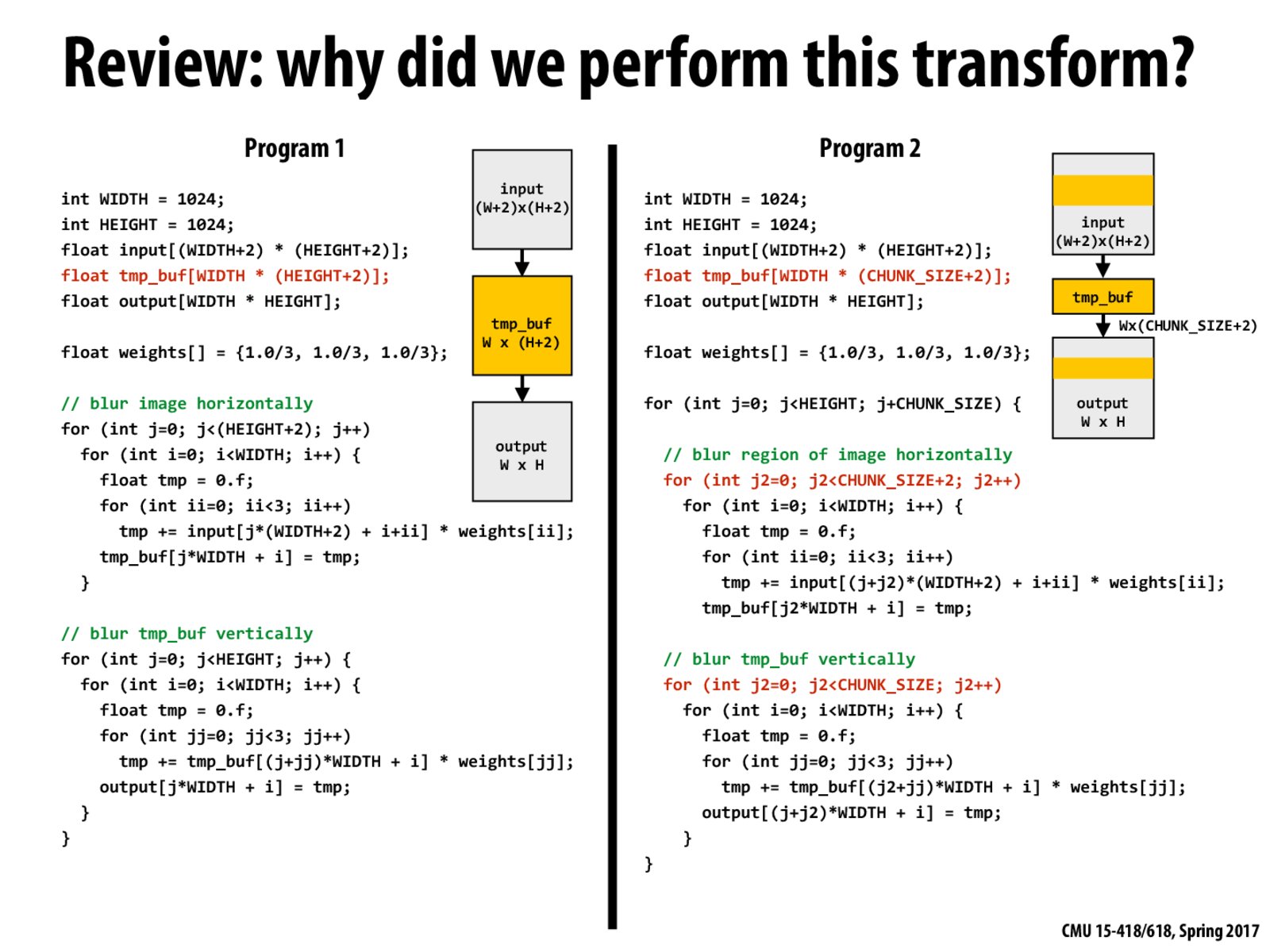
The working set of left version is of size Wx(H+2), while the working set of the right version is just Wx(CHUNKS_SIZE+2). Thus, for the left version, the working set can not fit in cache, while for the right version, we can always adjust the CHUNK_SIZE to make it fit in cache. That is the reason we choose the right version implementation.
paracon
The program on the right, reorders computation to improve producer-consumer locality.
hweetvpu
A note for the diagram in program 2. The first yellow block is of size (W+2)x(CHUNK_SIZE+2), which is then reduced horizontally to a tmp_buf of size Wx(CHUNK_SIZE+2), and then vertically to the yellow block of size WxCHUNK_SIZE. The fact that we use a "larger" for loop in program 2 makes locality much better than in program 1.
machine6
In a nutshell, program 2 performs better than program 1 due to the reordering of program structure such that we utilize cache locality to the maximum.
pdp
The central theme between previous and this slide is to re-use previously computed things as much as possible and reduce memory I/O.
srb
The general idea of producer-consumer locality is that something produced by one kernel being consumed immediately by the next kernel, so that data stays local instead of being committed to global memory, is optimal.
The working set of left version is of size Wx(H+2), while the working set of the right version is just Wx(CHUNKS_SIZE+2). Thus, for the left version, the working set can not fit in cache, while for the right version, we can always adjust the CHUNK_SIZE to make it fit in cache. That is the reason we choose the right version implementation.
The program on the right, reorders computation to improve producer-consumer locality.
A note for the diagram in program 2. The first yellow block is of size (W+2)x(CHUNK_SIZE+2), which is then reduced horizontally to a
tmp_bufof size Wx(CHUNK_SIZE+2), and then vertically to the yellow block of size WxCHUNK_SIZE. The fact that we use a "larger" for loop in program 2 makes locality much better than in program 1.In a nutshell, program 2 performs better than program 1 due to the reordering of program structure such that we utilize cache locality to the maximum.
The central theme between previous and this slide is to re-use previously computed things as much as possible and reduce memory I/O.
The general idea of producer-consumer locality is that something produced by one kernel being consumed immediately by the next kernel, so that data stays local instead of being committed to global memory, is optimal.