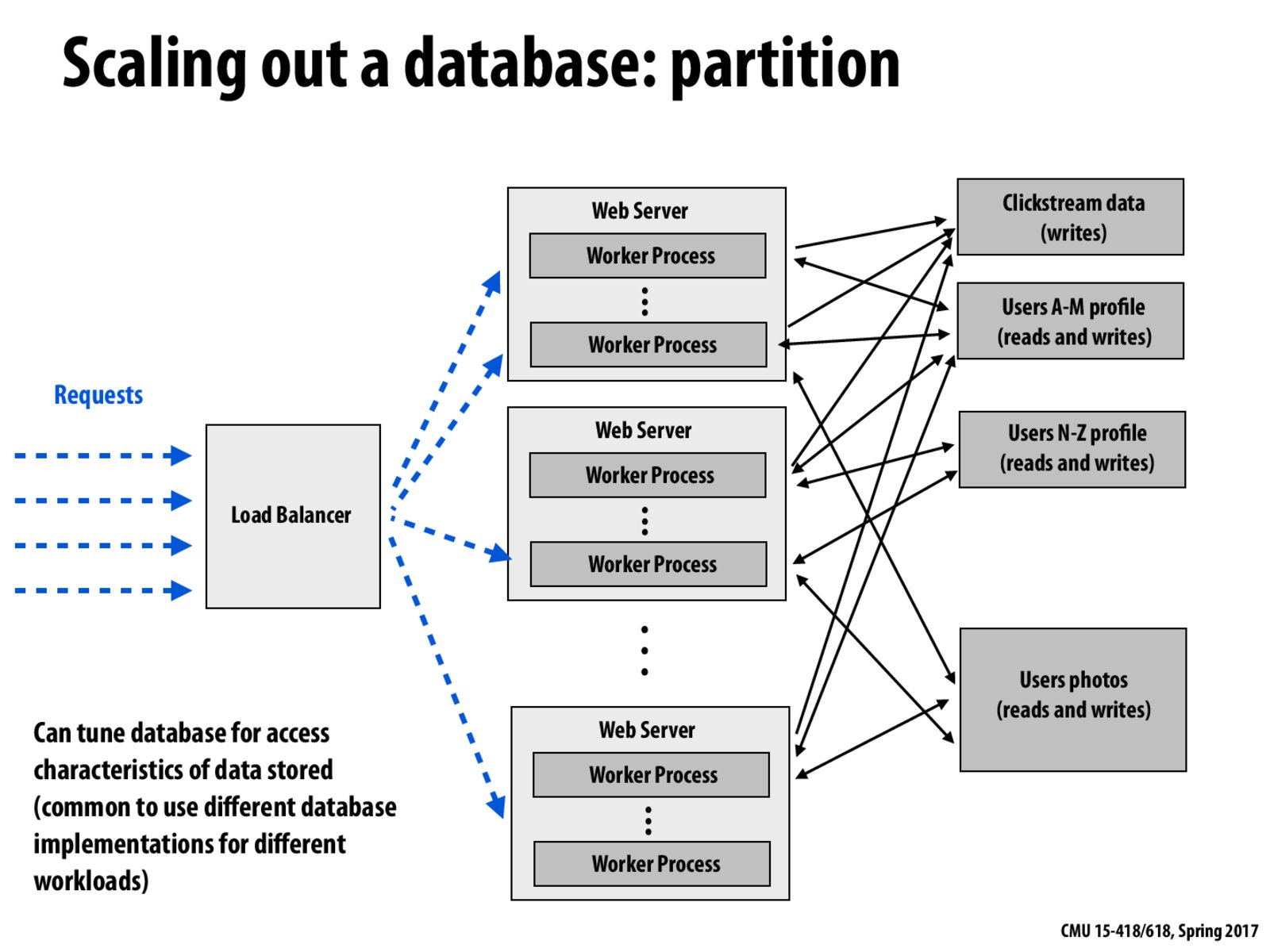
How does the database partitions dynamically adjust to different kinds of data characteristics?
dmerigou
One solution to adjust the partition dynamically is to use consistent hashing to assign data to storage nodes depending on the hash of the data. With this, adding or removing a storage node does not require the system to reassign all the data but just a reasonable fraction.
Also the partitioning here is called horizontal partitioning, since all the data related to one user is stored on the same node. Vertical partitioning consists in storing the name on one node, the adress on a second node, etc.
pk267
We can partition the data alphabetically, geographically or by hashing. The goal is to distribute the data uniformly. Hashing though divides uniformly gives poor locality*, and so geographical distribution is preferred over hashing-based distribution.
*Users in a given geographical region might be accessing similar data, for example youtube recommendations, images, web results etc.
zale
Wikimedia uses a combination of this architecture and the client/master system: Wikipedias are mapped to databases depending on their size (this is apparently fixed and doesn't change dynamically), and each such database has a master and several slaves.
This probably works well because the relative size of Wikipedias doesn't change quickly (hence no need for dynamic mapping), and reads are very significantly more frequent than writes.
vadtani
Summary for scaling out a database:
1. replication
2. specialization (e.g: user photos)
3. sharding (partitioning the database)
How does the database partitions dynamically adjust to different kinds of data characteristics?
One solution to adjust the partition dynamically is to use consistent hashing to assign data to storage nodes depending on the hash of the data. With this, adding or removing a storage node does not require the system to reassign all the data but just a reasonable fraction.
Also the partitioning here is called horizontal partitioning, since all the data related to one user is stored on the same node. Vertical partitioning consists in storing the name on one node, the adress on a second node, etc.
We can partition the data alphabetically, geographically or by hashing. The goal is to distribute the data uniformly. Hashing though divides uniformly gives poor locality*, and so geographical distribution is preferred over hashing-based distribution.
*Users in a given geographical region might be accessing similar data, for example youtube recommendations, images, web results etc.
Wikimedia uses a combination of this architecture and the client/master system: Wikipedias are mapped to databases depending on their size (this is apparently fixed and doesn't change dynamically), and each such database has a master and several slaves.
This probably works well because the relative size of Wikipedias doesn't change quickly (hence no need for dynamic mapping), and reads are very significantly more frequent than writes.
Summary for scaling out a database: 1. replication 2. specialization (e.g: user photos) 3. sharding (partitioning the database)