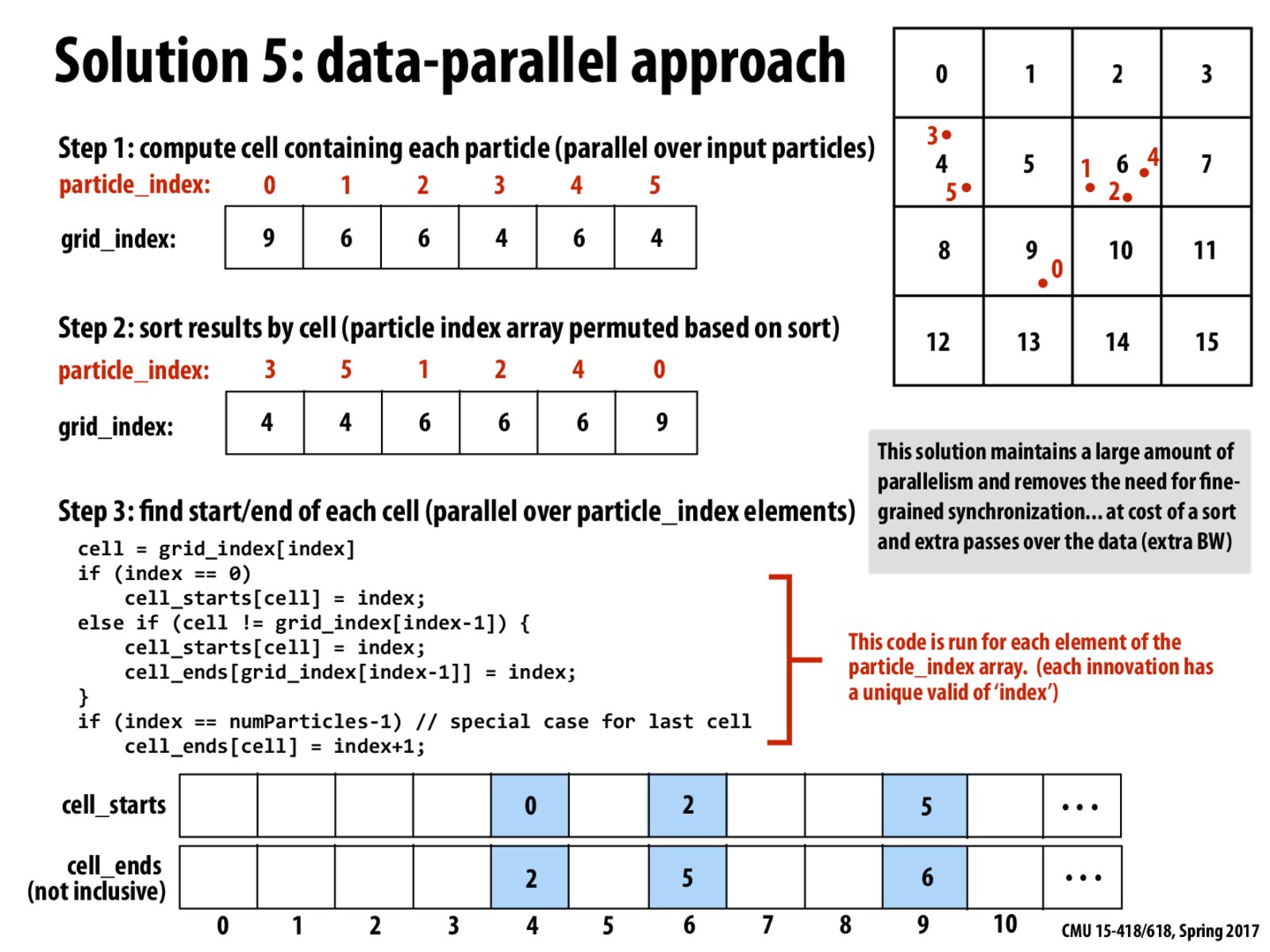
This approach for Step 3 is O(N) work and O(1) time!
tarabyte
When we say O(n) time, what exactly does that mean?
BigPapaChu
I'm confused about step 3. Do we run the kernel over the number of particles or the number of grid spaces?
apr
@BigPapaChu, I think you run step 3 over the particle_index elements. You can consider those elements as being tuples of the form (cell_index, particle_id.) For each of these elements, if you have access to the entire sorted array (wrt cell_index) of these tuples, then you can find out if this particular element is the first or last for this particular cell_index. This can be done in parallel for every element of this sorted array.
M12
For step three, you don't need the particle_index. Once we sort by grid index, we have clumped together all particles in the array of grid indices. We do run the kernel over the number of particles, but the indices in the grid_index array are grid indices. The number_of_particles is just len(grid_index).
For each particle, we calculate some of the grid-it-is-contained-in's number of particles by computing its the grid block's cell_starts and cell_ends.
Once all cell_starts and cell_ends are computed, you get the number of particles at grid position i, by doing cell_ends[i] - cell_starts[i].
Abandon
@tarabyte, it mean the time used by n elements is like "kn+b+..." where k,b is a constant and kn should be the dominate increase of the polynomial when n is increasing. You can refer to the wiki: https://en.wikipedia.org/wiki/Big_O_notation
shpeefps
Step 2 seems to be the bottleneck here. Is there a way to eliminate the need for a sort altogether?
ayy_lmao
@Abandon I think @tarabyte is saying that asymptotic analysis doesn't have as much meaning in this class, as there can be a huge range of speedup within the same class of functions due to parallelism and optimization techniques.
This approach for Step 3 is O(N) work and O(1) time!
When we say O(n) time, what exactly does that mean?
I'm confused about step 3. Do we run the kernel over the number of particles or the number of grid spaces?
@BigPapaChu, I think you run step 3 over the particle_index elements. You can consider those elements as being tuples of the form (cell_index, particle_id.) For each of these elements, if you have access to the entire sorted array (wrt cell_index) of these tuples, then you can find out if this particular element is the first or last for this particular cell_index. This can be done in parallel for every element of this sorted array.
For step three, you don't need the particle_index. Once we sort by grid index, we have clumped together all particles in the array of grid indices. We do run the kernel over the number of particles, but the indices in the grid_index array are grid indices. The number_of_particles is just len(grid_index).
For each particle, we calculate some of the grid-it-is-contained-in's number of particles by computing its the grid block's cell_starts and cell_ends.
Once all cell_starts and cell_ends are computed, you get the number of particles at grid position i, by doing cell_ends[i] - cell_starts[i].
@tarabyte, it mean the time used by n elements is like "kn+b+..." where k,b is a constant and kn should be the dominate increase of the polynomial when n is increasing. You can refer to the wiki: https://en.wikipedia.org/wiki/Big_O_notation
Step 2 seems to be the bottleneck here. Is there a way to eliminate the need for a sort altogether?
@Abandon I think @tarabyte is saying that asymptotic analysis doesn't have as much meaning in this class, as there can be a huge range of speedup within the same class of functions due to parallelism and optimization techniques.