Because each node has its own disk, the message passing model allows nodes to share information in parallel without any issues that arise out of a shared memory model.
MichaelJordan
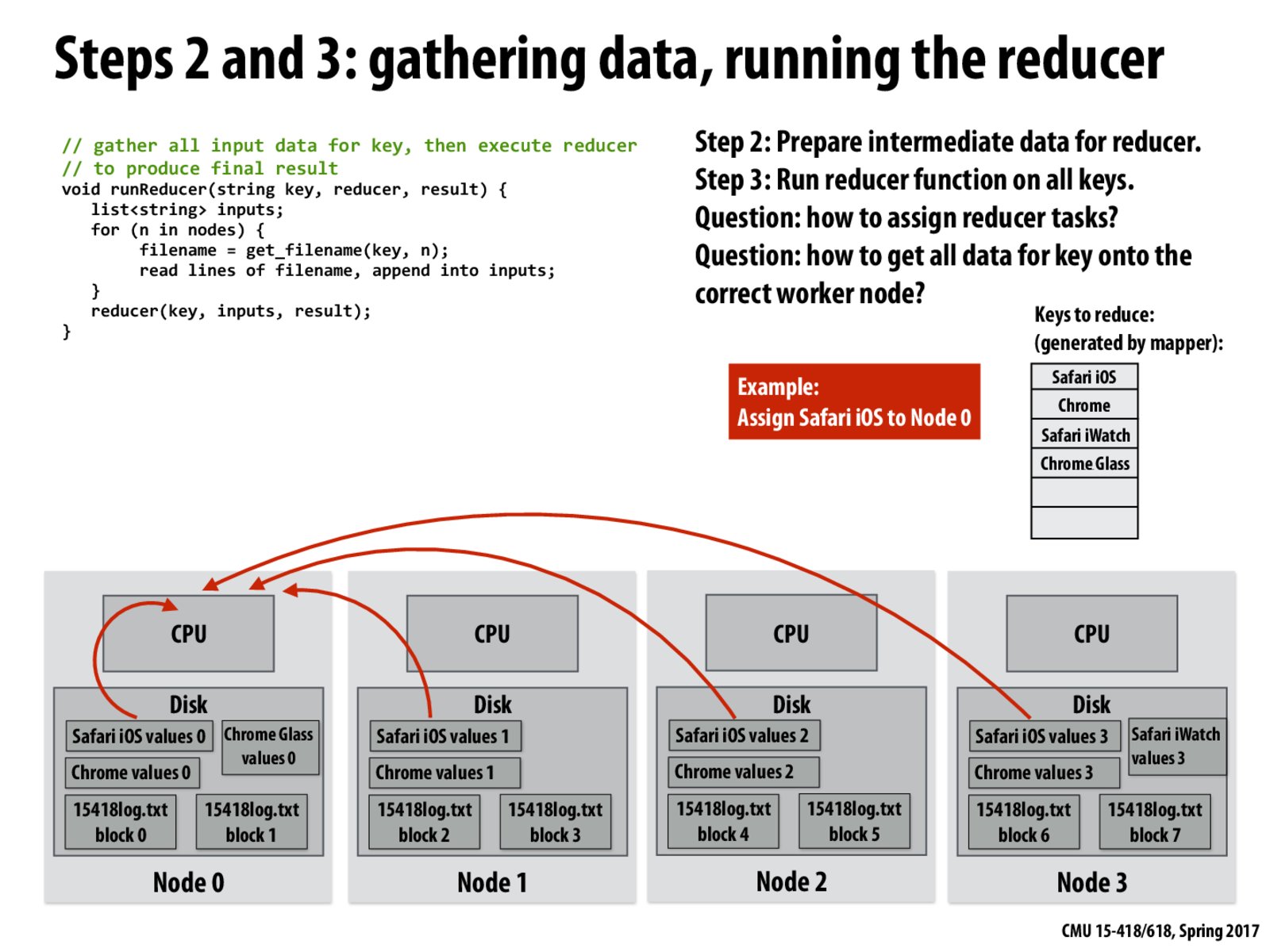
Is runReducer executed on each node? So each node computes a partial reduction per key (partially reduces Safari iOS, partially reduces Chrome, etc), and then sends them all to Node 0? Or are the Safari iOS keys from nodes 1,2,3 all sent over to Node 0 to be reduced by runReducer?
blah329
@MichaelJordan it seems that the function is run on every node. I believe this is the case since each node has a key assigned to it, as seen from the slide above with node 0, each node will read the files that pertain to the key assigned to it from other nodes, and will then run reduce to compute the result. This process can be parallelized by having the other nodes do the same thing with their assigned keys.
kayvonf
@MichaelJordan. As I defined it on slide 10, the application-provided function reducer takes a key, and a list of values sharing that key. It performs any computation on those inputs, producing a per-key output. That computation assumes it has the ability to access all the associated values throughout its execution.
Your suggestion of performing a partial reduction of per-key results locally on the generating node, and then communicating onto the partially reduced results to the node that combines them, is absolutely reasonable, but actually not a valid way to implement the definition of reducer that I just gave above since it constrains applications to use a reduces that is associative, so it can carry out the partial reductions in parallel. The interface definition does not provide the implementation that guarantee.
However, if it did, then it absolutely could have been implemented in the way you suggest. This alternatively interface definition would likely look like this (let's assume the per-key output is always an int:
The runtime could then use this applications provided function to carry out a parallel reduction as you suggest. Note that the reducer would also need to specify an identity value that result needs to be initialized to. (e.g., 0 in a sum reduction).
Therefore, in terms of Hadoop, I'm talking about a reducer. And you were thinking of an implementation that Hadoop referred to as a combiner.
jk2d
We might want to think about workload balance when distributing keys to different nodes. Simply uniformly assigning keys to nodes might result in bad workload balance.
pk267
How did we decide here that Safari iOS goes to Node - 1?
Because each node has its own disk, the message passing model allows nodes to share information in parallel without any issues that arise out of a shared memory model.
Is runReducer executed on each node? So each node computes a partial reduction per key (partially reduces Safari iOS, partially reduces Chrome, etc), and then sends them all to Node 0? Or are the Safari iOS keys from nodes 1,2,3 all sent over to Node 0 to be reduced by runReducer?
@MichaelJordan it seems that the function is run on every node. I believe this is the case since each node has a key assigned to it, as seen from the slide above with node 0, each node will read the files that pertain to the key assigned to it from other nodes, and will then run reduce to compute the result. This process can be parallelized by having the other nodes do the same thing with their assigned keys.
@MichaelJordan. As I defined it on slide 10, the application-provided function
reducertakes a key, and a list of values sharing that key. It performs any computation on those inputs, producing a per-key output. That computation assumes it has the ability to access all the associated values throughout its execution.Your suggestion of performing a partial reduction of per-key results locally on the generating node, and then communicating onto the partially reduced results to the node that combines them, is absolutely reasonable, but actually not a valid way to implement the definition of
reducerthat I just gave above since it constrains applications to use a reduces that is associative, so it can carry out the partial reductions in parallel. The interface definition does not provide the implementation that guarantee.However, if it did, then it absolutely could have been implemented in the way you suggest. This alternatively interface definition would likely look like this (let's assume the per-key output is always an int:
The runtime could then use this applications provided function to carry out a parallel reduction as you suggest. Note that the
reducerwould also need to specify an identity value thatresultneeds to be initialized to. (e.g., 0 in a sum reduction).Therefore, in terms of Hadoop, I'm talking about a reducer. And you were thinking of an implementation that Hadoop referred to as a combiner.
We might want to think about workload balance when distributing keys to different nodes. Simply uniformly assigning keys to nodes might result in bad workload balance.
How did we decide here that Safari iOS goes to Node - 1?