An interesting thing here is the difference between abstraction and implementation - the abstraction of spark is using these higher order operations on these sequence like data structures, but is implemented in a very serial, streaming way that does not do what the semantics of the program imply.
kayvonf
@rohany. Wait a minute here... the implementation of the Spark better do what the semantics of the programming model imply or we'd have big problems. Can you clarity what you meant here!
rohany
I might have not been very clear - from a functional point of view, it looks like we create alot of new collections of data that represent different transformations on the original sequence, but the implementation doesn't really do that.
kayvonf
And even more precisely: The implementation logically creates those collections. However its implementation chooses not to materialize their contents.
rohany
yeah - thats what I thought was really cool / clever about the spark implementation!
kayvonf
Note that Halide is another example of a compiler making sophisticated decisions about when logical collections are materialized.
lfragago
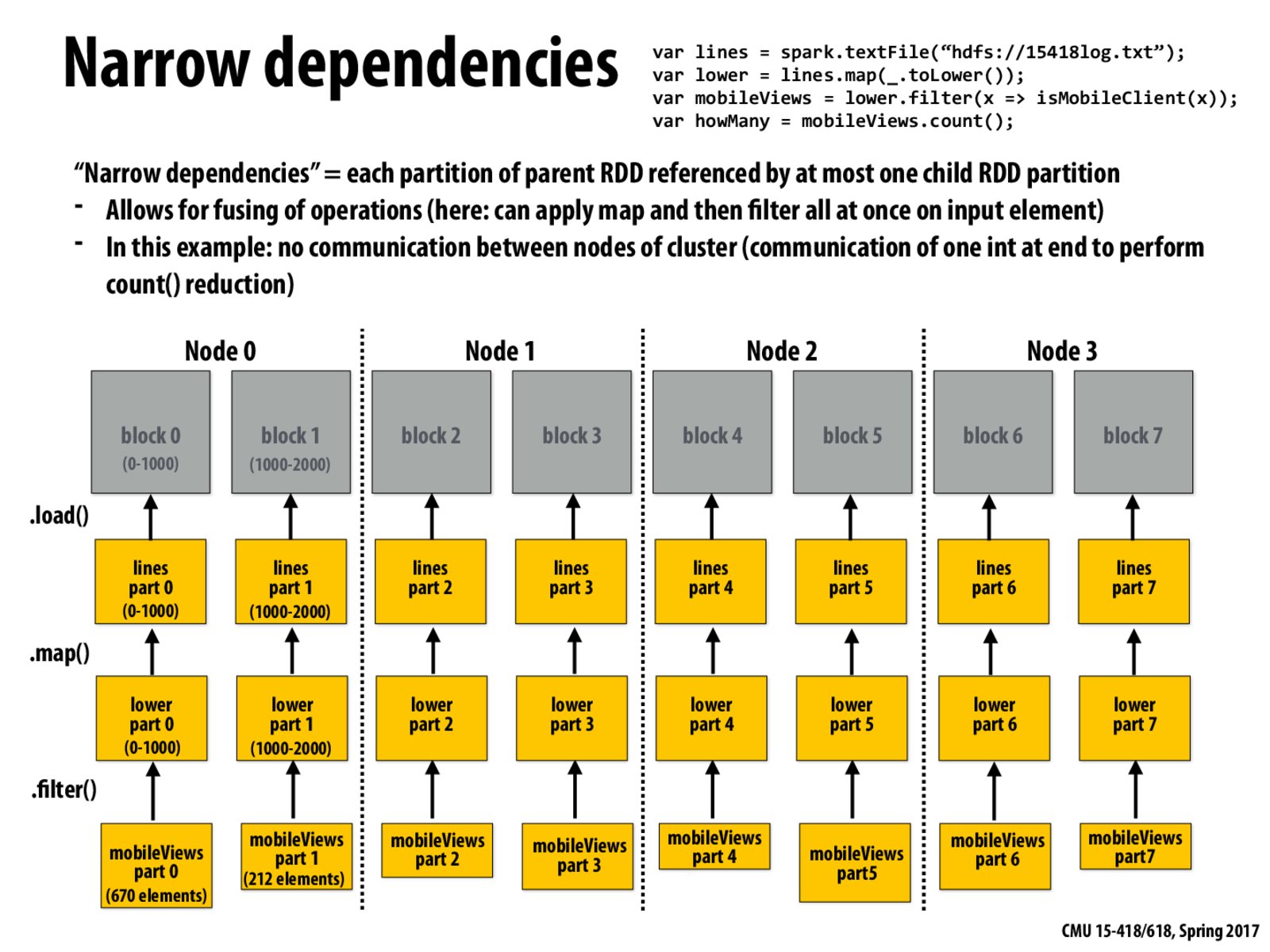
One very important point here is that when there are narrow dependencies, we can save a lot of communication costs, because (as seen in this example) the node becomes both producer and consumer of its own data.
An interesting thing here is the difference between abstraction and implementation - the abstraction of spark is using these higher order operations on these sequence like data structures, but is implemented in a very serial, streaming way that does not do what the semantics of the program imply.
@rohany. Wait a minute here... the implementation of the Spark better do what the semantics of the programming model imply or we'd have big problems. Can you clarity what you meant here!
I might have not been very clear - from a functional point of view, it looks like we create alot of new collections of data that represent different transformations on the original sequence, but the implementation doesn't really do that.
And even more precisely: The implementation logically creates those collections. However its implementation chooses not to materialize their contents.
yeah - thats what I thought was really cool / clever about the spark implementation!
Note that Halide is another example of a compiler making sophisticated decisions about when logical collections are materialized.
One very important point here is that when there are narrow dependencies, we can save a lot of communication costs, because (as seen in this example) the node becomes both producer and consumer of its own data.