We usually assume row major format, but by making it into block-major format, we get perfect spatial locality because the addresses assigned to a thread are all consecutive. This leads to more efficient parallel code.
Abandon
I am wondering, is it complicated to store the matrix in the manner of right? And if the red block in the picture is a cache line, then the first three lines of P13 cannot fit into the two cache lines and there must be two points share lines with other blocks' points. Is that a mistake? If it is true, how can that be efficient?
taz
@Abandon To answer your first question, I think the diagram is a little confusing. In the blocked data layout on the right, consecutive memory addresses are indicated by the blue line, so I don't think you have to do strange indexing tricks to get the data in the blocked format. I think the idea is just to assign blocks that are consistent with how the data is laid out. For example, if we had an array of 16 students and each array element was a pointer to that student's array of 36 homework scores, we want to assign blocks to be each student (like the right), instead of an assignment (like the left) that uses a few homework scores from a few different students, which isn't smart for caching.
boba
The block major layout can be easily implemented in CUDA by using thread and block id's to map threads to an element in that block and having threads in a block cooperatively load that block's elements into shared memory.
tkli
I agree with @boba that the block major layout is basically built-in to the CUDA implementation precisely because of the block/thread organizational hierarchy. However, if we are doing grid solver, this creates potentially confusing code to communicate between blocks.
If we are not using CUDA, we are not necessarily in trouble. Block-major layout will work well with power-of-2 side lengths because then we can do bit manipulations to map i,j to A[i,j]. If not, I believe it will involve some modular arithmetic, but as long as we write and use a good abstraction for this i.e. get(A,i,j) we can keep our code fairly clean and readable.
POTUS
Do the P1-16s on the left diagram refer to processors? Can someone explain what the blue arrows symbolize in this case?
Firephinx
@POTUS yes the P1-16s refer to processors. The blue arrows symbolize how the consecutive memory addresses are laid out. On the left, the memory is laid out in row major order so like arr[0][0] would be next to arr[0][1] and so on. However on the right, the memory is laid out in block-major order, so arr[0][0][0][6] would be adjacent to arr[0][0][1][1] where the first two indices represent the block and the next two indices represent the row and column inside the block.
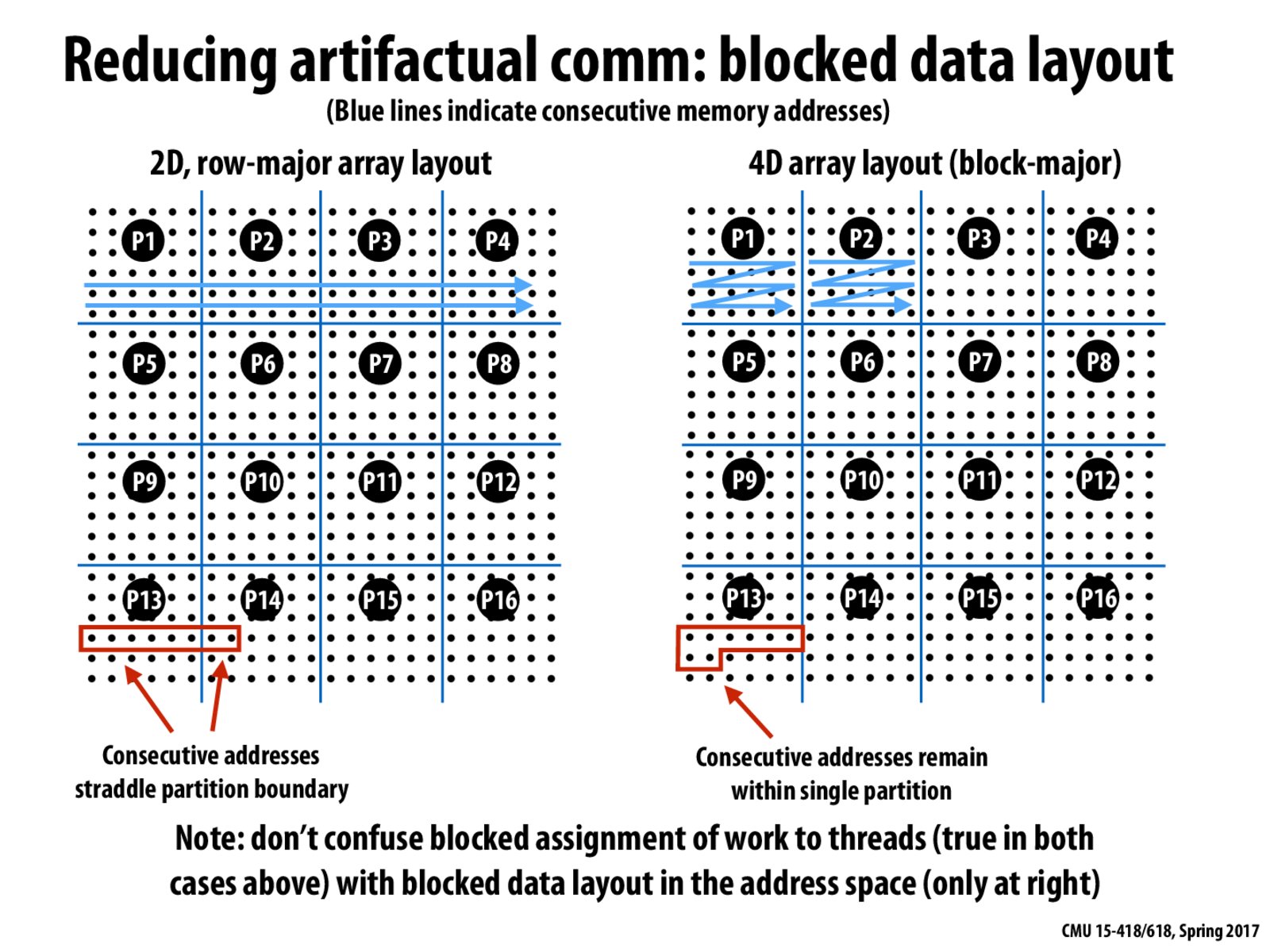
We usually assume row major format, but by making it into block-major format, we get perfect spatial locality because the addresses assigned to a thread are all consecutive. This leads to more efficient parallel code.
I am wondering, is it complicated to store the matrix in the manner of right? And if the red block in the picture is a cache line, then the first three lines of P13 cannot fit into the two cache lines and there must be two points share lines with other blocks' points. Is that a mistake? If it is true, how can that be efficient?
@Abandon To answer your first question, I think the diagram is a little confusing. In the blocked data layout on the right, consecutive memory addresses are indicated by the blue line, so I don't think you have to do strange indexing tricks to get the data in the blocked format. I think the idea is just to assign blocks that are consistent with how the data is laid out. For example, if we had an array of 16 students and each array element was a pointer to that student's array of 36 homework scores, we want to assign blocks to be each student (like the right), instead of an assignment (like the left) that uses a few homework scores from a few different students, which isn't smart for caching.
The block major layout can be easily implemented in CUDA by using thread and block id's to map threads to an element in that block and having threads in a block cooperatively load that block's elements into shared memory.
I agree with @boba that the block major layout is basically built-in to the CUDA implementation precisely because of the block/thread organizational hierarchy. However, if we are doing grid solver, this creates potentially confusing code to communicate between blocks.
If we are not using CUDA, we are not necessarily in trouble. Block-major layout will work well with power-of-2 side lengths because then we can do bit manipulations to map i,j to A[i,j]. If not, I believe it will involve some modular arithmetic, but as long as we write and use a good abstraction for this i.e. get(A,i,j) we can keep our code fairly clean and readable.
Do the P1-16s on the left diagram refer to processors? Can someone explain what the blue arrows symbolize in this case?
@POTUS yes the P1-16s refer to processors. The blue arrows symbolize how the consecutive memory addresses are laid out. On the left, the memory is laid out in row major order so like arr[0][0] would be next to arr[0][1] and so on. However on the right, the memory is laid out in block-major order, so arr[0][0][0][6] would be adjacent to arr[0][0][1][1] where the first two indices represent the block and the next two indices represent the row and column inside the block.