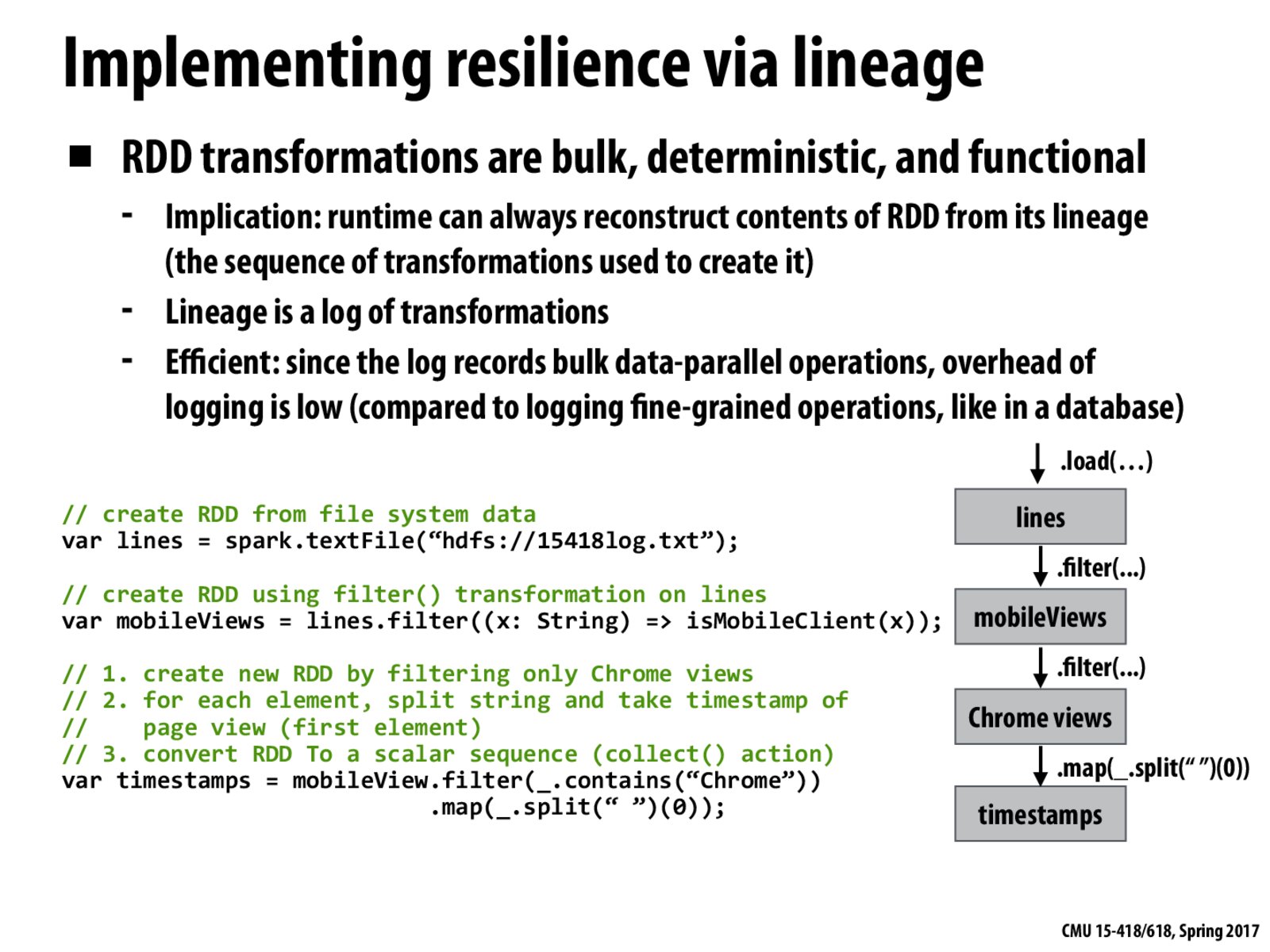
I don't quite understand why data-parallel operations requires much less logging than fine-grained operations like in a database. Could someone explain this in more detail?
metainf
I think it's because for fine-grained operations, you have to log each operation per element, which takes up O(n * m) space, where n is the number of elements and m is the different operations. For data-parallel operations, you only have to log the operation, which is O(m) because each operation is done to each element in the same order.
chenboy
In a database you need to maintain log for each UPDATE, INSERT, DELETE operations, which is often at tuple level. Whereas in Spark you only need keep load, filter, map and their parameters in the log, each of these coarse-grained operations manipulate a large amount of data. Assume that they are doing the same amount of computation, databases need to keep more information in the log.
sushi
Also, in database logging scheme, if physical logging is adopted, values of tuples needed to be copied into the log for the sake of fast recovery.
I don't quite understand why data-parallel operations requires much less logging than fine-grained operations like in a database. Could someone explain this in more detail?
I think it's because for fine-grained operations, you have to log each operation per element, which takes up O(n * m) space, where n is the number of elements and m is the different operations. For data-parallel operations, you only have to log the operation, which is O(m) because each operation is done to each element in the same order.
In a database you need to maintain log for each UPDATE, INSERT, DELETE operations, which is often at tuple level. Whereas in Spark you only need keep load, filter, map and their parameters in the log, each of these coarse-grained operations manipulate a large amount of data. Assume that they are doing the same amount of computation, databases need to keep more information in the log.
Also, in database logging scheme, if physical logging is adopted, values of tuples needed to be copied into the log for the sake of fast recovery.