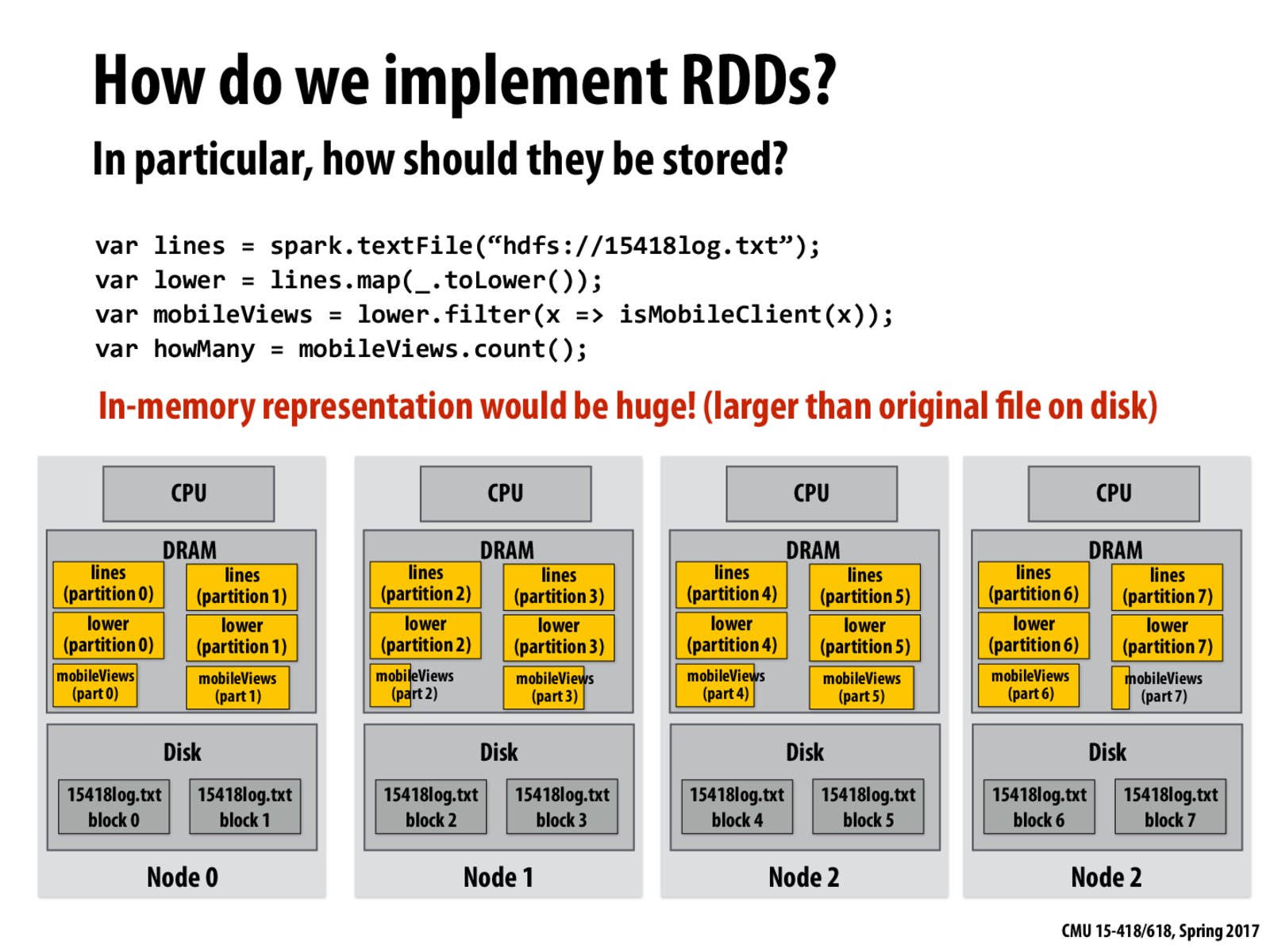
In-memory representation of RDDs would be huge if they were provided as an abstraction of arrays because arrays allow random access to different indices. The interface specified on slide 24 doesn't allow for such access patterns. Instead, the programmer can only access elements by these transformations on RDDs, so Spark doesn't need to make the entire RDD available in memory all the time.
Technically, array-like accesses are possible using rdd.filter((index) => index == 5), but unless the programmer makes length RDDs each with one element, this still allows Spark to limit the data stored in memory.
apadwekar
Spark avoids this memory overhead by simply streaming narrow dependencies (as if the programmer was iterating over the data line by line). However, wider dependencies do not benefit from streaming as all the data in a previous step must be computed for the next step in that case the RDDs are materialized requiring memory.
In-memory representation of RDDs would be huge if they were provided as an abstraction of arrays because arrays allow random access to different indices. The interface specified on slide 24 doesn't allow for such access patterns. Instead, the programmer can only access elements by these transformations on RDDs, so Spark doesn't need to make the entire RDD available in memory all the time.
Technically, array-like accesses are possible using
rdd.filter((index) => index == 5), but unless the programmer makeslengthRDDs each with one element, this still allows Spark to limit the data stored in memory.Spark avoids this memory overhead by simply streaming narrow dependencies (as if the programmer was iterating over the data line by line). However, wider dependencies do not benefit from streaming as all the data in a previous step must be computed for the next step in that case the RDDs are materialized requiring memory.