributing the tasks while on the right, the number of threads working on task distribution increases exponentially. Therefore, the left one lets more threads sit idle during task distribution, which explains "it more quickly fills machine".
Codes on the right have larger pieces of work to steal every time, therefore mitigating the overhead.
rlaporte
Referring to axiao's comment, I would agree that since we are dividing all work in half every time we spawn a new computation, it doesn't really matter if we are stealing the continuation or the child.
I think that this slide was meant to show us different ways of partitioning work (ie. iteratively vs. recursively) and how this could affect performance. The implementation choices ( child stealing or continuation stealing ) don't matter for the reasons axiao mentionned.
I must admit that the "child first" mention in the title of the slide is somewhat misleading. Please tell me if I seem to be missing something.
pagerank
@Master: great observation, but I want to say:
The big O analysis may not be appropriate here since the number of threads is very limited.
I don't think stealing a large piece of work has greater overhead than stealing a small one. Because only the start/end positions and necessary context are copied. The array being sorted is not moving around. Maybe you are concerning about the situation where the data is in L1, L2 cache, and the threads are in different cores. Stealing may introduce more cache misses (data is cached when partitioning), but stealing the small ones will have the same problem as long as the jobs are evenly distributed.
BigPapaChu
Wouldn't the program on the left not benefit at all from parallelism since it requires for the foo(N-1) run to complete first? This is like the largest runtime of a SIMD instruction being waited on to finish?
kapalani
Should the first gray box on the right say (N/2, 5N/8) as opposed to 7N/8 since 7N/8 is larger than 3N/4?
200
Back from lecture 7, another advantage for recursive_for is that it reduces the contention of task stealing: these generated tasks have different workloads, thus, it's unlikely that they would be finished in the same time, therefore the worker threads are less likely to steal next task in the same time.
paracon
@pagerank, @Master : According to me, there is at least one advantage of stealing large work items as opposed to small items multiple times; cache locality - since you would get contiguous pieces of data to work on. If you steal a small work item, then another thread could take the next contiguous piece which affect cache locality poorly.
mario
From lecture, we heard that we should run the child first as opposed to the continuation. We can use the cilk for to do divide and conquer recursion because it divides the problem in half and it keeps occurring.
From my view, the right program makes the machine filled quickly because it distribute the cost of cilk_spawn into different cores. Am I right?
From my point of view, the reason why the right program performs better is that the granularity of tasks is bigger. For the left program, each work can be finished so fast and the total amount of work (N) is surely larger than the total amount of workers. Therefore, there're lots of work "stealing"s between threads which makes it slow.
Why does running the child first benefit divide-and-conquer parallelism?
It seems like that when you split the problem in half, the continuation and the child are pretty much the same: they both operate on half the problem and spawn more children on their half. So why should the original thread run the child first and leave the continuation for others to steal? Isn't it the same as running the continuation first and leaving the child for others to steal?
My thoughts on the comparison of the two programs:
The right one distributes tasks faster. Not very precisely speaking, the left one takes O(N) time to finish distributing all the tasks, while the right one takes O(log(N)) time to distribute all the tasks. This is because there is only one thread on the left working on distributing the tasks while on the right, the number of threads working on task distribution increases exponentially. Therefore, the left one lets more threads sit idle during task distribution, which explains "it more quickly fills machine".
Codes on the right have larger pieces of work to steal every time, therefore mitigating the overhead.
Referring to axiao's comment, I would agree that since we are dividing all work in half every time we spawn a new computation, it doesn't really matter if we are stealing the continuation or the child.
I think that this slide was meant to show us different ways of partitioning work (ie. iteratively vs. recursively) and how this could affect performance. The implementation choices ( child stealing or continuation stealing ) don't matter for the reasons axiao mentionned.
I must admit that the "child first" mention in the title of the slide is somewhat misleading. Please tell me if I seem to be missing something.
@Master: great observation, but I want to say:
The big O analysis may not be appropriate here since the number of threads is very limited.
I don't think stealing a large piece of work has greater overhead than stealing a small one. Because only the start/end positions and necessary context are copied. The array being sorted is not moving around. Maybe you are concerning about the situation where the data is in L1, L2 cache, and the threads are in different cores. Stealing may introduce more cache misses (data is cached when partitioning), but stealing the small ones will have the same problem as long as the jobs are evenly distributed.
Wouldn't the program on the left not benefit at all from parallelism since it requires for the foo(N-1) run to complete first? This is like the largest runtime of a SIMD instruction being waited on to finish?
Should the first gray box on the right say (N/2, 5N/8) as opposed to 7N/8 since 7N/8 is larger than 3N/4?
Back from lecture 7, another advantage for recursive_for is that it reduces the contention of task stealing: these generated tasks have different workloads, thus, it's unlikely that they would be finished in the same time, therefore the worker threads are less likely to steal next task in the same time.
@pagerank, @Master : According to me, there is at least one advantage of stealing large work items as opposed to small items multiple times; cache locality - since you would get contiguous pieces of data to work on. If you steal a small work item, then another thread could take the next contiguous piece which affect cache locality poorly.
From lecture, we heard that we should run the child first as opposed to the continuation. We can use the cilk for to do divide and conquer recursion because it divides the problem in half and it keeps occurring.